深度學習大牛權威預測2024年AI行業熱點,盤點開源AI趨勢!
知名人工智能研究人員SEBASTIAN RASCHKA在進入2023年尾聲的時候,對幾年行業的發展進行了一個全面的回顧。
在他看來,雖然今年以大語言模型為代表的AI行業風起云涌,新產品新技術不斷推出,高光頻現。
但是伴隨著技術的發展,也有更多的問題出現,亟待解決。

文章鏈接:
https://magazine.sebastianraschka.com/p/ai-and-open-source-in-2023
2023年:只是2022年高潮的延續?
今年,人們還沒有看到人工智能產品方面有任何根本性的新技術或方法出現。相反,今年主要產品和更新都是去年基礎的延續:
ChatGPT從GPT-3.5升級到GPT-4
DALL·E 2 升級為 DALL·E 3
Stable Diffusion 2.0升級為 Stable Diffusion XL
而一個一直被多方炒作的傳聞很有意思:GPT-4是由16個子模塊組成的專家(MoE)模型的混合體。
而且據說,這16個子模塊中的每一個MoE都有1110億個參數(作為參考,GPT-3有1750億個參數)。

盡管不能100%確定,但GPT-4是一個MoE組成的集群這個事很可能是真的。
從這個事情上,看得出的一個趨勢是,AI行業的研究人員在論文中分享的信息現在已經越來越少。
例如,GPT-1、GPT-2、GPT-3 和Instruct GPT論文披露了具體的架構和訓練細節,而GPT-4架構就沒有人知道了。
再舉個例子:Meta AI的第一篇Llama論文詳細介紹了用于訓練模型的訓練數據集,而 Llama 2模型則對這些信息都進行了保密。
在大模型透明度方面,斯坦福大學上周推出了 「基礎模型透明度指數」(The Foundation Model Transparency Index),根據該指數,Llama 2以54%領先,GPT-4以48%排名第三。
當然,要求企業分享商業機密可能并不合理。但這仍然是一個值得一提的很有意思的一個趨勢。
因為,2024年這個趨勢似乎不會改變。
關于技術的進一步發展,今年的另一個趨勢是輸入上下文的長度一直在增長。
例如,GPT-4的競爭對手Claude 2的主要賣點之一就是它支持多達100k token的輸入(GPT-4 目前只支持32k的上下文),這使得它在生成長文檔摘要時特別有吸引力。
它還支持PDF輸入,因此對于很多人的工作也特別有用。

開源AI趨勢總結
根據作者的記憶,去年開源社區非常關注隱擴散模型(Latent Diffusion Model如穩定擴散模型)和其他計算機視覺模型。
擴散模型和計算機視覺一如既往地具有現實意義。不過,今年開源和學界、關注的焦點成為了LLM。
開源(或者說公開可用)LLM的爆炸式增長部分要歸功于Meta公司發布的首個預訓練Llama,盡管該模型的許可證具有限制性,但還是激勵了許多研究人員和從業人員投入和很多時間和精力,導致了后來的羊駝大爆發:Alpaca,Vicuna,Llama-Adapter,Lit-Llama等變體的出現。
幾個月后,Llama 2在很大程度上取代了Llama 1,成為功能更強的基礎模型,甚至官方還推出了其他的微調版本。
然而,盡管 Llama-Adapter v1 和 Llama-Adapter v2等微調方法有望將現有 LLM變成多模態LLM,但大多數開源LLM仍然是純文本模型。

另外一個值得注意的模型是于 10 月 17 日發布的Fuyu-8B模型。
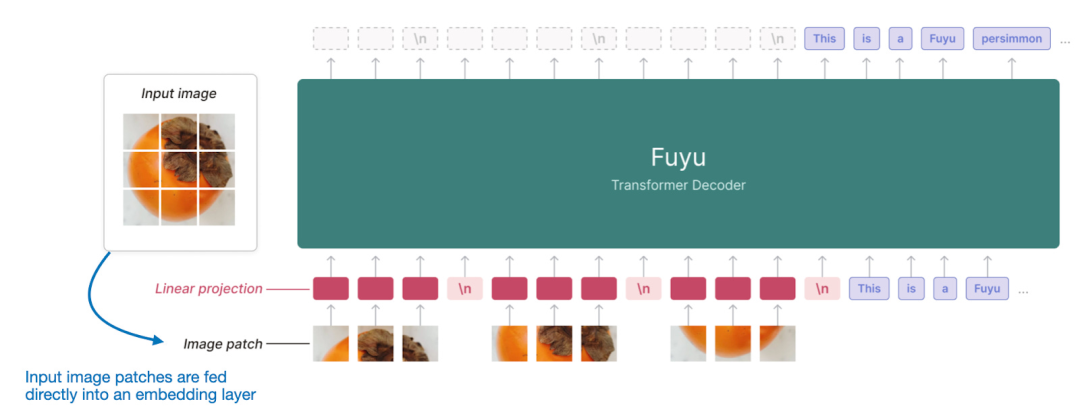
值得注意的是,Fuyu-8B將輸入片段直接傳入線性投影層(或嵌入層),以學習自己的圖像片段嵌入,而不是像其他模型和方法(例如 LLaVA 和 MiniGPT-V)那樣依賴額外的預訓練圖像編碼器。
這種方式大大簡化了架構和訓練設置。
除了上述幾種多模態嘗試之外,最大的研究熱點仍然是使用參數小于100 B的較小模型來追求達到GPT-4級別的文本性能。
開源社區進行類似嘗試的原因,可能是由于硬件資源成本和限制、有限的數據訪問以及對較短開發時間的要求(由于發表論文的壓力,大多數研究人員無法花費數年時間來訓練一個模型)。
不過,開源LLM的下一個突破并不一定來自將模型擴展到更大的規模。
2024年,MoE方法能否將開源模型提升到新的高度,讓我們拭目以待。
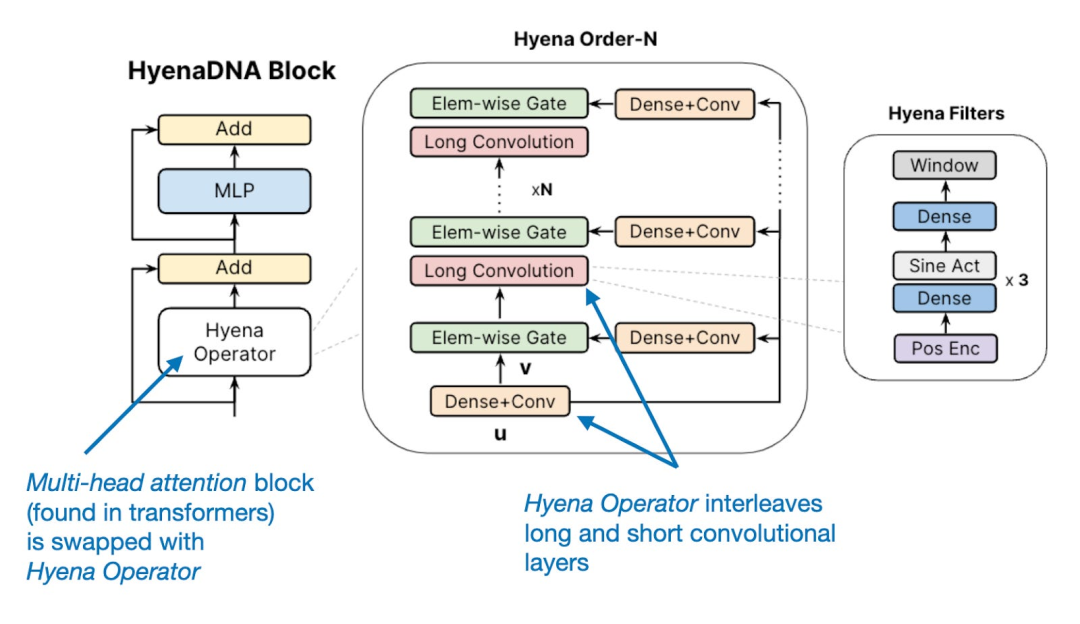
有趣的是,在研究方面,大家在2023年還看到了一些基于Transformer的LLM 的替代方案,包括旨在提高效率的遞歸RWKV LLM和卷積Hyena LLM。
不過,基于Transformer的LLM仍然是當前的主流技術。
總的來說,開源社區在這一年里非常活躍,取得了許多突破和進步。
而且開源社區的一大特點就是1+1>2。
因此,作者對積極游說反對開源人工智能的人感到難過。
作者希望開源社區能保持積極的勢頭,建立更有效的解決方案和替代產品,而不是一味地依賴大型科技公司發布的類似ChatGPT這樣的產品。
由于開源社區的不斷努力,出現了可以在單個GPU上運行的小型高效模型,如1.3B參數的phi1.5、7B Mistral和7B Zephyr,其性能已接近大型閉源模型。
這是一個令人興奮的趨勢,作者希望這一趨勢能在2024年繼續下去。
生產力期望
作者認為開源人工智能是開發高效和定制化的LLM解決方案的主要途徑,包括那種可以適用于各種應用,基于個人或特定領域數據的微調LLM。
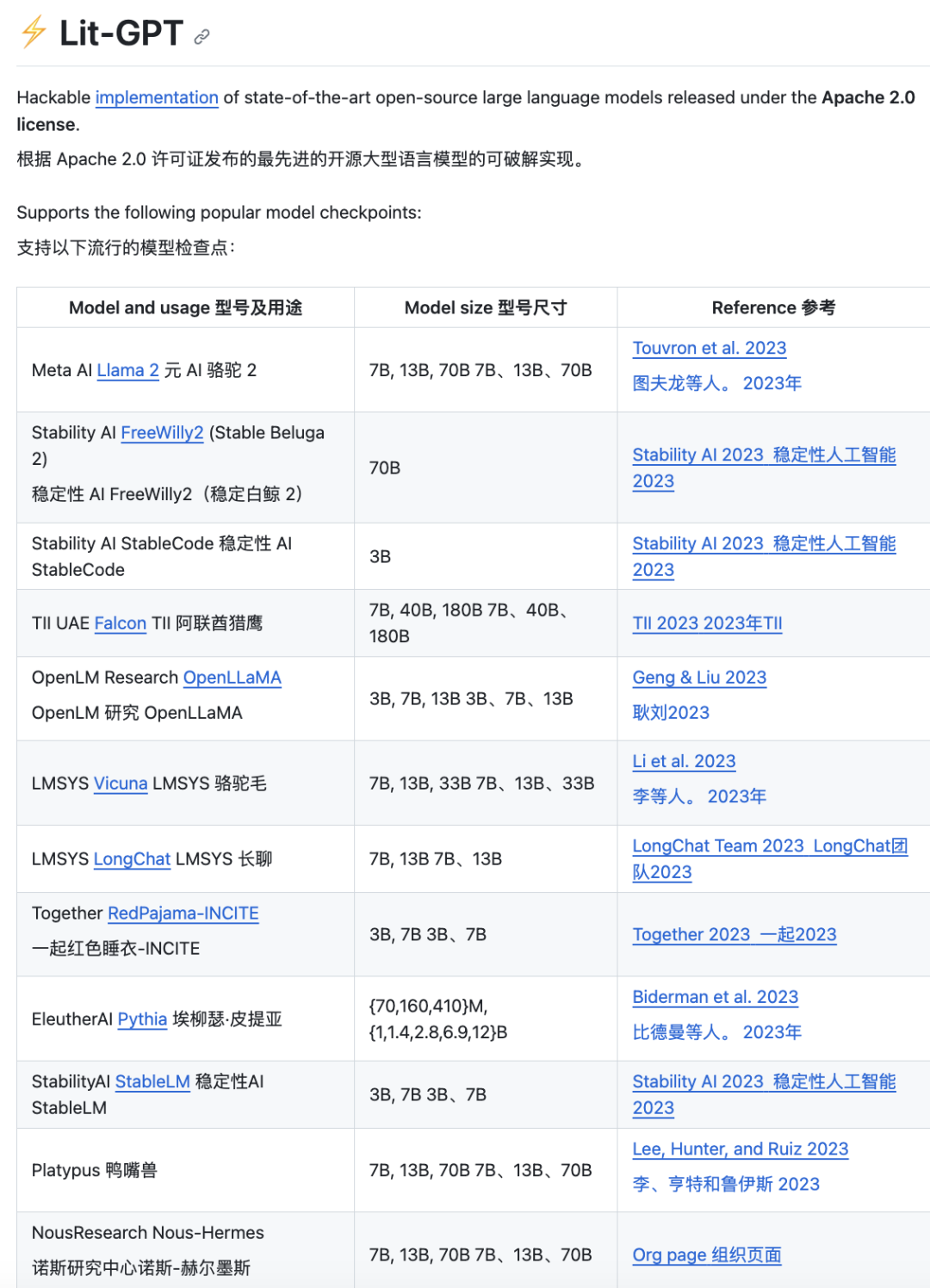
如果在社交媒體上關注過作者本人的話,可能會看到他在談論和不斷改善的Lit-GPT,這是作者積極參與的一個LLM開源資源庫。
雖然作者本人非常支持開源,但他也非常喜歡精心設計的產品。
自從ChatGPT發布以來,LLM被用于幾乎所有領域。
而正確使用LLM助手能讓你事半功倍。
例如,向ChatGPT詢問雜貨店的營業時間就不是一個發揮它功能長處的用法。但是,修改文章的語法,或者進行頭腦風暴,重新遣詞造句。
從更宏觀的角度看,LLM的核心能力是提高工作效率,這一點每個人都不會否認。
除了用于普通文本的LLM,微軟和GitHub推出的Copilot代碼助手也日趨成熟,越來越多的人開始使用它。
今年早些時候,Ark-Invest 的一份報告估計,代碼助手能將完成一項編碼任務的時間縮短約55%。
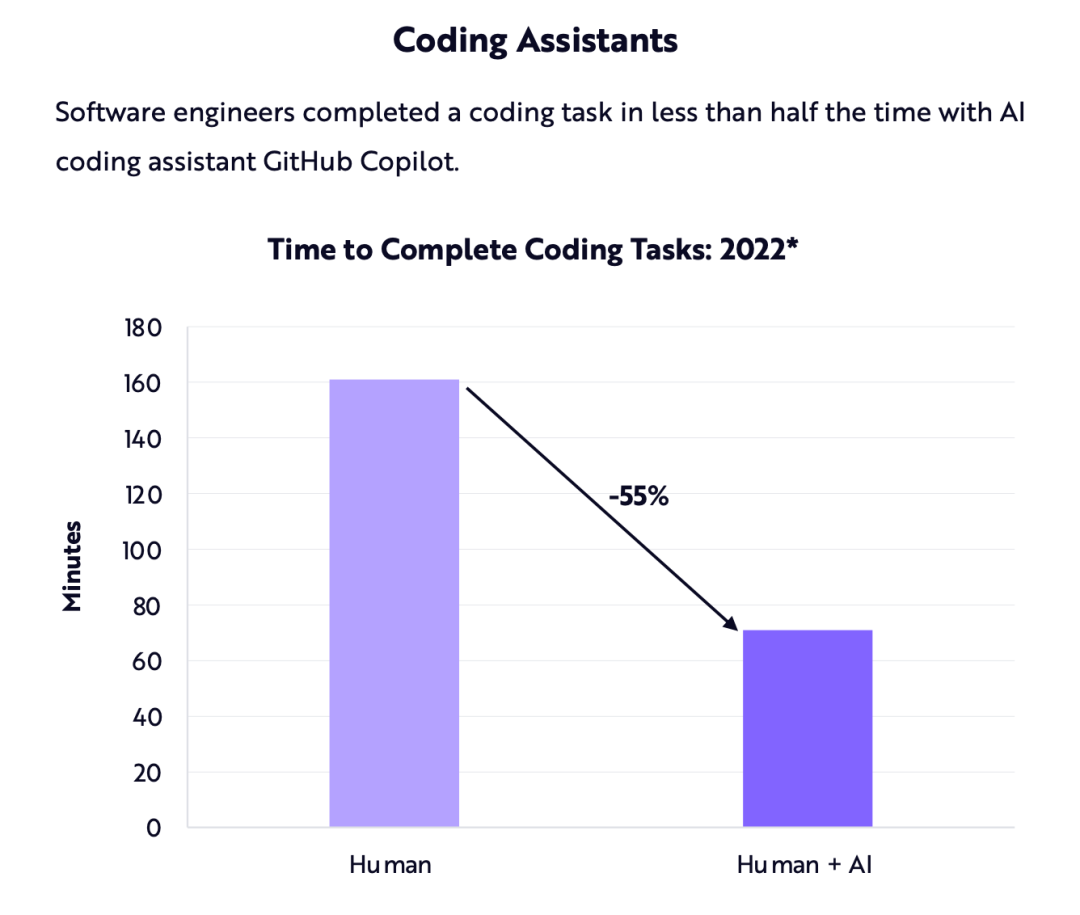
不過,不論55%這個數字是否真的那么準確,只要用過代碼助手,任何人都能感受到效率的巨大提升,可以讓繁瑣的代碼任務變得更輕松。
有一點是肯定的:代碼助手將繼續存在,而且隨著時間的推移,它們只會變得越來越好用。
它們會取代人類程序員嗎?作者希望不會。但毫無疑問,它們將提高現有程序員的工作效率。
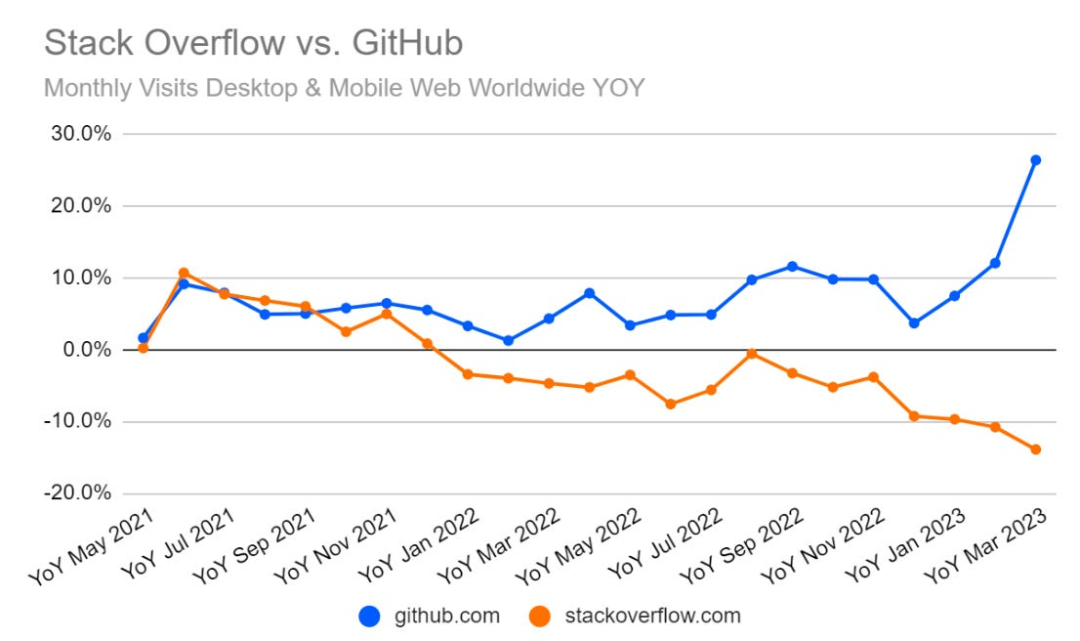
這對StackOverflow意味著什么?《人工智能現狀報告》中有一張圖表,顯示了StackOverflow 與 GitHub 的網站流量對比,這可能與Copilot的使用率越來越高有關。
不過,作者認為即使是ChatGPT/GPT-4已經對代碼相關的任務很有幫助了。
可能ChatGPT也是導致StackOverflow流量下降的部分原因(甚至是主要原因)。
AI行業面對的幾大問題
幻覺
與2022年一樣,同樣的問題仍然困擾著LLM:他們可能會生成有毒內容,并傾向于產生幻覺。
在這一年中,出現多種解決這一問題的方法,包括帶有人類反饋的強化學習(RLHF)和英偉達提出的NeMO Guardrails。
然而,這些方法仍然解決不了根本問題,要么過于嚴格,要么效果不好。

項目地址:https://github.com/NVIDIA/NeMo-Guardrails
到目前為止,還沒有一種方法(甚至連設計可行方法的思路都沒有)能在不削弱LLM的積極功能的基礎之上,能百分之百可靠地解決這個問題。
在作者看來,這一切都取決于人類如何使用 LLM:不要什么事都用LLM,數學用計算器,把LLM只看做是寫作工具,并仔細檢查它的輸出,等等。
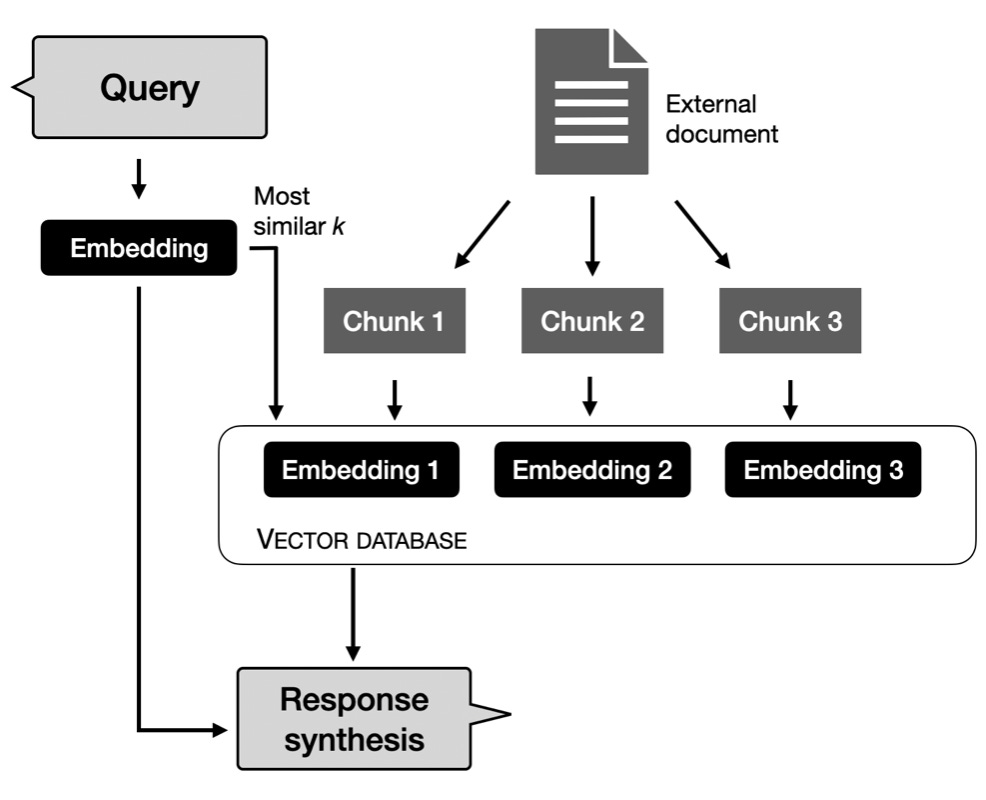
此外,對于特定的商業應用,也許可以探索檢索增強(RAG)系統。
它作為一種折中方案,開發人員從語料庫中檢索相關的文檔段落,然后根據檢索到的內容為基礎, 為LLM的文本生成設定條件。
這種方法能讓模型從數據庫和文檔中獲取外部信息,而不是依賴于記憶所有知識和信息。
版權問題
另一個更緊迫的問題,是圍繞人工智能的版權爭論。
根據維基百科的說法,「在受版權保護的材料上訓練出來的LLM的版權問題尚未解決」。
總體看來,許多規則仍在起草和修訂之中。作者希望,無論規則是什么,都能清晰明了,以便人工智能研究人員和從業人員能夠做出相應的調整和行動。
評估
困擾學術研究的一個問題是,流行的基準和排行榜被基本上都是半成品,因為測試集內容可能已經泄露,成為了LLM 的訓練數據。這已經成為 phi-1.5 和 Mistral的一個問題。
自動評估 LLM 的一個常用但不太方便的方法是以人類的偏好為測評標準。另外,許多論文也將 GPT-4作為第二好的方法。
收入
生成式人工智能目前仍處于初期探索階段。
當然,大語言模型和文生圖模型已經在很多領域非常好用了。
然而,由于昂貴的托管和運行成本,它們能否為公司賺錢仍是一個備受爭議的話題。
例如,據報道,OpenAI去年虧損了5.4億美元。另一方面,最近有報道稱,OpenAI現在每月能賺到8000萬美元,已經抵消它的運營成本。
虛假圖像
與生成式人工智能有關的一個大問題是偽造圖像和視頻的問題,這在目前的社交媒體平臺上尤為明顯。
偽造圖片和視頻一直是個問題,Photoshop等軟件已經降低了偽造內容的門檻,人工智能正在將這一問題提升到一個新的水平。
也有人工智能系統希望能在檢測人工智能生成的內容方面產生作用,但這些系統對文本、圖像或視頻都不可靠。
要在一定程度上遏制和打擊這些問題,唯一的辦法就是依靠值得信賴的專家。
就像我們不會從互聯網上的隨機論壇或網站上獲取醫療或法律建議一樣,我們可能也不應該在沒有反復核實的情況下相信互聯網上隨機賬號的圖片和視頻。
數據集瓶頸
與前面提到的版權爭論有關,許多公司(包括 Twitter/X 和 Reddit)關閉了免費API訪問權限,以增加收入,同時也是為了防止搜刮者收集平臺數據用于人工智能訓練。
我遇到過許多專門從事數據集相關工作的公司的廣告。雖然人工智能可能會令人遺憾地導致某些工作自動化,淘汰人類勞動力,但它似乎同時也在創造新的就業機會。
為開源LLM進步做出貢獻的最佳方式之一,可能就是建立一個數據集眾包平臺,來撰寫、收集和整理經明確許可用于LLM培訓的數據集。
RLHF是蛋糕上的櫻桃嗎?
當Llama 2模型套件發布時,它包含了針對聊天進行微調的模型。Meta AI 使用強化學習與人類反饋 (RLHF),提高了其模型的有用性和無害性。
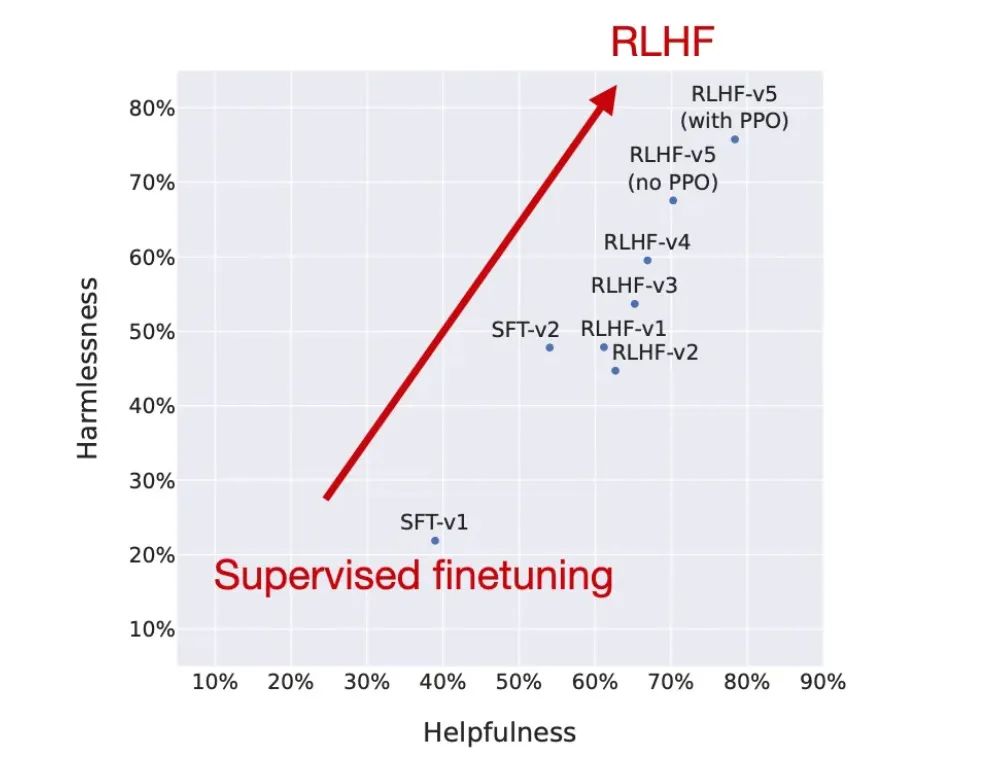
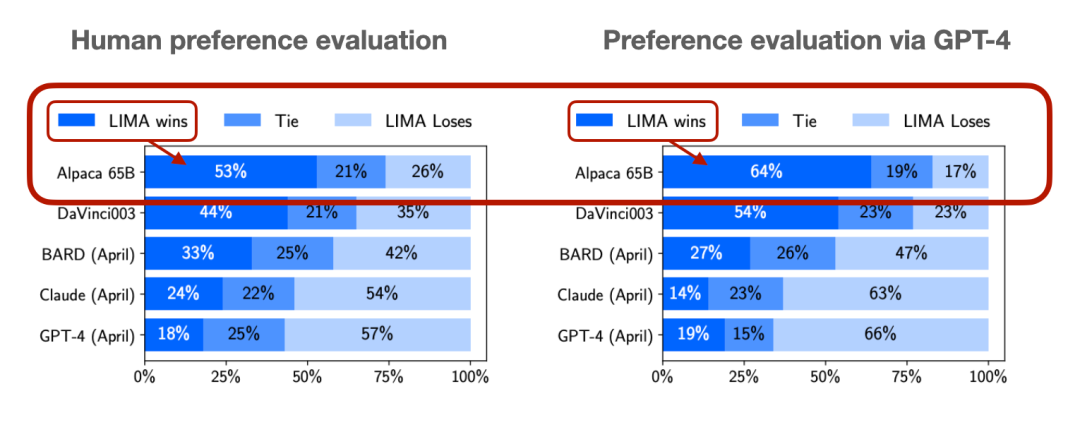
作者認為RLHF是一種非常有趣且有前途的方法,但除了InstructGPT、ChatGPT和Llama 2之外,它并沒有被廣泛使用。下圖是一張關于RLHF日益普及的圖表。
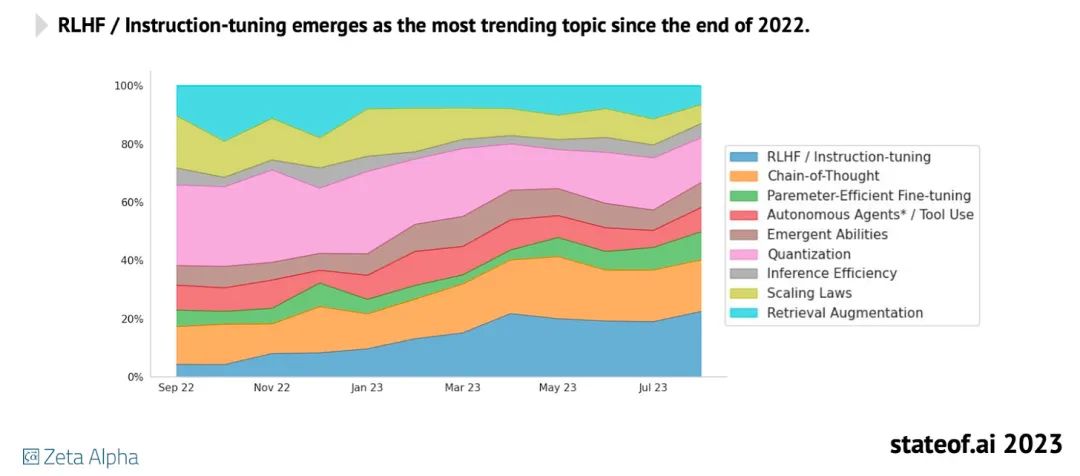
由于 RLHF 的實現有點復雜和棘手,因此大多數開源項目仍然專注于指令微調的監督微調。
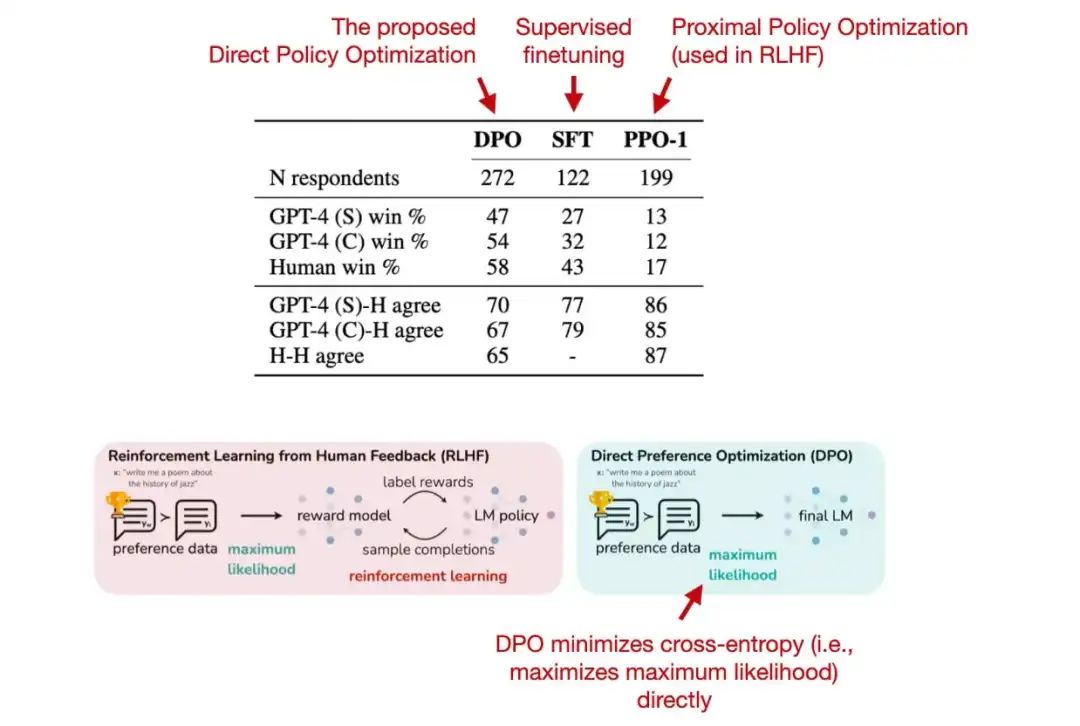
RLHF 的最新替代方案是直接偏好優化 (DPO)。在相應的論文中,研究人員表明,在RLHF中擬合獎勵模型的交叉熵損失可以直接用于微調LLM。
根據他們的基準,使用 DPO 更有效,并且在響應質量方面通常也優于 RLHF/PPO。
DPO似乎尚未被廣泛使用。然而,不久前,我們看到了通過DPO訓練的第一個公開可用的LLM,它似乎優于通過 RLHF 訓練的更大的Llama-2 70b Chat模型:
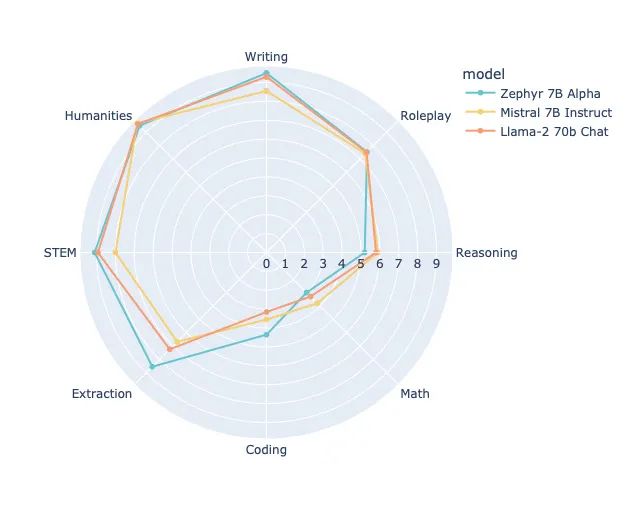
但是,值得注意的是,RLHF并未明確用于優化基準性能;它的主要優化目標是人類用戶評估的「有用性」和「無害性」,這里沒有捕捉到這一點。
使用LLM做分類?
不久前,作者在Packt 生成式 AI 會議上發表了演講,強調文本模型最突出的用例之一仍然是分類。例如,考慮一些常見的任務,例如垃圾郵件分類、文檔分類、對客戶評論進行分類,以及在社交媒體上標記有害言論。
而對于這些任務,僅使用單個 GPU 運行「小型」LLM(例如DistilBERT)就足以獲得非常好的分類性能。
今年,作者在他的深度學習基礎課程中發布了使用小型LLM進行文本分類的練習,有人甚至通過微調現成的可用 Roberta模型,在IMDB電影評論數據集上實現了>96%的預測準確率。
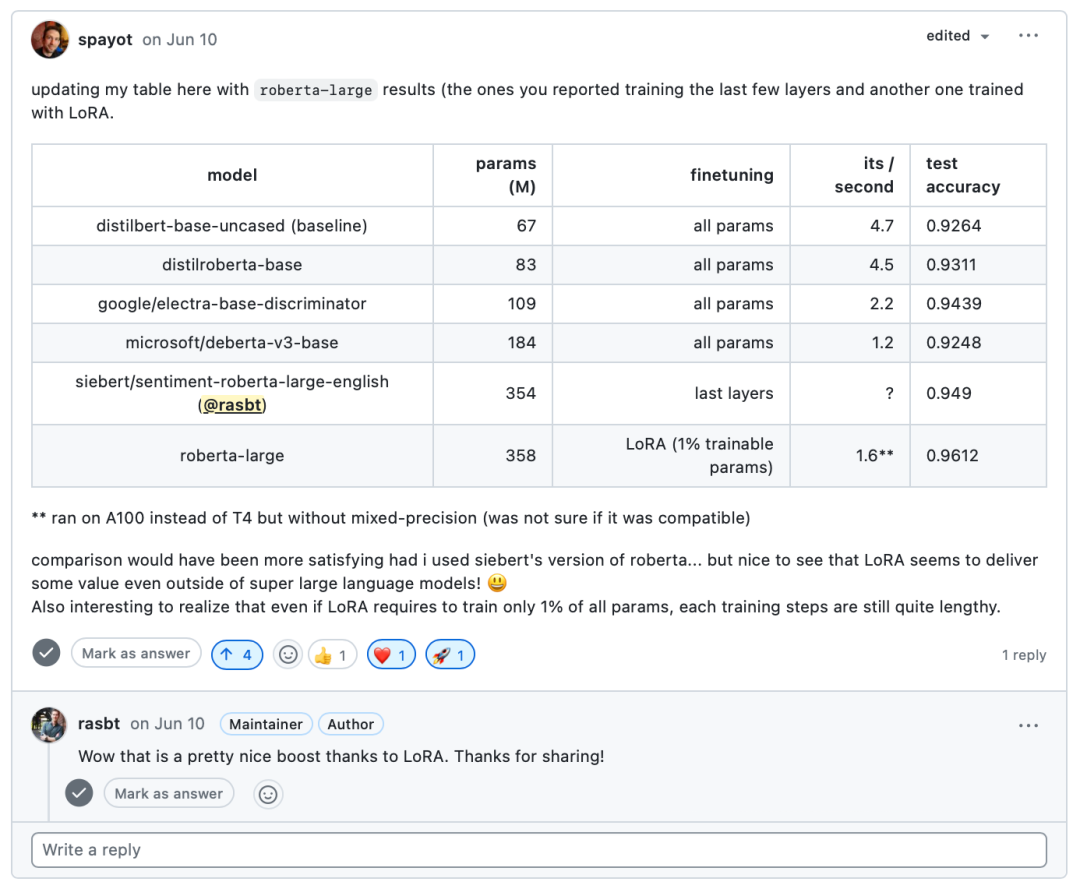
話雖如此,目前卻仍然沒有看到任何關于LLM分類的新的主要工作或趨勢。大多數從業者仍在使用基于 BERT 的編碼器模型或編碼器-解碼器模型,例如2022年問世的 FLAN-T5。這可能是因為這些架構仍然在各項任務中表現良好。
LLM用于表格數據
2022 年,作者撰寫了《 A Short Chronology Of Deep Learning For Tabular Data》,介紹了許多有趣的基于深度學習的表格數據方法。然而,與上面提到的用于分類的 LLM 類似,在表格數據集方面也沒有那么多的發展。
2022 年,Grinsztajn 等人撰寫了一篇論文,題為《Why do tree-based models still outperform deep learning on tabular data?》。確實,基于樹的模型(隨機森林和 XGBoost)在中小型數據集(10k個訓練示例)上的表格數據方面仍然優于深度學習方法。
此外,XGBoost又推出了一個大型 2.0 版本,該版本具有更好的內存效率、對不適合內存的大型數據集的支持、多目標樹等。
2023 年的計算機視覺
大型語言模型開發(LLM)開發仍在快速進行。與此同時,撇開人工智能監管的爭論不談,LLM新聞的出現速度似乎比平時略慢。這是一個很好的機會,可以偶爾關注計算機視覺,討論該領域的研究和開發現狀。
除了研究之外,與計算機視覺相關的人工智能一直在激發今年已經成熟的新產品和體驗。
例如,今年夏天,第一輛真正的無人駕駛Waymo汽車在街上漫游。

以及,人工智能的使用在電影行業越來越受歡迎。最近的一個例子是哈里森·福特(Harrison Ford)在《奪寶奇兵5》中的去衰老,電影制片人使用演員的舊檔案材料訓練了人工智能。
然后,生成式人工智能功能現在已經牢固地集成到流行的軟件產品中。最近的一個例子是 Adobe 的 Firefly 2。
2024 年的預測
預測始終是最具投機性和挑戰性的方面。去年,作者預測LLM在文本或代碼以外的領域中會有更多應用。
其中一個例子是HyenaDNA,它是DNA的LLM。另一個Geneformer,這是一個在3000萬個單細胞轉錄組上預訓練的transformer,旨在促進網絡生物學的預測。
到2024年,LLM將越來越多地改變計算機科學之外的STEM研究。
一個新興趨勢是各種公司開發定制 AI 芯片,這是由于高需求導致的GPU稀缺。谷歌將在其TPU硬件上加倍投入,亞馬遜已經推出了Trainium芯片,AMD可能會縮小與NVIDIA的差距。現在,Microsoft 和OpenAI也開始開發自己的定制 AI 芯片。
這方面的挑戰在于,確保在主要的深度學習框架中對這種硬件提供全面而強大的支持。
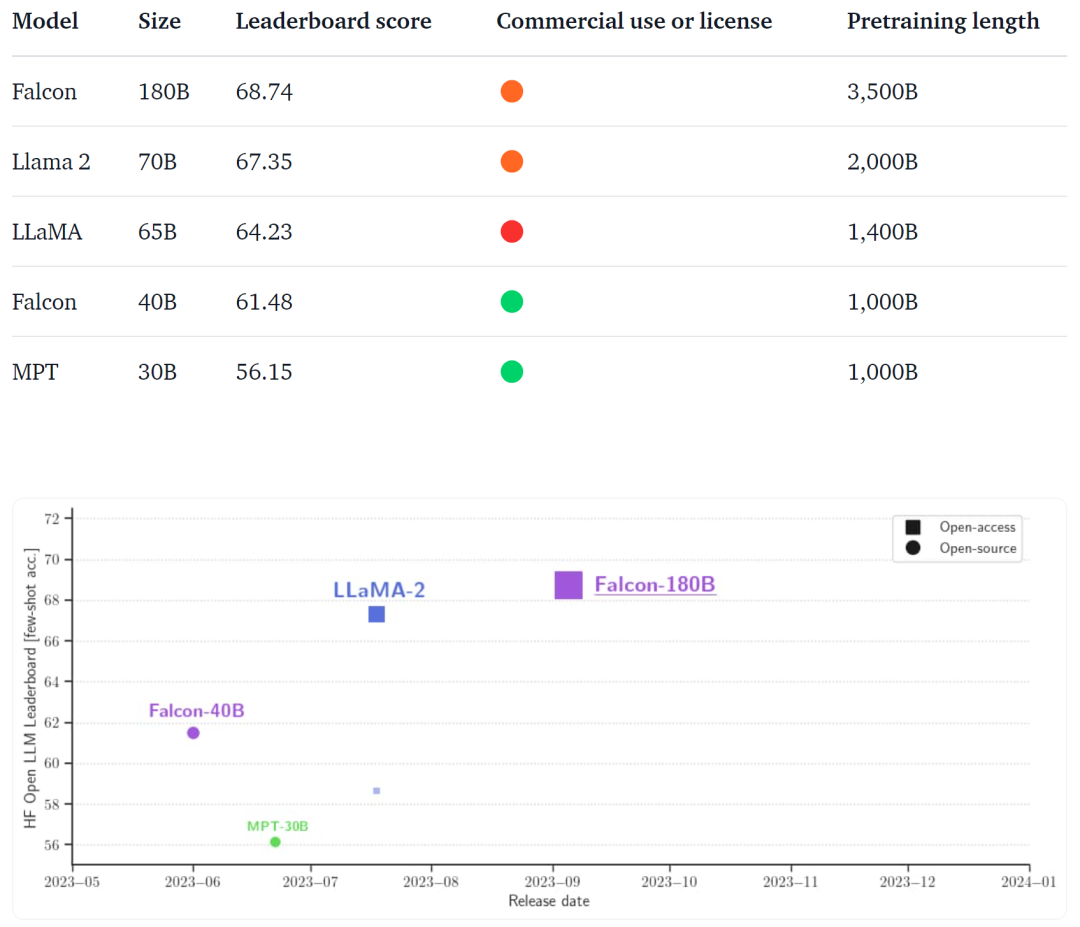
在開源方面,我們仍然落后于最大的閉源模型。目前,最大的公開型號是 Falcon 180B。這倒是不太令人擔憂,因為無論如何,大多數人都無法獲得處理這些模型所需的大量硬件資源。我們更加渴望的是更多由多個較小的子模塊組成的開源 MoE 模型,而不是更大的模型。
另外,我們也可以看到眾包數據集的上的進展,以及 DPO 的興起,以取代最先進的開源模型中的監督微調。