













如何使用LangChain和OpenAI API分析文檔?
譯文譯者 | 布加迪
審校 | 重樓
從文檔和數(shù)據(jù)中提取洞察力對于您做出明智的決策至關(guān)重要。然而在處理敏感信息時,會出現(xiàn)隱私問題。結(jié)合使用LangChain與OpenAI API,您就可以分析本地文檔,無需上傳到網(wǎng)上。
它們通過將數(shù)據(jù)保存在本地、使用嵌入和向量化進行分析以及在您的環(huán)境中執(zhí)行進程來做到這一點。OpenAI不使用客戶通過其API提交的數(shù)據(jù)來訓(xùn)練模型或改進服務(wù)。
搭建環(huán)境
創(chuàng)建一個新的Python虛擬環(huán)境,這將確保沒有庫版本沖突。然后運行以下終端命令來安裝所需的庫。
pip install langchain openai tiktoken faiss-cpu pypdf下面詳細說明您將如何使用每個庫:
- LangChain:您將用它來創(chuàng)建和管理用于文本處理和分析的語言鏈。它將提供用于文檔加載、文本分割、嵌入和向量存儲的模塊。
- OpenAI:您將用它來運行查詢,并從語言模型獲取結(jié)果。
- tiktoken:您將用它來計算給定文本中token(文本單位)的數(shù)量。這是為了在與基于您使用的token數(shù)量收費的OpenAI API交互時跟蹤token計數(shù)。
- FAISS:您將用它來創(chuàng)建和管理向量存儲,允許基于嵌入快速檢索相似的向量。
- PyPDF:這個庫從PDF提取文本。它有助于加載PDF文件并提取其文本,供進一步處理。
安裝完所有庫之后,您的環(huán)境現(xiàn)已準備就緒。
獲得OpenAI API密鑰
當您向OpenAI API發(fā)出請求時,需要添加API密鑰作為請求的一部分。該密鑰允許API提供者驗證請求是否來自合法來源,以及您是否擁有訪問其功能所需的權(quán)限。
為了獲得OpenAI API密鑰,進入到OpenAI平臺。
然后在右上方的帳戶個人資料下,點擊“查看API密鑰”,將出現(xiàn)API密鑰頁面。
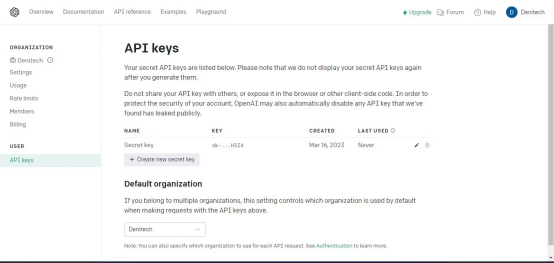
點擊“創(chuàng)建新的密鑰”按鈕。為密鑰命名,點擊“創(chuàng)建新密鑰”。OpenAI將生成API密鑰,您應(yīng)該復(fù)制并保存在安全的地方。出于安全原因,您將無法通過OpenAI帳戶再次查看它。如果丟失了該密鑰,需要生成新的密鑰。
導(dǎo)入所需的庫
為了能夠使用安裝在虛擬環(huán)境中的庫,您需要導(dǎo)入它們。
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI注意,您從LangChain導(dǎo)入了依賴項庫,這讓您可以使用LangChain框架的特定功能。
加載用于分析的文檔
先創(chuàng)建一個含有API密鑰的變量。稍后,您將在代碼中使用該變量用于身份驗證。
# Hardcoded API key
openai_api_key = "Your API key"如果您打算與第三方共享您的代碼,不建議對API密鑰進行硬編碼。對于打算分發(fā)的生產(chǎn)級代碼,則改而使用環(huán)境變量。
接下來,創(chuàng)建一個加載文檔的函數(shù)。該函數(shù)應(yīng)該加載PDF或文本文件。如果文檔既不是PDF文件,也不是文本文件,該函數(shù)會拋出值錯誤。
def load_document(filename):
if filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents = loader.load()
elif filename.endswith(".txt"):
loader = TextLoader(filename)
documents = loader.load()
else:
raise ValueError("Invalid file type")加載文檔后,創(chuàng)建一個CharacterTextSplitter。該分割器將基于字符將已加載的文檔分隔成更小的塊。
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=30, separator="\n")
return text_splitter.split_documents(documents=documents)分割文檔可確保塊的大小易于管理,仍與一些重疊的上下文相連接。這對于文本分析和信息檢索之類的任務(wù)非常有用。
查詢文檔
您需要一種方法來查詢上傳的文檔,以便從中獲得洞察力。為此,創(chuàng)建一個以查詢字符串和檢索器作為輸入的函數(shù)。然后,它使用檢索器和OpenAI語言模型的實例創(chuàng)建一個RetrievalQA實例。
def query_pdf(query, retriever):
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),
chain_type="stuff", retriever=retriever)
result = qa.run(query)
print(result)該函數(shù)使用創(chuàng)建的QA實例來運行查詢并輸出結(jié)果。
創(chuàng)建主函數(shù)
主函數(shù)將控制整個程序流。它將接受用戶輸入的文檔文件名并加載該文檔。然后為文本嵌入創(chuàng)建OpenAIEmbeddings實例,并基于已加載的文檔和文本嵌入構(gòu)造一個向量存儲。將該向量存儲保存到本地文件。
接下來,從本地文件加載持久的向量存儲。然后輸入一個循環(huán),用戶可以在其中輸入查詢。主函數(shù)將這些查詢與持久化向量存儲的檢索器一起傳遞給query_pdf函數(shù)。循環(huán)將繼續(xù),直到用戶輸入“exit”。
def main():
filename = input("Enter the name of the document (.pdf or .txt):\n")
docs = load_document(filename)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore.save_local("faiss_index_constitution")
persisted_vectorstore = FAISS.load_local("faiss_index_constitution", embeddings)
query = input("Type in your query (type 'exit' to quit):\n")
while query != "exit":
query_pdf(query, persisted_vectorstore.as_retriever())
query = input("Type in your query (type 'exit' to quit):\n")嵌入捕獲詞之間的語義關(guān)系。向量是一種可以表示一段文本的形式。
這段代碼使用OpenAIEmbeddings生成的嵌入將文檔中的文本數(shù)據(jù)轉(zhuǎn)換成向量。然后使用FAISS對這些向量進行索引,以便高效地檢索和比較相似的向量。這便于對上傳的文檔進行分析。
最后,如果用戶獨立運行程序,使用__name__ == "__main__"構(gòu)造函數(shù)來調(diào)用主函數(shù):
if __name__ == "__main__":
main()這個應(yīng)用程序是一個命令行應(yīng)用程序。作為一個擴展,您可以使用Streamlit為該應(yīng)用程序添加Web界面。
執(zhí)行文件分析
要執(zhí)行文檔分析,將所要分析的文檔存儲在項目所在的同一個文件夾中,然后運行該程序。它將詢問所要分析的文檔的名稱。輸入全名,然后輸入查詢,以便程序分析。
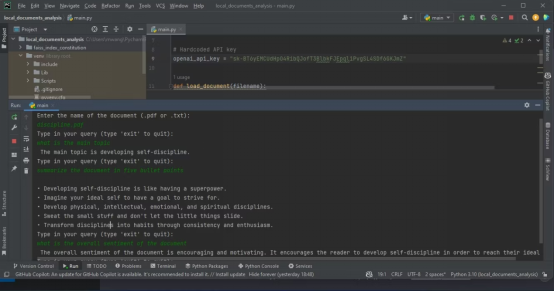
下面的截圖顯示了分析PDF的結(jié)果。
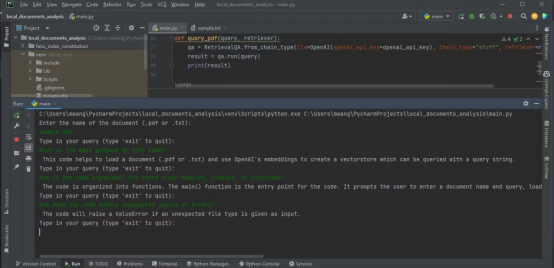
下面的輸出顯示了分析含有源代碼的文本文件的結(jié)果。
確保所要分析的文件是PDF或文本格式。如果您的文檔采用其他格式,可以使用在線工具將它們轉(zhuǎn)換成PDF格式。
完整的源代碼可以在GitHub代碼庫中獲得:https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI。
原文標題:How to Analyze Documents With LangChain and the OpenAI API,作者:Denis Kuria

























