提前對齊,視頻問答新SOTA!北大全新Video-LLaVA視覺語言大模型,秒懂視頻笑點
最近,來自北大的研究人員提出了一種全新的視覺語言大模型——Video-LLaVA,為alignment before projection提供了新穎的解決方案。
與以往的視覺語言大模型不同,Video-LLaVA關注的是提前將圖片和視頻特征綁定到統一個特征空間,使LLM能夠從統一的視覺表示從學習模態的交互。
此外,為了提高計算效率,Video-LLaVA還聯合了圖片和視頻進行訓練和指令微調。
論文地址:https://arxiv.org/pdf/2310.01852.pdf
GitHub地址:https://github.com/PKU-YuanGroup/Video-LLaVA
Huggingface地址:https://huggingface.co/spaces/LanguageBind/Video-LLaVA
憑借強大的語言理解能力,諸如ChatGPT這類的大語言模型迅速在AI社區風靡。而如何讓大語言模型同時理解圖片和視頻,也成為了大模型背景下的研究多模態融合的熱點問題。
最近的工作將圖片或視頻通過幾個全連接層映射成類似文本的token,讓LLM涌現理解視覺信號的能力。
然而,圖片和視頻是分開用各自的編碼器,這對LLM學習統一的視覺表征帶來了挑戰。并且通過幾個映射層教會LLM同時處理圖片和視頻的性能往往不如視頻專家模型如Video-ChatGPT。
對此,來自北大團隊認為這種現象源于misalignment before projection。因為圖片特征和視頻特征在送入LLM之前就已經收斂到各自的特征域空間,這就給LLM學習它們之間的交互帶來了挑戰。
類似的現象如misalignment before fusion,也可以在早期的多模態融合工作被觀察到,如ALBEF。
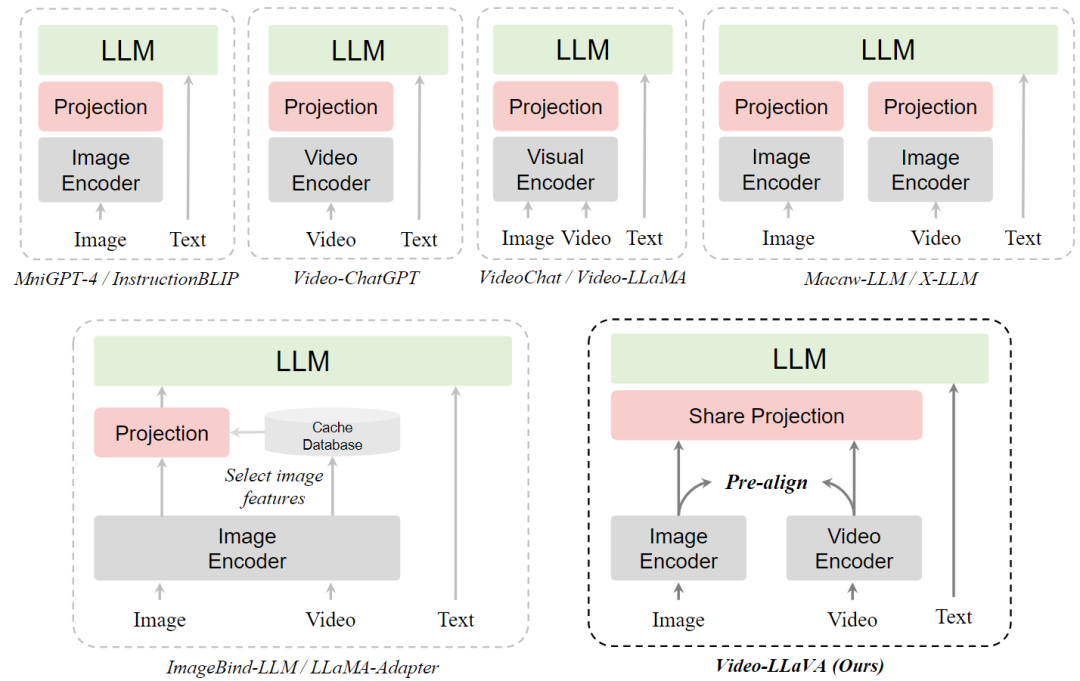
不同視覺語言大模型范式的比較
方法介紹
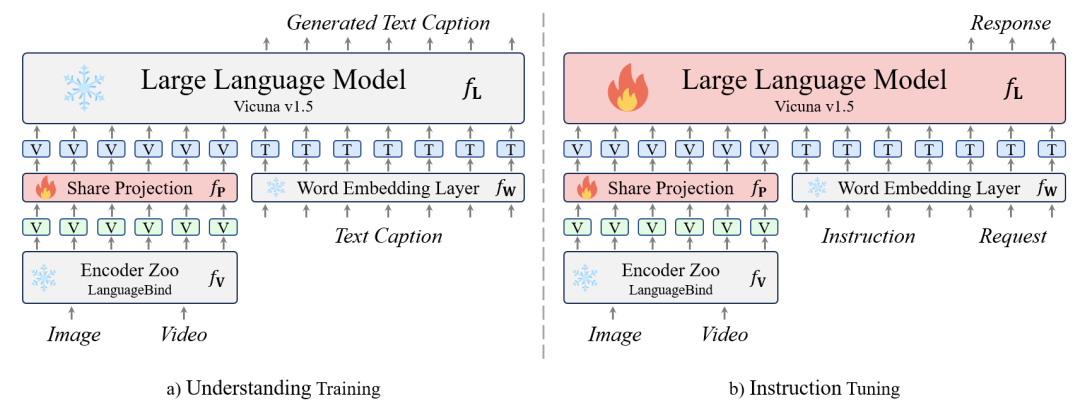
Video-LLaVA的方法簡單有效,不需要額外自己預先訓練圖片和視頻模態的編碼器,而是巧妙地通過LanguageBind編碼器來預先對齊圖片和視頻特征,形成統一的視覺表征。
具體來說,Video-LLaVA采用的圖片和視頻編碼器通過共享一個語言特征空間,圖像和視頻表示最終融合成一個統一的視覺特征空間,稱之為圖像和視頻的emergent alignment。
因此,Video-LlaVA通過LanguageBind預先對視覺輸入進行對齊,以減小不同視覺信號表示之間的差距。統一的視覺表征經過共享的投影層后,輸入到大語言模型中。
并且Video-LlaVA在訓練過程中始終沒有用到視頻圖片成對的數據,而是在訓練后發現的LLM會驚人的涌現出同時理解圖片和視頻。
如下圖所示,Video-LlaVA成功的識別出圖片的自由女神像是近景且細膩的,而視頻描述的是多角度的自由女神像,他們是來源于同一個地方。

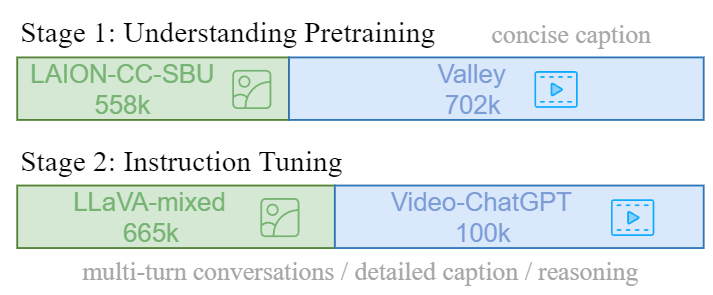
Video-LLaVA采取兩階段的訓練策略:
在視覺理解階段,使用了一個558K個LAION-CC-SBU圖像-文本對。視頻-文本對是從Valley 提供的子集中獲得的,總共有703k對,這些視頻源自WebVid。
在指導微調階段,團隊從兩個來源收集了指導性數據集,包括來自LLaVA的665k個圖像-文本數據集,以及從Video-ChatGPT獲得的包含100k個視頻-文本數據集。
- 視覺理解階段
在這個階段,模型需要通過一個廣泛的視覺-文本對數據集來獲取解讀視覺信號的能力。每個視覺信號對應一個回合的對話數據。
這個階段的訓練目標是原始的自回歸損失,模型通過學習基本的視覺理解能力。在此過程中,凍結模型的其他參數。
- 指令微調階段
在這個階段,模型需要根據不同的指令提供相應的回復。這些指令通常涉及更復雜的視覺理解任務,而不僅僅是描述視覺信號。需要注意的是,對話數據包含多個回合。
如果涉及多輪對話,輸入數據會將所有之前回合的對話與當前指令連接起來,作為本回合的輸入。訓練目標與前一階段相同。
經過這個階段,模型學會了根據不同的指令和請求生成相應的回復。在這個階段,大語言模型也參與訓練。
實驗
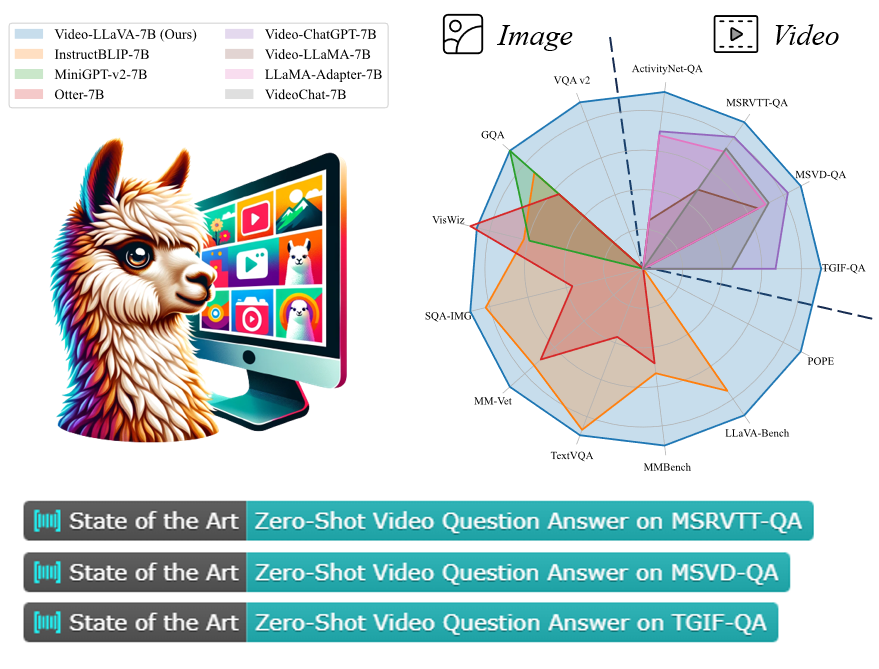
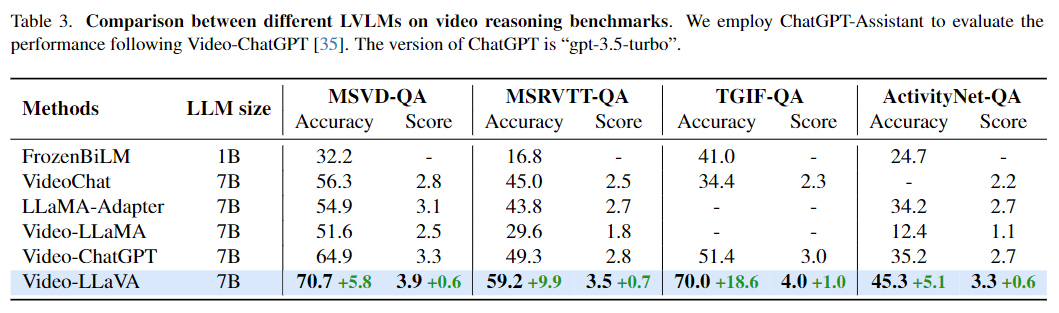
- 視頻理解能力
如表3所示,Video-LLaVA在4個視頻問答數據集上全面超過了Video-ChatGPT,并且漲幅相當可觀。
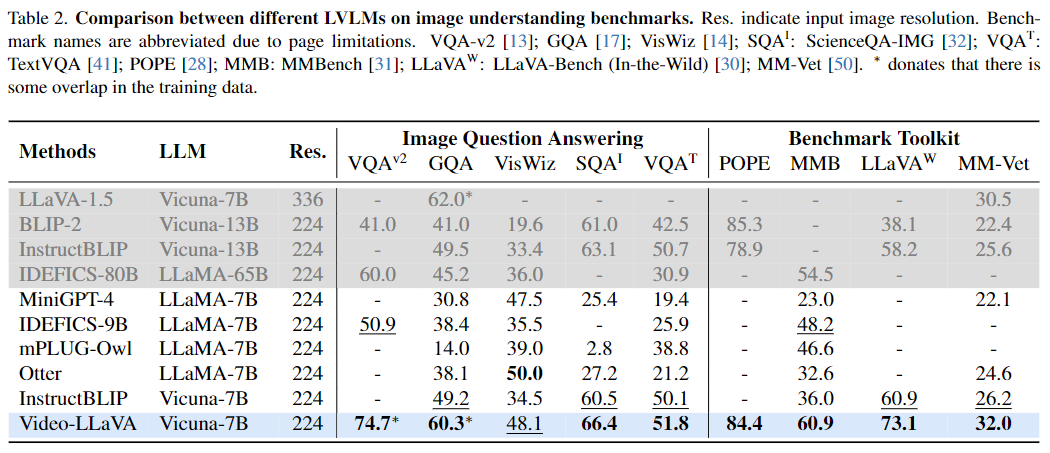
- 圖片理解能力
該研究還與InstructBLIP,Otter,mPLUG-owl 等圖片語言大模型在圖片語言理解任務上進行了比較,結果如表2所示:
- 預先對齊視覺輸入
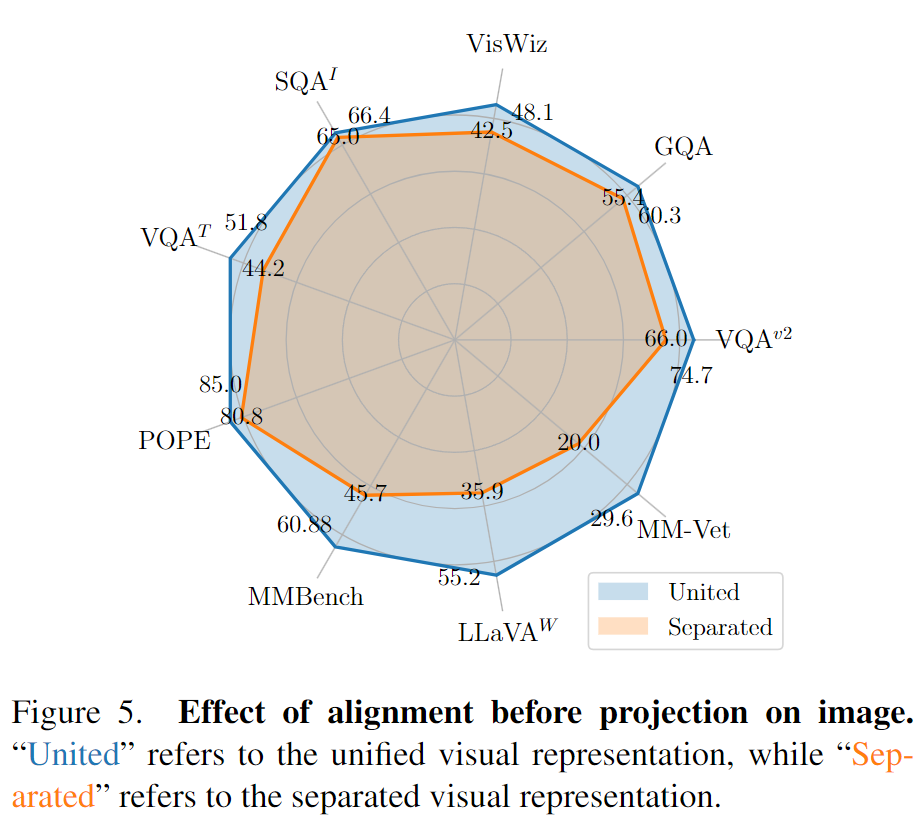
將圖片編碼器替換相同規模的MAE encoder。定義用MAE encoder是分隔的視覺表示,Languagebind是統一視覺表示(因為預先對齊了視覺表征),并且將MAE encoder和LanguageBind encoder在13個基準上進行對比,這其中包含9個圖片理解基準和4個視頻理解基準。
對于圖片理解,統一視覺表示展現了強大的性能,它在5個圖片問答數據集和4個基準工具箱上全面超過了分隔的視覺表示。
另外,我們注意到統一視覺表示在POPE,MMBench,LLaVA-Bench,MM-Vet這四個基準工具箱上的性能以巨大的優勢超過。
這突出了預先對齊了視覺表征不僅在圖片問答上提升了性能,還在圖片理解的其他方面收益,如減小幻覺,提升OCR能力等。
由于替換圖片編碼器為MAE encoder,視頻特征和圖片特征在LLM初始學習視覺表示時不再統一。
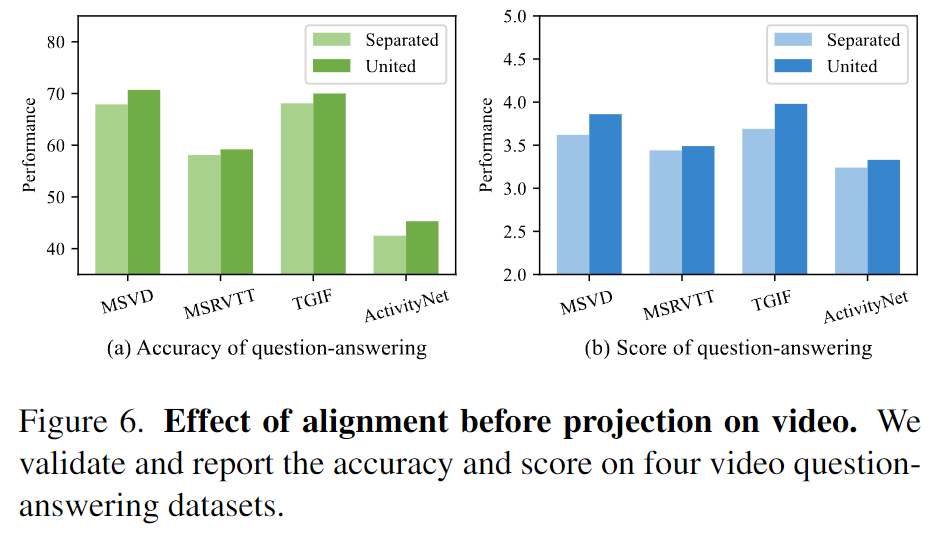
在圖6,相比于分隔視覺表示,聯合視覺表示在4個視頻問答數據集上全面提高了性能。
這些結果展現了預先對齊視覺表征表示能夠幫助LLM進一步學習理解視頻。
同時論文還驗證了無論是對于圖片還是視頻,在聯合訓練中他們能相互受益。
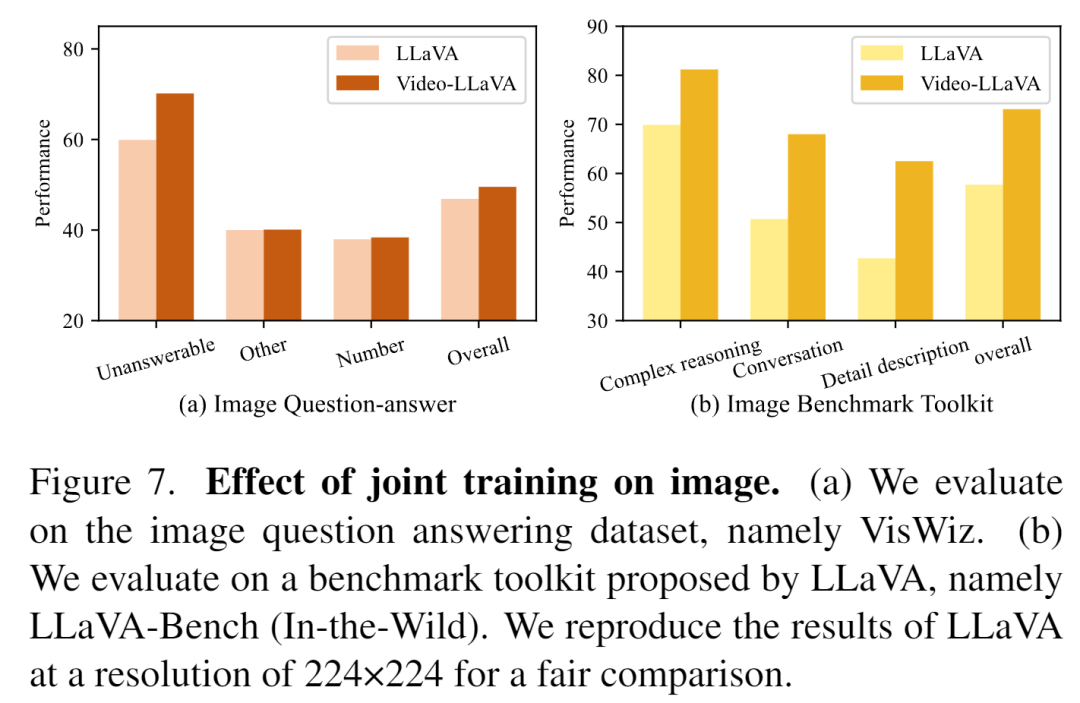
對于圖片理解,Video-LLaVA在無法回答的和數字上的表現超過了LLaVA-1.5,這意味著聯合訓練視頻使得在圖片上的幻覺問題有所緩解,和對圖片數字信號的理解能力增強。
相同的趨勢在LLaVA-Bench上被觀察到,Video數據顯著提升了LLM在圖片Complex reasoning,Conversation上的表現。
對于視頻理解,團隊在4個Video問答數據集上評估。
與沒有圖片參與訓練的Video-LLaVA相比,有圖片聯合訓練的模型在4個數據集上全面超過。
這些結果證明了聯合圖片和視頻一起訓練能夠促進LLM理解視覺表示。