規模小、效率高:DeepMind推出多模態解決方案Mirasol 3B
多模態學習面臨的主要挑戰之一是需要融合文本、音頻、視頻等異構的模態,多模態模型需要組合不同來源的信號。然而,這些模態具有不同的特征,很難通過單一模型來組合。例如,視頻和文本具有不同的采樣率。
最近,來自 Google DeepMind 的研究團隊將多模態模型解耦成多個獨立的、專門的自回歸模型,根據各種模態的特征來處理輸入。
具體來說,該研究提出了多模態模型 Mirasol3B。Mirasol3B 由時間同步模態(音頻和視頻)自回歸組件,以及用于上下文模態的自回歸組件組成。這些模態不一定在時間上對齊,但是按順序排列的。

論文地址:https://arxiv.org/abs/2311.05698
Mirasol3B 在多模態基準測試中達到了 SOTA 水平,優于規模更大的模型。通過學習更緊湊的表征,控制音頻 - 視頻特征表征的序列長度,并根據時間對應關系進行建模,Mirasol3B 能夠有效滿足多模態輸入的高計算要求。
方法簡介
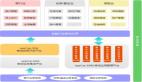
Mirasol3B 是一個音頻 - 視頻 - 文本多模態模型,其中將自回歸建模解耦成時間對齊模態(例如音頻、視頻)的自回歸組件,以及針對非時間對齊的上下文模態(例如文本)的自回歸組件。Mirasol3B 使用交叉注意力權重來協調這些組件的學習進程。這種解耦使得模型內部的參數分布更合理,也為模態(視頻和音頻)分配了足夠的容量,并使得整體模型更加輕量。
如下圖 1 所示,Mirasol3B 主要由兩個學習組件組成:自回歸組件,旨在處理(幾乎)同步的多模態輸入,例如視頻 + 音頻,并及時組合輸入。


該研究還提出將時間對齊的模態分割成時間段,在時間段中學習音頻 - 視頻聯合表征。具體來說,該研究提出了一種名為「Combiner」的模態聯合特征學習機制。「Combiner」融合了同一時間段中的模態特征,產生了更緊湊的表征。
「Combiner」從原始的模態輸入中提取初級的時空表示,捕捉視頻的動態特性,并結合與其共時的音頻特征,模型可以在不同的速率接收多模態輸入,在處理較長的視頻時表現良好。
「Combiner」有效地滿足了模態表征既要高效又要信息量豐富的需求。它可以充分涵蓋視頻與其他同時發生的模態中的事件和活動,并能夠用于后續的自回歸模型,學習長期依賴關系。

為了處理視頻和音頻信號,并適應更長的視頻 / 音頻輸入,它們被分割成(在時間上大致同步)的小塊,再通過「Combiner」學習聯合視聽表示。第二個組件處理上下文,或時間上未對齊的信號,如全局文本信息,這些信息通常仍然是連續的。它也是自回歸的,并使用組合的潛在空間作為交叉注意力輸入。
視頻 + 音頻學習組件有 3B 參數;沒有音頻的組件是 2.9B。多半參數用于音頻 + 視頻自回歸模型。Mirasol3B 通常處理 128 幀的視頻,也可以處理更長(例如 512 幀)的視頻。
由于設計了分區和「Combiner」的模型架構,增加更多幀,或增加塊的大小、數目等,只會使參數略有增加,解決了更長視頻需要更多參數、更大的內存的問題。
實驗及結果
該研究在標準 VideoQA 基準、長視頻 VideoQA 基準和音頻 + 視頻基準上對 Mirasol3B 進行了測試評估。
在 VideoQA 數據集 MSRVTTQA 上的測試結果如下表 1 所示,Mirasol3B 超越了目前的 SOTA 模型,以及規模更大的模型,如 PaLI-X、Flamingo。

在長視頻問答方面,該研究在 ActivityNet-QA、NExTQA 數據集上對 Mirasol3B 進行了測試評估,結果如下表 2 所示:

最后,該研究選擇使用 KineticsSound、VGG-Sound、Epic-Sound 進行音頻 - 視頻基準測試,采用開放式生成評估,實驗結果如下表 3 所示:

感興趣的讀者可以閱讀論文原文,了解更多研究內容。