













橫掃13個視覺語言任務!哈工深發(fā)布多模態(tài)大模型「九天」,性能直升5%
為了應對多模態(tài)大語言模型中視覺信息提取不充分的問題,哈爾濱工業(yè)大學(深圳)的研究人員提出了雙層知識增強的多模態(tài)大語言模型-九天(JiuTian-LION)。

論文鏈接: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
項目主頁: https://rshaojimmy.github.io/Projects/JiuTian-LION
與現(xiàn)有的工作相比,九天首次分析了圖像級理解任務和區(qū)域級定位任務之間的內部沖突,提出了分段指令微調策略和混合適配器來實現(xiàn)兩種任務的互相提升。
通過注入細粒度空間感知和高層語義視覺知識,九天實現(xiàn)了在包括圖像描述、視覺問題、和視覺定位等17個視覺語言任務上顯著的性能提升( 比如Visual Spatial Reasoning 上高達5% 的性能提升),在其中13個評測任務上達到了國際領先水平,性能對比如圖1所示。

圖1:對比其他MLLMs,九天在大部分任務上都取得了最優(yōu)的性能。
九天JiuTian-LION
借助大型語言模型(LLMs)驚人的語言理解能力,一些工作開始通過賦予 LLM 多模態(tài)感知能力,來生成多模態(tài)大語言模型(MLLMs),并在很多視覺語言任務上取得突破性進展。但是現(xiàn)有的MLLMs大多采用圖文對預訓練得到的視覺編碼器,比如 CLIP-ViT。
這些視覺編碼器主要學習圖像層面的粗粒度圖像文本模態(tài)對齊,而缺乏全面的視覺感知和信息抽取能力,包括細粒度視覺理解。
這種視覺信息抽取不足,理解程度不夠的問題,在很大程度上會導致MLLMs存在視覺定位偏差,空間推理不足,物體幻覺等諸多缺陷,如圖2所示。
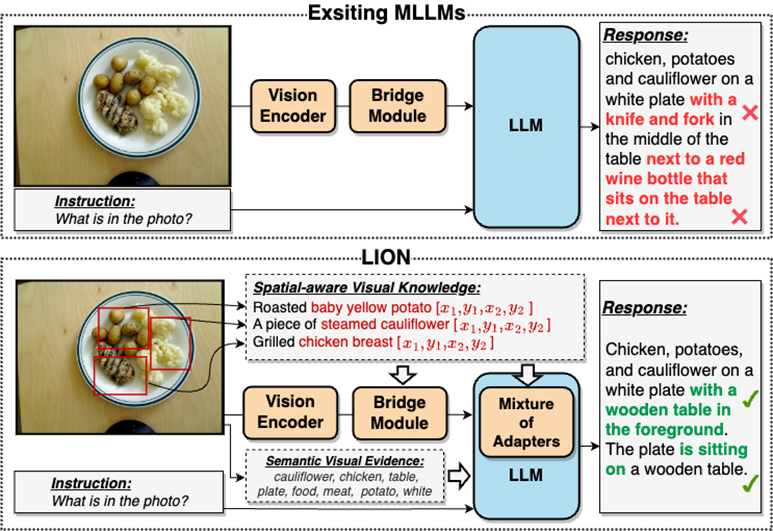
圖2:雙層視覺知識增強的多模態(tài)大語言模型-九天(JiuTian-LION)。
與現(xiàn)有的多模態(tài)大語言模型(MLLMs)相比,九天通過注入細粒度空間感知視覺知識和高層語義視覺證據(jù),有效地提升了MLLMs的視覺理解能力,生成更準確的文本回應,減少了MLLMs的幻覺現(xiàn)象。
雙層視覺知識增強的多模態(tài)大語言模型-九天(JiuTian-LION)
為了彌補MLLMs中視覺信息提取不足,理解程度不夠的問題,研究人員提出了雙層視覺知識增強的MLLMs,簡稱九天(JiuTian-LION),方法框架如圖3所示。
該方法主要從兩方面增強MLLMs,漸進式融合細粒度空間感知視覺知識(Progressive Incorporation of Fine-grained Spatial-aware Visual knowledge)和軟提示下的高層語義視覺證據(jù)(Soft Prompting of High-level Semantic Visual Evidence)。
具體來說,研究人員提出了分段指令微調策略來解決圖像級理解任務和區(qū)域級定位任務之間存在的內部沖突,漸進式地將細粒度空間感知知識注入到 MLLMs 中。同時將圖像標簽作為高層語義視覺證據(jù)加入到 MLLMs,并利用軟提示方法來減輕不正確標簽帶來的潛在負面影響。
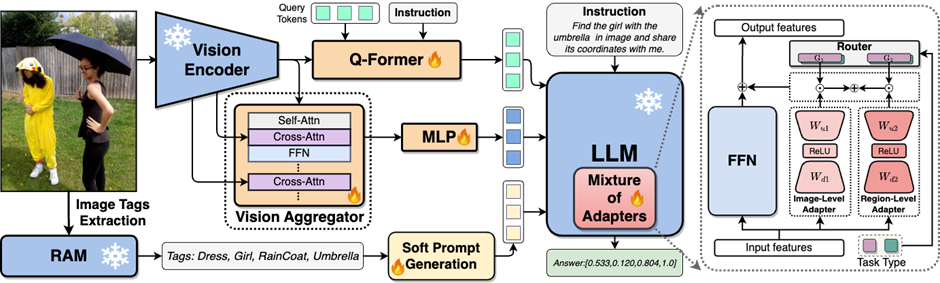
圖3:九天( JiuTian-LION) 模型框架圖。
該工作通過分段式訓練策略先分別基于Q-Former 和 Vision Aggregator – MLP 兩個分支學習圖像級理解和區(qū)域級定位任務,然后在最后訓練階段利用具有路由機制的混合適配器來動態(tài)融合不同分支的知識提升模型在兩種任務的表現(xiàn)。
該工作還通過 RAM 提取圖像標簽作為高層語義視覺證據(jù),然后提出軟提示方法提升高層語義注入的效果。
漸進式融合細粒度空間感知視覺知識
當直接將圖像級理解任務(包括圖像描述和視覺問答)與區(qū)域級定位任務(包括指示表達理解,指示表達生成等)進行單階段混合訓練時,MLLMs 會遭遇兩種任務之間存在的內部沖突,從而不能在所有任務上取得較好的綜合性能。
研究人員認為這種內部沖突主要由兩個問題引起。第一個問題是缺少區(qū)域級的模態(tài)對齊預訓練,當前具有區(qū)域級定位能力的 MLLMs 大多先使用大量相關數(shù)據(jù)進行預訓練,不然很難在有限地訓練資源下讓基于圖像級模態(tài)對齊的視覺特征適應區(qū)域級任務。
另一個問題是圖像級理解任務和區(qū)域級定位任務之間的輸入輸出模式差異,后者需要模型額外理解關于物體坐標的特定短句(以 的形式)。為了解決以上問題,研究人員提出了分段式指令微調策略,以及具有路由機制的混合適配器。
的形式)。為了解決以上問題,研究人員提出了分段式指令微調策略,以及具有路由機制的混合適配器。
如圖4所示,研究人員將單階段指令微調過程拆分為三階段:
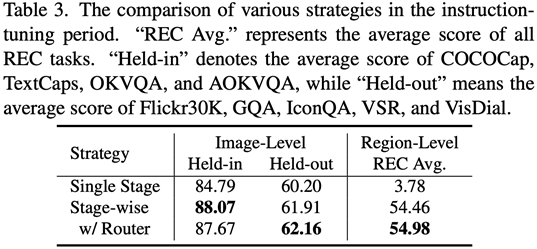
階段1,利用 ViT,Q-Former,和image-level adapter 來學習圖像級理解任務中包含的全局視覺知識;階段2,利用Vision Aggregator, MLP,和 region-level adapter 去學習區(qū)域級定位任務中包含的細粒度空間感知視覺知識;階段3,提出了具有路由機制的混合適配器來動態(tài)融合不同分支中學習到的不同粒度的視覺知識。表3展示了分段式指令微調策略相比較單階段訓練的性能優(yōu)勢。
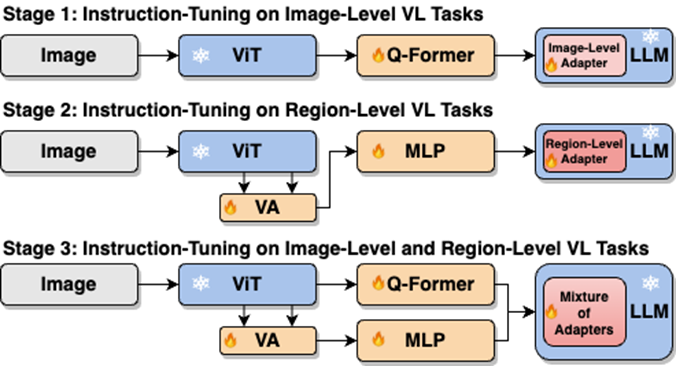
圖4:分段式指令微調策略
軟提示下的高層語義視覺證據(jù)注入
作為一個有力的補充,研究人員提出利用圖像標簽作為高層語義視覺證據(jù)來進一步增強 MLLMs 的全局視覺感知理解能力。
具體來說,首先通過 RAM 提取圖像的標簽,然后利用特定的指令模版“According to <hint>, you are allowed to use or partially use the following tags:”包裝圖像標簽。該指令模版中的“<hint>”會被替換為一個可學習的軟提示向量。
配合模版中特定短語“use or partially use”,軟提示向量可以指導模型減輕不正確標簽帶來的潛在負面影響。
實驗結果
研究人員在包括圖像描述(image captioning)、視覺問答(VQA)、和指示表達理解(REC)等17個任務基準集上進行了評測。
實驗結果表明,九天在13個評測集上達到了國際領先水平。特別的,相比較 InstructBLIP 和 Shikra,九天分別在圖像級理解任務和區(qū)域級定位任務上取得了全面且一致的性能提升,在 Visual Spatial Reasoning (VSR) 任務上可達到最高5%的提升幅度。

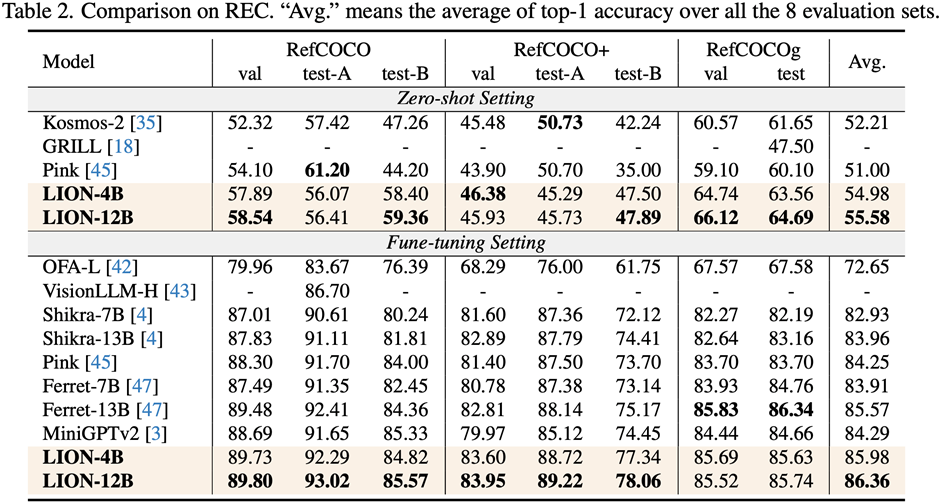
圖5提供了在不同視覺語言多模態(tài)任務上,九天和其他 MLLMs 的能力差異,說明了九天可以取得更優(yōu)的細粒度視覺理解和視覺空間推理能力,并且輸出具有更少幻覺的文本回應。

圖5:定性分析九天大模型和 InstructBLIP、Shikra 的能力差異
圖6通過樣本分析,表明了九天模型在圖像級和區(qū)域級視覺語言任務上都具有優(yōu)秀的理解和識別能力。

圖6:更多例子分析,從圖像和區(qū)域級視覺理解層面展現(xiàn)九天大模型的能力
總結
(1)該工作提出了一個新的多模態(tài)大語言模型-九天:通過雙層視覺知識增強的多模態(tài)大語言模型。
(2)該工作在包括圖像描述、視覺問答和指示表達理解等17個視覺語言任務基準集上進行評測,其中13個評測集達到了當前最好的性能。
(3)該工作提出了一個分段式指令微調策略來解決圖像級理解和區(qū)域級定位任務之間的內部沖突,實現(xiàn)了兩種任務的互相提升。
(4)該工作成功將圖像級理解和區(qū)域級定位任務進行整合,多層次全面理解視覺場景,未來可以將這種全面的視覺理解能力應用到具身智能場景,幫助機器人更好、更全面地識別和理解當前環(huán)境,做出有效決策。




























