













HiLM-D:自動駕駛多模態大語言模型玩出花了
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
筆者個人的一些思考
不得不說,最近大模型在學術界火起來了,基于圖文匹配的CLIP預訓練模型成為近年來在多模態研究領域的經典之作。除此之外,大語言模型的蓬勃發展也進一步為多模態帶來了性能提升。自動駕駛領域也有類似的數據(圖像/視頻+caption)用于車輛行為分析如BDD-X,最近也有新的工作直接構建自動駕駛場景下的QA,如DQA和DRIVEGPT4中使用chatgpt擴展的BDD-X數據集,這些工作都為端到端自動駕駛技術提供了可能;然而,現有多模態范式中輸入尺度較小(224x224),識別精度受限,因此在多模態的基礎上提出了高分辨率分支增強目標很重要,尤其是風險目標的識別能力用于——風險目標定位和自車意圖以及建議預測(ROLISP),接下來我們一起看下具體是怎么實現的。
HiLM-D是怎么做的?
自動駕駛系統通常采用針對不同任務的單獨模型,導致設計復雜。HiLM-D首次利用單一的多模態大語言模型(MLLMs)來整合來自視頻的多個自動駕駛任務,即"Risk Object Localization and Intention and Suggestion Prediction(ROLISP)"任務。ROLISP使用自然語言同時識別和解釋風險目標,理解自動駕駛車輛的意圖并提供運動建議,從而消除了需要特定任務架構的必要性。然而,由于缺乏高分辨率(HR)信息,現有的MLLMs在應用于ROLISP時通常會錯過小物體(例如交通錐)并過分關注顯著的物體(例如大卡車)。本文提出了HiLM-D("Towards High-Resolution Understanding in MLLMs for Autonomous Driving"),這是一種有效的方法,將HR信息合并到MLLMs中,用于ROLISP任務。特別是,HiLM-D整合了兩個分支:(i)低分辨率推理分支,可以是任何MLLMs,處理低分辨率視頻以為風險目標添加標題并識別自動駕駛車輛的意圖/建議;(ii)高分辨率感知分支(HR-PB),是HiLM-D的主要部分,攝入高分辨率圖像以通過捕獲具有視覺特定HR特征圖的高分辨率特征圖來增強檢測,并優先考慮所有潛在風險,而不僅僅是顯著的目標。HiLM-D的HR-PB作為即插即用模塊,可以無縫地適應現有的MLLMs。在ROLISP基準測試上的實驗證明,HiLM-D在caption生成方面的BLEU-4得分提高了4.8%,在檢測方面的mIoU提高了17.2%,顯示了HiLM-D相對于主要MLLMs的顯著優勢。
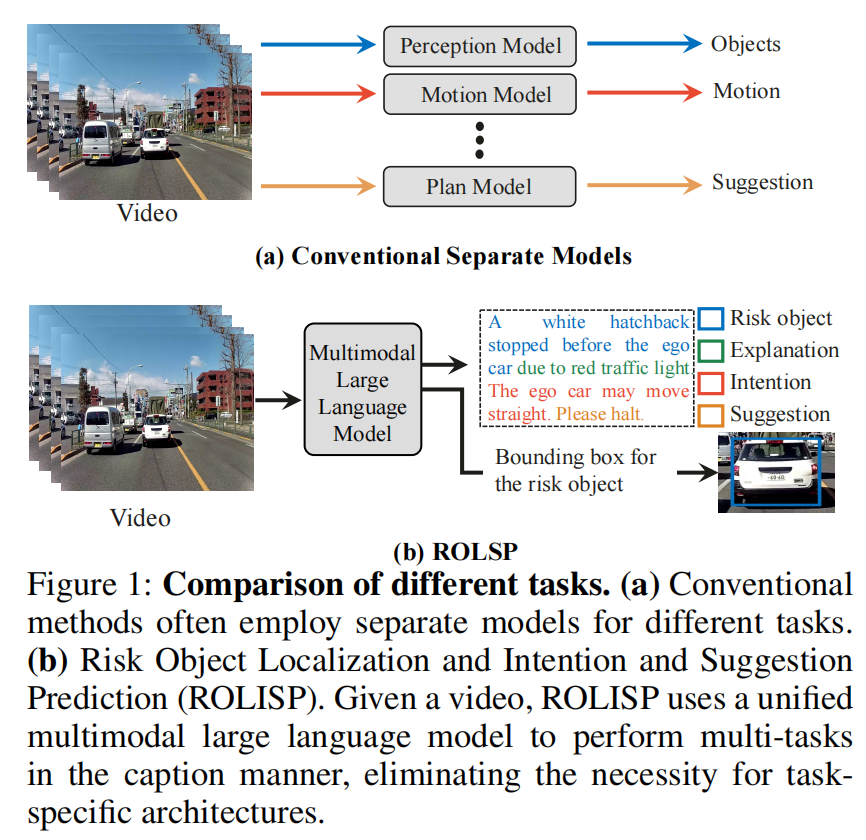
HiLM-D優勢有哪些?
? 利用MLLMs通過自然語言范例來解決多個自動駕駛任務,即ROLISP。
? 普遍的MLLMs通常在訓練時輸入具有單一小尺寸(即224×224)的圖像。HiLM-D引入了HiLM-D(400x400)來生成豐富的包含視覺特定先驗知識和突出高風險區域的高分辨率特征圖,這些特征圖可以與現有的MLLMs無縫集成并增強它們。
?在ROLISP基準測試上進行了實驗,以證明HiLM-D的卓越性能,例如在BLEU-4caption生成方面比最先進的MLLMs提高了4.8%。
目前領域相關工作
多模態大語言模型
隨著大語言模型(LLMs)的出現,自然語言處理取得了重大進展,例如GPT系列,T5,LLaMA等。受LLMs的潛力激發,許多多模態大語言模型(MLLMs),例如LLaVA,MiniGPT-4,Video-LLaMA和InstructBLIP,已被提出以將LLMs擴展到多模式領域,即感知圖像/視頻輸入,并在多輪對話中與用戶交流。這些模型在大規模的圖像/視頻文本對上進行了預訓練,但這些模型僅能處理圖像級任務,如圖像caption和問題回答。因此,一些作品如ContextDET,KOSMOS-2和Shikra已被提出,以實現MLLMs的基礎能力,產生邊界框。然而,所有當前的MLLMs都在低分辨率的圖像文本對中訓練模型,這在高分辨率自動駕駛場景中限制了感知結果,
自動駕駛
在自動駕駛領域,傳統的自動駕駛算法通常獨立處理不同的任務,例如檢測、跟蹤、推理和預測。為了提取更豐富的跨任務信息,研究人員開始探索將多個任務集成到端到端的訓練框架中。例如,一些作品如D&T展示了檢測和跟蹤的聯合訓練,FaF進一步將檢測器與軌跡預測器統一,取得了顯著的成果。UniAD脫穎而出,將全棧自動駕駛任務融合在一個統一的框架中,盡管仍然依賴于每個任務的不同子網絡。該領域中的一個新方向是將自然語言用作跨任務的統一輸出。例如,ADAPT使用單個caption來預測意圖并提供解釋,而DRAMA旨在檢測和解釋風險目標。在HiLM-D中,比Drama和ADAPT更進一步,即ROLISP,旨在識別、解釋和定位風險目標,同時預測其意圖并提供建議。
HiLM-D方法設計
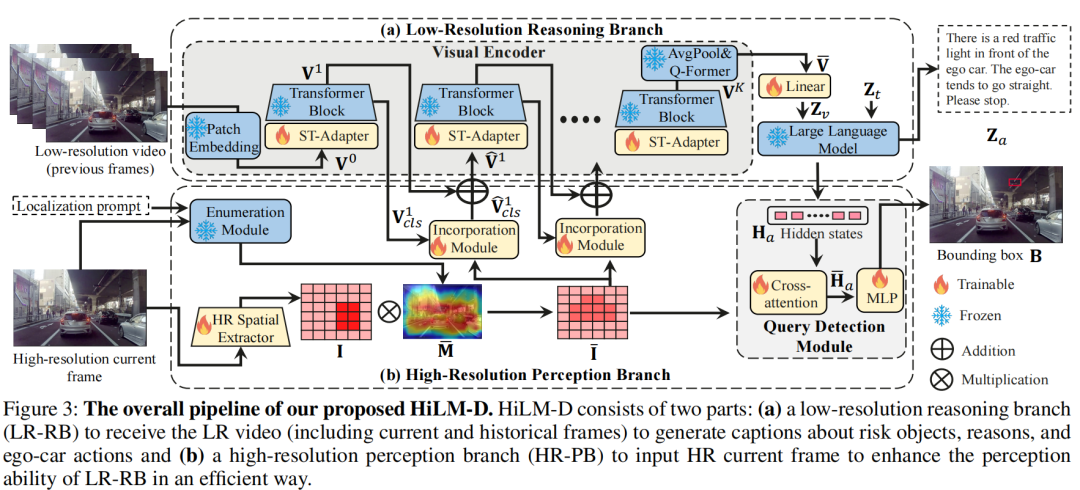
Low-Resolution Reasoning Branch
低分辨率推理分支(LR-RB)利用MLLM來接收低分辨率(LR)視頻輸入,并以自然語言方式生成識別的風險目標(包括原因)以及自車的意圖和建議,包括一個視覺編碼器和一個大語言模塊。
Visual Encoder.(凍結的ViT和Q-former+需訓練的ST-Adapter) 視覺編碼器負責將視頻輸入轉換為視覺標記,使大語言模型(LLM)能夠理解它們。它建立在預訓練的圖像視覺變換器(ViT)和Q-former的基礎上,采用BLIP2(Li等人2023年)初始化,并在訓練過程中保持凍結。為了處理圖像的時序性,該編碼器還包括一個時空適配器(ST-Adapter)(Pan等人2022年)。具體地,對于具有幀的視頻,ViT將每個幀映射到其第層特征,產生, 其中 是第幀的特征, 是patch的數量, 是緯度. 這些特征進一步通過ST-Adapter和一個變換塊進行處理,產生 . 最終的視頻表示為, , 通過將ViT的最后一層特征進行平均池化和 -former. 一個可訓練的線性層然后將投影到LLM的維度,生成。
Large Language Model (LLM).(凍結,具體哪個模型似乎沒寫) 有了視覺標記,就可以利用預訓練的LLM來生成包括風險目標的標識以及解釋、意圖和建議在內的caption,供自動駕駛車輛使用。LLM的輸入由多模態標記 的連接組成, 其中 表示從文本提示(例如“哪個目標風險最高?然后預測自車的動作和建議。”)中標記的文本嵌入。預訓練的LLM接收這些多模態標記來自動地生成語言。
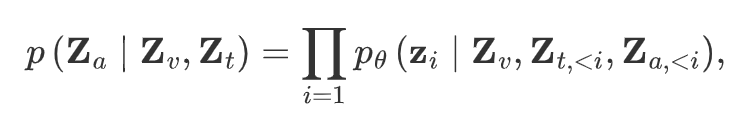
其中是可訓練參數, 是生成的答案。
High-Resolution Perception Branch
高分辨率感知分支(HR-PB)專門設計用于整合來自高分辨率圖像的視覺特定信息以及與潛在高風險目標相關的特征,以供LR-RB使用。
該分支由四個部分組成:
? HR空間提取器(HRSE),用于獲取HR幀的HR特征;
? 枚舉模塊,用于突出顯示所有潛在高風險目標;
? 整合模塊,將所有潛在風險目標整合到LR-RB中;
? 查詢檢測頭,用于基于HR特征檢測目標。
HR空間提取器(需訓練的ResNet)
為了捕獲目標檢測的視覺特定信息,HRSE改編自經典的卷積網絡(CNN)ResNet。與當前MLLM中的普通ViT相比,CNN具有許多優勢:減少內存和計算資源,并為檢測任務(例如局部連接性和空間不變性)帶來視覺特定的先驗知識。HiLM-D將提取的高分辨率空間特征圖表示為,其中 和 分別表示維度、寬度和高度。
枚舉模塊(凍結的GradCAM)
在自動駕駛中,一些風險目標,如行人或交通錐,可能僅占整個圖像的一小部分,通常位于邊緣區域。然而,HiLM-D的實驗發現,現有的MLLM傾向于優先考慮更顯眼的目標,如大型車輛,導致風險目標的誤識別。為了解決這個問題,引入了一個枚舉模塊,確保模型關注所有潛在的高風險目標區域,而不僅僅是主導的目標。該模塊利用預訓練的MLLM來測量圖像和位置提示之間的相似性,例如“車輛、紅綠燈/錐形標識和人在哪里?”。隨后,使用GradCAM(Selvaraju等人,2017)生成一個強調這些高風險目標區域的映射。將生成的強調地圖表示為 ,其中 與 分別表示強調地圖的寬度和高度,其值范圍從0到1。然后,將上采樣到與相等的大小,得到。最后,獲得了突出顯示的高分辨率圖像特征,其中表示逐元素相乘,.
整合模塊(需訓練的交叉注意力)
整合模塊旨在讓從LR-RB學到的語義與所有潛在風險目標的空間特征相融合,從而使LLM能夠比較和決定哪一個需要最多的關注。通過一個交叉注意力模塊來實現這一點,該模塊將LR-RB第層的特征作為查詢,突出顯示的HR特征圖作為值和鍵。為了進行高效的計算,只使用 中的cls標記作為查詢,即。然后,交叉注意力可以表示為。將 添加到原始的后,獲得新的cls標記,即,用于第個ST-Adapter和變壓器塊。是可學習的門控因子,用于自適應地控制的重要性,其初始值為零,以避免在訓練初期對原始ViT造成干擾。最后,整合后的視覺標記由 獲得。
查詢檢測頭(需要訓練的交叉注意力+MLP)。
為了獲得精確的邊界框,HiLM-D設計了一個查詢檢測頭,將找到的風險目標的表示視為先驗知識,用于在HR特征I中找到邊界框。為實現這一點,使用風險目標的隱藏狀態作為查詢,突出顯示的HR空間特征作為值和鍵來計算交叉關注,可以表示為,其中 是與答案相關的語言標記的隱藏狀態,即找到的目標。最后,被饋送到MLP以生成邊界框,即 。然后,預測的邊界框由進行監督, 是GT。
總損失定義如下:

其中 是超參數。
實驗設置與分析
實施細節。提出的方法在PyTorch中實現,使用一臺配備8個NVIDIA V100 GPU的單臺機器進行訓練。輸入視頻幀被調整大小并裁剪到尺寸為224×224的空間。從整個視頻中均勻采樣L = 5幀,并確保最后一幀用于生成邊界框。設置為2。使用AdamW(Loshchilov和Hutter,2017)作為優化器,余弦退火調度器(Loshchilov和Hutter,2016)作為學習率調度器,低分辨率推理分支的初始學習率為1e-4,高分辨率感知分支的初始學習率為4e-4,全局批量大小為64。
數據集。DRAMA(Malla等人,2023)是一個評估駕駛場景中視覺推理的基準,包括17,785個兩秒交互式場景。然而,它只提供有關風險目標的標題,沒有提供有關自車意圖或建議的信息,這對于ROLISP至關重要。為了解決這個問題,增強了注釋,擴展了DRAMA的標題,包括自車意圖和建議,從而產生了DRAMA-ROLISP數據集。
評估指標。ROLISP包括兩個任務:(1)標題以識別和解釋風險目標,同時預測自車意圖和動作,以及(2)風險目標檢測。標題性能遵循標準指標(Malla等人,2023),即BLEU-4(B4),METEOR(M),CIDER(C)和SPICE(S)。使用平均交并比(mIoU)來進行檢測評估。此外,還提供了按物體大小分類的IoU分數:小型(IoUS),中型(IoUM)和大型(IoUL)。
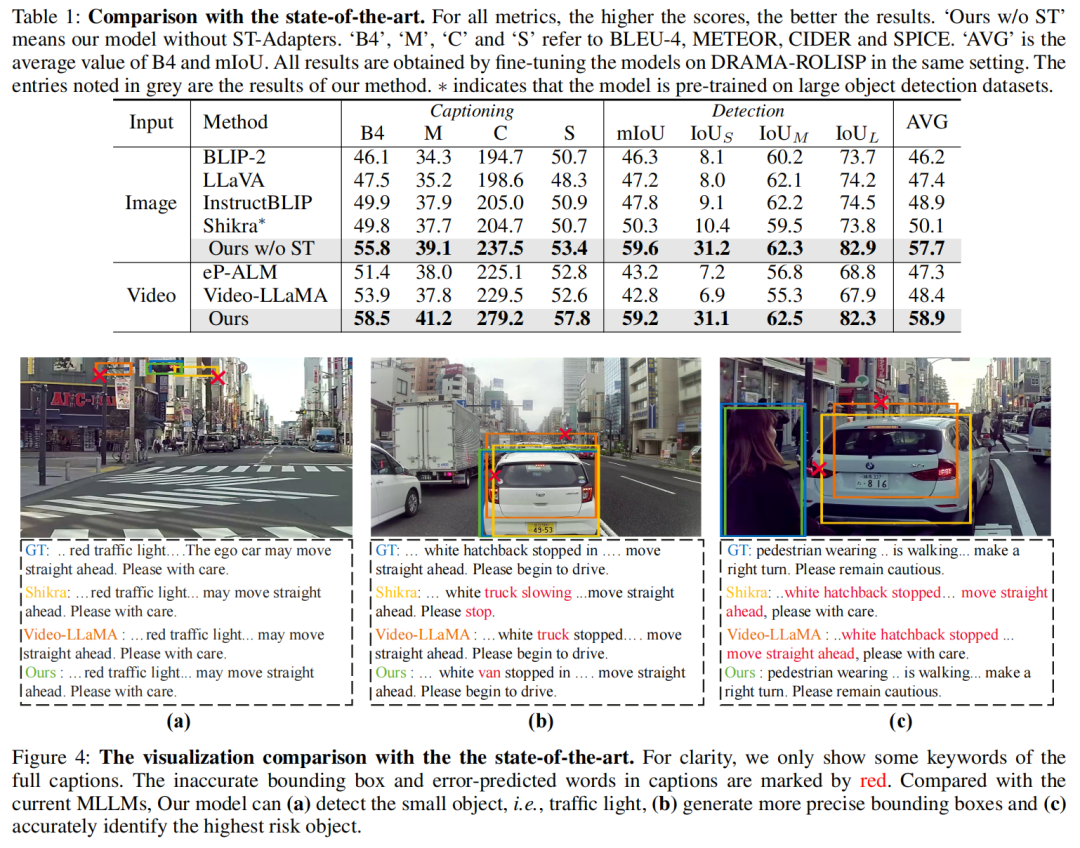
與最先進方法的比較 在DRAMA-ROLISP上進行實驗,與基于圖像和視頻的MLLM進行比較,包括BLIP-2,LLaVA,InstrutBLIP,Shikra,eP-ALM和Video-LLaMA;請注意,除了Shikra,其他模型都無法檢測物體。因此,將檢測頭(基于MLP的)整合到它們中以生成邊界框;
Main Results
最后總結一下
HiLM-D引入了一種新的方法,使用多模態大語言模型(MLLMs)來統一多個駕駛任務,稱為風險目標定位和自車意圖以及建議預測(ROLISP)。進一步提出了HiLM-D,以生成豐富的高分辨率特征圖,其中包含了視覺特定的先驗信息,突出顯示高風險區域,這可以無縫地與現有的MLLM集成并增強其性能。
局限性。值得注意的是,HiLM-D的數據集固有的局限性,每個視頻只包含一個風險目標,這可能無法捕捉真實世界場景的復雜性。此外,該數據集缺乏如雨雪或霧等惡劣天氣條件,這對于全面的自動駕駛評估至關重要。此外,提供的建議通常是簡明的,例如“停車”或“讓行”,這可能過于簡化了可能的行動范圍。未來工作是創建一個更多樣化和具有挑戰性的數據集,進一步推動該領域的發展。
參考:
論文:https://arxiv.org/pdf/2309.05186.pdf
作者單位:The Hong Kong University of Science and Technology, Huawei Noah’s Ark Lab。

原文鏈接:https://mp.weixin.qq.com/s/OFGH64lO88sRuRou5K9HFA





























