













GPT-4V只能排第二!華科大等發(fā)布多模態(tài)大模型新基準:五大任務(wù)14個模型全面測評
近期,多模態(tài)大模型(LMMs)在視覺語言任務(wù)方面展示了令人印象深刻的能力。然而,由于多模態(tài)大模型的回答具有開放性,如何準確評估多模態(tài)大模型各個方面的性能成為一個迫切需要解決的問題。
目前,一些方法采用GPT對答案進行評分,但存在著不準確和主觀性的問題。另外一些方法則通過判斷題和多項選擇題來評估多模態(tài)大模型的能力。
然而,判斷題和選擇題只是在一系列參考答案中選擇最佳答案,不能準確反映多模態(tài)大模型完整識別圖像中文本的能力,目前還缺乏針對多模態(tài)大模型光學(xué)字符識別(OCR)能力的專門評測基準。
近期,華中科技大學(xué)白翔團隊聯(lián)合華南理工大學(xué)、北京科技大學(xué)、中科院和微軟研究院的研究人員對多模態(tài)大模型的OCR能力進行了深入的研究。
并在27個公有數(shù)據(jù)集和2個生成的無語義和對比的有語義的數(shù)據(jù)集上對文字識別、場景文本VQA、文檔VQA、關(guān)鍵信息抽取和手寫數(shù)學(xué)表達式識別這五個任務(wù)上進行了廣泛的實驗。

論文鏈接:https://arxiv.org/abs/2305.07895
代碼地址:https://github.com/Yuliang-Liu/MultimodalOCR
為了方便而準確地評估多模態(tài)大模型的OCR能力,本文還進一步構(gòu)建了用于驗證多模態(tài)大模型零樣本泛化能力的文字領(lǐng)域最全面的評估基準OCRBench,評測了谷歌Gemini,OpenAI GPT4V以及目前開源的多個類GPT4V多模態(tài)大模型,揭示了多模態(tài)大模型直接應(yīng)用在OCR領(lǐng)域的局限。
評測模型概述
本文對谷歌Gemini,OpenAI GPT4V在內(nèi)的14個多模態(tài)大模型進行了評估。
其中BLIP2引入了Q-Former連接視覺和語言模型;Flamingo和OpenFlamingo通過引入新穎的門控交叉注意力層,使得大語言模型具備理解視覺輸入的能力;LLaVA開創(chuàng)性地使用GPT-4生成多模態(tài)指令跟隨數(shù)據(jù),其續(xù)作LLaVA1.5通過改進對齊層和prompt設(shè)計,進一步提升LLaVA的性能。
此外,mPLUG-Owl和mPLUG-Owl2強調(diào)了圖像和文本的模態(tài)協(xié)作;LLaVAR收集了富文本的訓(xùn)練數(shù)據(jù),并使用更高分辨率的CLIP作為視覺編碼器,以增強LLaVA的OCR能力。
BLIVA結(jié)合指令感知特征和全局視覺特征來捕捉更豐富的圖像信息;MiniGPT4V2在訓(xùn)練模型時為不同任務(wù)使用唯一的標識符,以便輕松區(qū)分每個任務(wù)的指令;UniDoc在大規(guī)模的指令跟蹤數(shù)據(jù)集上進行統(tǒng)一的多模態(tài)指令微調(diào),并利用任務(wù)之間的有益交互來提高單獨任務(wù)的性能。
Docpedia直接在頻域而不是像素空間中處理視覺輸入。Monkey通過生成的詳細描述數(shù)據(jù)和高分辨率的模型架構(gòu),低成本地提高了LMM的細節(jié)感知能力。
評測指標及評測數(shù)據(jù)集
LMM生成的回復(fù)通常包含許多解釋性的話語,因此完全精確的匹配或平均歸一化Levenshtein相似度(ANLS)在評估LMM在Zero-Shot場景中的表現(xiàn)時并不適用。
本文為所有數(shù)據(jù)集定義了一個統(tǒng)一而簡單的評估標準,即判斷LMM的輸出是否包含了GT;為了減少假陽性,本文進一步過濾掉所有答案少于4個字符的問答對。
文本識別(Text Recognition)
本文使用廣泛采用的OCR文本識別數(shù)據(jù)集評估LMM。這些數(shù)據(jù)集包括:
(1)常規(guī)文本識別:IIIT5K、SVT、IC13;
(2)不規(guī)則文本識別:IC15、SVTP、CT80、COCOText(COCO)、SCUT-CTW1500(CTW)、Total-Text(TT);
(3)遮擋場景下的文本識別,WOST和HOST;
(4)藝術(shù)字識別:WordArt;
(5)手寫文本識別:IAM;
(6)中文識別:ReCTS;
(7)手寫數(shù)字串識別:ORAND-CAR-2014(CAR-A);
(8)無語義文本(NST)和語義文本(ST):ST數(shù)據(jù)集包含3000張來自IIIT5K字典的單詞圖像,NST數(shù)據(jù)集與ST數(shù)據(jù)集的不同之處在于單詞中字符的順序被打亂而不具備語義。
對于英文單詞識別,本文使用統(tǒng)一的prompt:「what is written in the image?」。對于ReCTS數(shù)據(jù)集中的中文文本則使用「What are the Chinese characters in the image?」作為prompt。對于手寫數(shù)字串,則使用prompt:「what is the number in the image?」。
場景文本問答(Scene Text-Centric VQA)
本文在STVQA、TextVQA、OCRVQA和ESTVQA上進行了實驗。其中ESTVQA數(shù)據(jù)集被分為ESTVQA(CN)和ESTVQA(EN),分別包含中文和英文問答對。
文檔問答(Document-Oriented VQA)
本文在DocVQA、InfographicVQA和ChartQA數(shù)據(jù)集上進行評估,包括了掃描文檔、復(fù)雜海報以及圖表。
關(guān)鍵信息抽取(KIE)
本文在SROIE、FUNSD和POIE數(shù)據(jù)集上進行了實驗,這些數(shù)據(jù)集包括收據(jù)、表單和產(chǎn)品營養(yǎng)成分標簽。KIE要求從圖像中提取key-value對。
為了使LMM能夠準確提取KIE數(shù)據(jù)集中給定key的正確的value,本文針對不同數(shù)據(jù)集設(shè)計了不同prompt。
對于SROIE數(shù)據(jù)集,本文使用以下prompt幫助LMM為「company」,「date」,「address」和「total」生成相應(yīng)的value:「what is the name of the company that issued this receipt?」、「when was this receipt issued?」、「where was this receipt issued?」和「what is the total amount of this receipt?」。
此外,為了獲取FUNSD和POIE中給定key對應(yīng)的value,本文使用prompt:「What is the value for '{key}'?」。
手寫數(shù)學(xué)公式識別(HMER)
評估了 HME100K數(shù)據(jù)集,在評估過程中,本文使用「Please write out the expression of the formula in the image using LaTeX format.」作為prompt。
評測結(jié)果
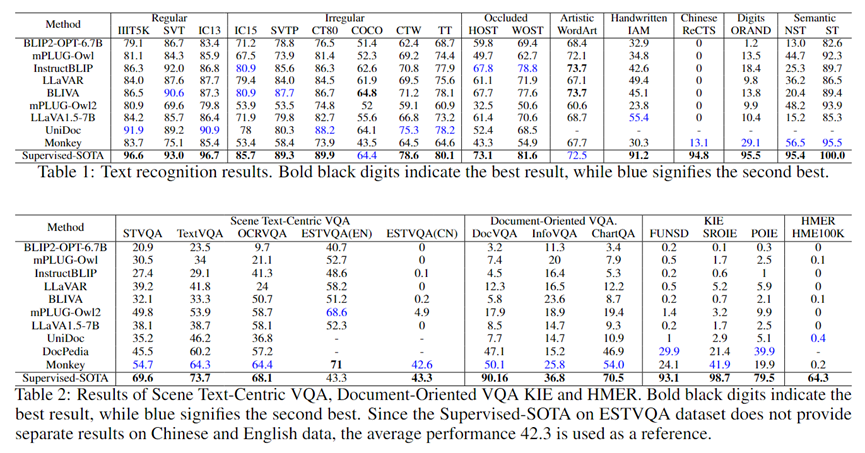
LMM在識別常規(guī)文本、不規(guī)則文本、遮擋場景下的文本和藝術(shù)字方面取得了與Supervised-SOTA相媲美的性能。
InstructBLIP2和BLIVA在WordArt數(shù)據(jù)集中的性能甚至超過了Supervised-SOTA,但LMM仍然存在較大局限。
語義依賴
LMMs在識別缺乏語義的字符組合時表現(xiàn)出較差的識別性能。
具體而言,LMMs在NST數(shù)據(jù)集上的準確率相比于ST數(shù)據(jù)集平均下降了57.0%,而Supervised-SOTA只下降了約4.6%。
這是因為場景文本識別的Supervised-SOTA直接識別每個字符,語義信息僅用于輔助識別過程,而LMMs主要依賴語義理解來識別單詞。
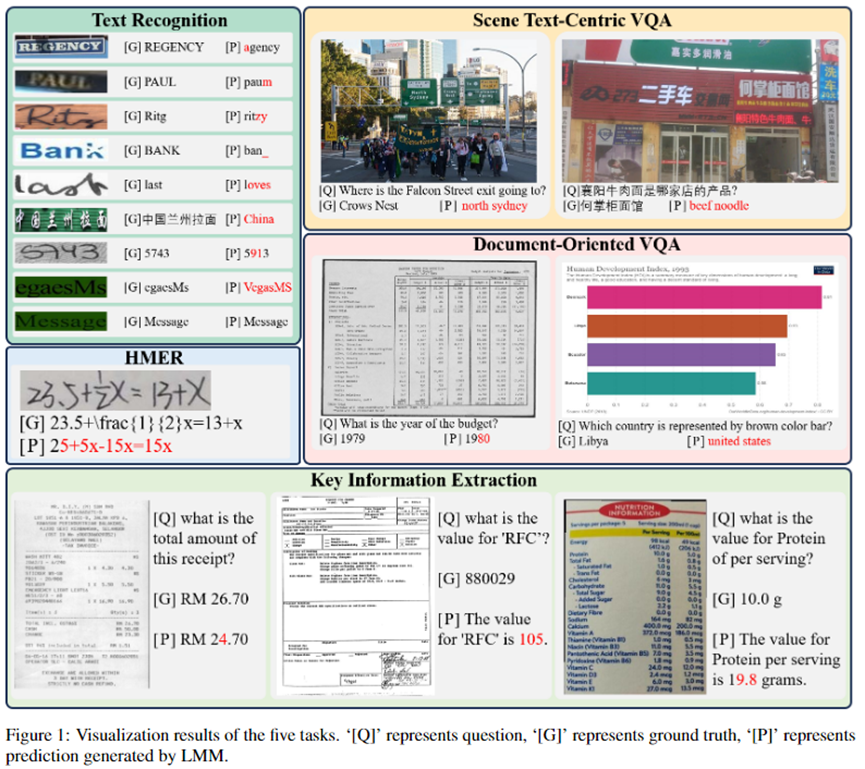
例如Figure1中,LMM成功識別了單詞「Message」,但錯誤地識別了「egaesMs」,這只是單詞「Message」的重新排序。
- 手寫文本
LMMs在準確識別手寫文本方面存在挑戰(zhàn)。手寫文本通常因快速書寫、不規(guī)則手寫或低質(zhì)量紙張等因素而顯得不完整或模糊。平均而言,LMMs在這項任務(wù)中的性能比Supervised-SOTA差了51.9%。
- 多語言文本
在ReCTS、ESTVQA(En)和ESTVQA(Ch)上觀察到的顯著性能差距展示了LMMs在中文文本識別和問答方面的不足。這可能是由于中文訓(xùn)練數(shù)據(jù)的缺少導(dǎo)致的。而Monkey的語言模型和視覺編碼器都經(jīng)過大量中文數(shù)據(jù)的訓(xùn)練,因此它在中文場景中表現(xiàn)優(yōu)于其他多模態(tài)大模型。
- 細粒度感知
目前,大多數(shù)LMMs的輸入圖像分辨率受限于224 x 224,與它們架構(gòu)中使用的視覺編碼器的輸入尺寸一致。然而,高分辨率的輸入圖像可以捕捉到更多的圖像細節(jié),從而提供更細粒度的信息。由于BLIP2等LMMs的輸入分辨率受限,它們在場景文本問答、文檔問答和關(guān)鍵信息抽取等任務(wù)中提取細粒度信息的能力較弱。相比之下,Monkey和 DocPedia等具有更高輸入分辨率的多模態(tài)大模型在這些任務(wù)中具有更好的表現(xiàn)。
- HMER
LMMs在識別手寫數(shù)學(xué)表達式方面存在極大的挑戰(zhàn)。這主要是由于雜亂的手寫字符、復(fù)雜的空間結(jié)構(gòu)、間接的LaTeX表示以及訓(xùn)練數(shù)據(jù)的缺乏所導(dǎo)致的。
OCRBench
完整地評估所有數(shù)據(jù)集可能非常耗時,而且一些數(shù)據(jù)集中的不準確標注使得基于準確率的評估不夠精確。
鑒于這些限制,本文進一步構(gòu)建了OCRBench,以方便而準確地評估LMMs的OCR能力。

OCRBench包含了來自文本識別、場景文本問答、文檔問答、關(guān)鍵信息抽取和手寫數(shù)學(xué)表達式識別這五個任務(wù)的1000個問題-答案對。
對于KIE任務(wù),本文還在提示中進一步添加了「Answer this question using the text in the image directly.」來限制模型的回答格式。
為了確保更準確的評估,本文對OCRBench中的1000個問答對進行了人工校驗,修正了錯誤選項,并提供了正確答案的其他候選。
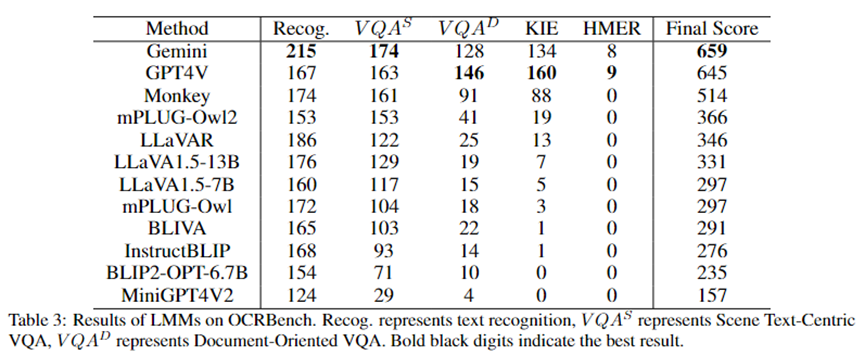
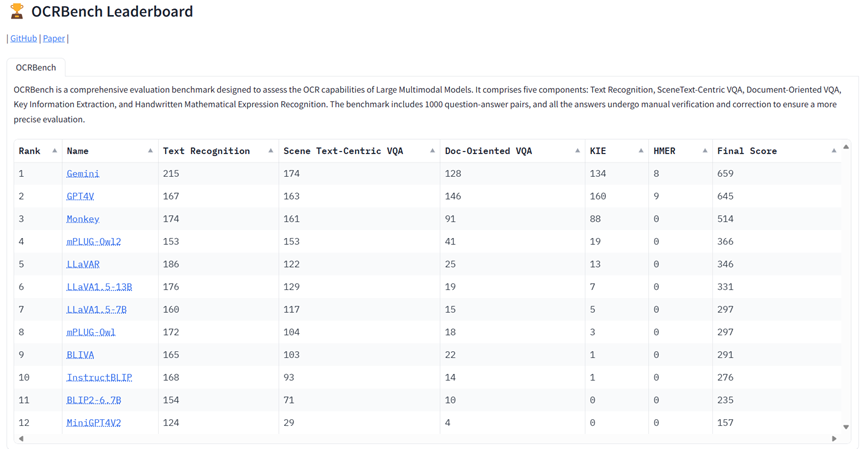
其結(jié)果如Table 3所示,Gemini獲得了最高分,GPT4V獲得了第二名。需要注意的是,由于OpenAI進行了嚴格的安全審查,GPT4V拒絕為OCRBench中的84張圖像提供結(jié)果。
Monkey展示了僅次于GPT4V和Gemini的OCR能力。從測試結(jié)果中,我們可以觀察到,即便是GPT4V和Gemini這樣最先進的多模態(tài)大模型在HMER任務(wù)上也面臨困難。
此外,它們在處理模糊圖像、手寫文本、無語義文本和遵循任務(wù)指令方面也存在挑戰(zhàn)。
正如圖2(g)所示,即使明確要求使用圖像中的文本回答,Gemini仍將「02/02/2018」解釋為「2 February 2018」。
總結(jié)
本文對LMMs在OCR任務(wù)中的性能進行了廣泛的研究,包括文本識別、場景文本問答、文檔問答、KIE和HMER。
本文的定量評估顯示,LMM可以取得有希望的結(jié)果,特別是在文本識別方面,在某些數(shù)據(jù)集上甚至達到了SOTA。
然而,與針對特定領(lǐng)域的監(jiān)督方法相比,仍然存在顯著差距,這表明針對每個任務(wù)定制的專門技術(shù)仍然是必不可少的,因為后者使用的計算資源和數(shù)據(jù)要少得多。
本文所提出的OCRBench為評估多模態(tài)大模型的OCR能力提供了基準,揭示了多模態(tài)大模型直接運用于OCR領(lǐng)域的局限。
本文還為OCRBench構(gòu)建了一個在線排行榜,用于展示和比較不同多模態(tài)大模型的OCR能力(加入排行榜的方式參考Github)。





























