













走在GPT 4.5前面?3D、視頻直接扔進對話框,大模型掌握跨模態推理
給你一首曲子的音頻和一件樂器的 3D 模型,然后問你這件樂器能否演奏出這首曲子。你可以通過聽覺來辨認這首曲子的音色,看它是鋼琴曲還是小提琴曲又或是來自吉他;同時用視覺識別那是件什么樂器。然后你就能得到問題的答案。但語言模型有能力辦到這一點嗎?

實際上,這個任務所需的能力名為跨模態推理,也是當今多模態大模型研究熱潮中一個重要的研究主題。近日,賓夕法尼亞大學、Salesforce 研究院和斯坦福大學的一個研究團隊給出了一個解決方案 X-InstructBLIP,能以較低的成本讓語言模型掌握跨模態推理。
人類天生就會利用多種感官來解讀周圍環境并和制定決策。通過讓人工智能體具備跨模態推理能力,我們可以促進系統的開發,讓其能更全面地理解環境,從而能應對僅有單個模態導致難以辨別模式和執行推理的情況。這就催生了多模態語言模型(MLM),其可將大型語言模型(LLM)的出色能力遷移到靜態視覺領域。
近期一些研究進展的目標是通過整合音頻和視頻來擴展 MLM 的推理能力,其用的方法要么是引入預訓練的跨模態表征來在多個模態上訓練基礎模型,要么是訓練一個投影模型來將多模態與 LLM 的表征空間對齊。這些方法雖然有效,但前者往往需要針對具體任務進行微調,而后者則需要在聯合模態數據上微調模型,這樣一來就需要很多數據收集和計算資源成本。
該研究團隊提出的 X-InstructBLIP 是一個可擴展框架,讓模型可以在學習單模態數據的同時不受預訓練的跨模態嵌入空間或與解凍 LLM 參數相關的計算成本和潛在過擬合風險的限制。

- 論文地址:https://arxiv.org/pdf/2311.18799.pdf
- GitHub 地址:https://github.com/salesforce/LAVIS/
X-InstructBLIP 無縫地整合了多種模態并且這些模態各自獨立,從而不必再使用聯合模態數據集,同時還能保留執行跨模態任務的能力。
據介紹,這種方法使用了 Q-Former 模塊,使用來自 BLIP-2 的圖像 - 文本預訓練權重進行了初始化,并在單模態數據集上進行了微調以將來自不同模態嵌入空間的輸入映射到一個凍結的 LLM。
由于某些模態缺乏指令微調數據,該團隊又提出了一個簡單又有效的方法:一種三階段查詢數據增強技術,能使用開源 LLM 來從字幕描述數據集提取指令微調數據。
圖 2 給出的結果凸顯了這個框架的多功能性。定量分析表明,X-InstructBLIP 的表現與現有的單模態模型相當,并且能在跨模態任務上表現出涌現能力。而為了量化和檢驗這種涌現能力,該團隊又構建了 DisCRn。這是一個自動收集和調整的判別式跨模態推理挑戰數據集,其需要模型分辨不同的模態組合,比如「音頻 - 視頻」和「3D - 圖像」。

方法
圖 1 展示了該模型架構的總體概況:其擴展了 Dai et al. 在 InstructBLIP 項目中提出的指令感知型投影方法,通過獨立微調具體模態的 Q-Former 到一個凍結 LLM 的映射,使其可用于任意數量的模態。

圖 3 展示了這個模態到 LLM 的對齊過程,其中突出強調了與每個模態相關的所有組件。

算法 1 概述了 X-InstructBLIP 對齊框架。

本質上講,對于每一對文本指令和非語言輸入樣本:(1) 使用一個凍結的預訓練編碼器對文本指令進行 token 化,對非文本輸入進行嵌入化。(2) 將非語言輸入的歸一化編碼和 token 化的指令輸入 Q-Former 模塊,并附帶上一組可學習的查詢嵌入。(3) 通過 Q-Former 對這些查詢嵌入進行變換,通過 transformer 模塊的交替層中的跨注意力層來條件式地適應這些輸入。(4) 通過一個可訓練的線性層將修改后的查詢嵌入投影到凍結 LLM 的嵌入空間。
數據集
X-InstructBLIP 的優化和評估使用了之前已有的數據集和自動生成的數據集,如圖 4 所示。

對數據集進行微調
對于已有的數據集,研究者對它們進行了一些微調,詳見原論文。
此外,他們還對指令數據進行了增強。由于他們尤其需要 3D 和音頻模態的數據,于是他們使用開源大型語言模型 google/flan-t5-xxl 基于相應的字幕描述自動生成了 3D 和音頻模態的問答對。這個過程最終從 Cap3D 的 3D 數據得到了大約 25 萬個示例,從 AudioCaps 的音頻數據得到了大約 2.4 萬個示例。
判別式跨模態推理
X-InstructBLIP 明顯展現出了一個涌現能力:盡管訓練是分模態進行的,但它卻能跨模態推理。這凸顯了該模型的多功能性以及潛在的跨大量模態的可擴展性。為了研究這種跨模態推理能力,該團隊構建了一個判別式跨模態推理挑戰數據集 DisCRn。
如圖 5 所示,該任務需要模型跨模態分辨兩個實體的性質,做法是選出哪個模態滿足查詢的性質。該任務要求模型不僅能分辨所涉模態的內在特征,而且還要考慮它們在輸入中的相對位置。這一策略有助于讓模型不再依賴于簡單的文本匹配啟發式特征、順序偏差或潛在的欺騙性相關性。

為了生成這個數據集,研究者再次使用了增強指令數據時用過的 google/flan-t5-xxl 模型。
在生成過程中,首先是通過思維鏈方式為語言模型提供 prompt,從而為每個數據集實例生成一組屬性。然后,通過三個上下文示例使用語言模型,使之能利用上下文學習,讓每個實例都與數據集中的一個隨機實例配對,以構建一個 (問題,答案,解釋) 三元組。
在這個數據集創建過程中,一個關鍵步驟是反復進行的一致性檢查:給定字幕說明上,只有當模型對生成問題的預測結果與示例答案匹配時(Levenshtein 距離超過 0.9),該示例才會被加入到最終數據集中。
這個優化調整后的數據集包含 8802 個來自 AudioCaps 驗證集的音頻 - 視頻樣本以及來自 Cap3D 的包含 5k 點云數據的留存子集的 29072 個圖像 - 點云實例。該數據集中每個實例都組合了兩個對應于字幕說明的表征:來自 AudioCaps 的 (音頻,視頻) 和來自 Cap3D 的 (點云,圖像)。
實驗
該團隊研究了能否將 X-InstructBLIP 有效地用作將跨模態整合進預訓練凍結 LLM 的綜合解決方案。
實現細節
X-InstructBLIP 的構建使用了 LAVIS 軟件庫的框架,基于 Vicuna v1.1 7b 和 13b 模型。每個 Q-Former 優化 188M 個可訓練參數并學習 K=32 個隱藏維度大小為 768 的查詢 token。表 1 列出了用于每種模態的凍結預訓練編碼器。

優化模型的硬件是 8 臺 A100 40GB GPU,使用了 AdamW。
結果
在展示的結果中,加下劃線的數值表示領域內的評估結果。粗體數值表示最佳的零樣本性能。藍色數值表示第二好的零樣本性能。
對各個模態的理解

該團隊在一系列單模態到文本任務上評估了 X-InstructBLIP 的性能,結果展現了其多功能性,即能有效應對實驗中的所有四種模態。表 2、3、4 和 6 總結了 X-InstructBLIP 在 3D、音頻、圖像和無聲視頻模態上的領域外性能。




跨模態聯合推理
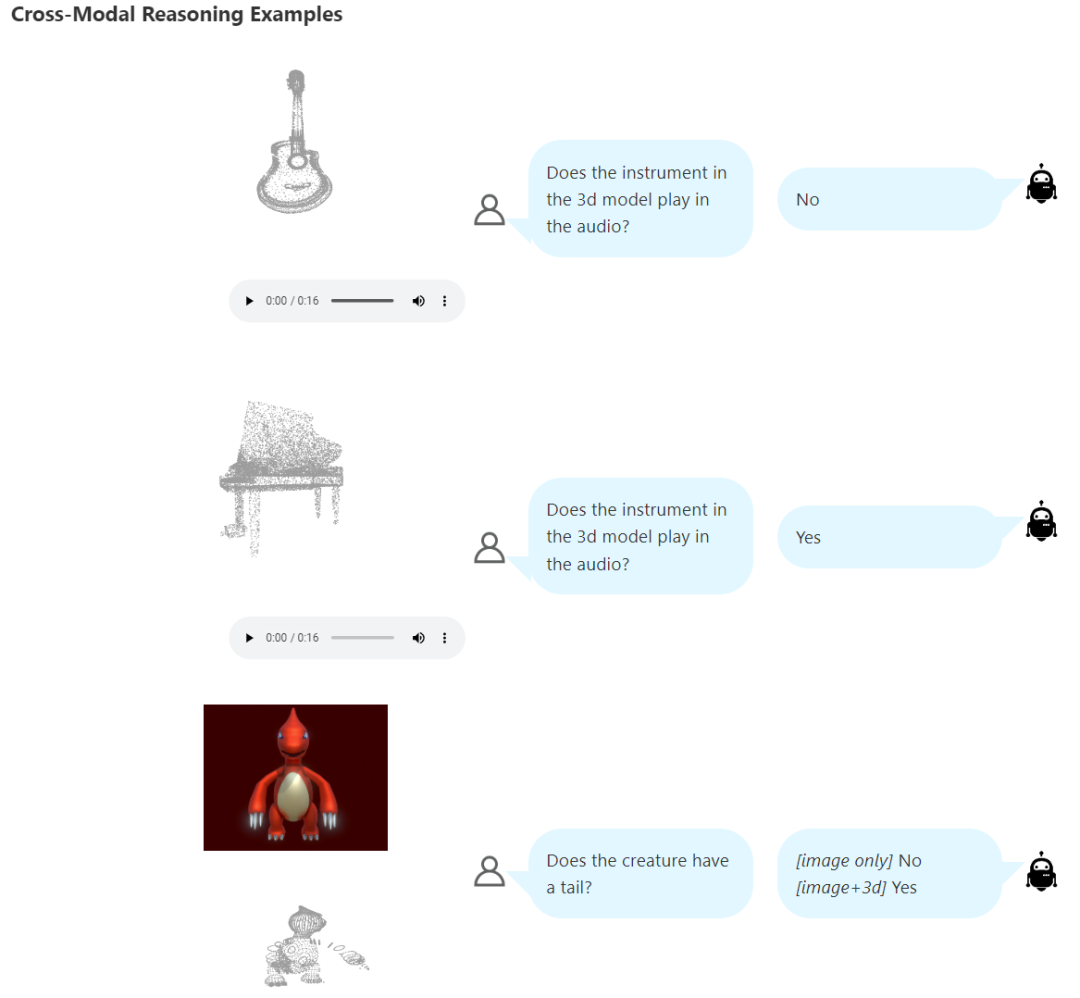
盡管 X-InstructBLIP 的每個模態投影都是分開訓練的,但它卻展現出了很強的聯合模態推理能力。表 7 展示了 X-InstructBLIP 在視頻 (V) 和音頻 (A) 上執行聯合推理的能力。

值得注意的是,X-InstructBLIP 具備協調統籌輸入的能力,因為當同時使用 MusicAVQA 和 VATEX Captioning 中的不同模態作為線索時,模型在使用多模態時的表現勝過使用單模態。但是,這個行為與模型沒有前綴提示的模型不一致。
一開始的時候,理論上認為模型沒有能力區分對應每種模態的 token,而是將它們看作是連續流。這可能是原因。但是,來自圖像 - 3D 跨模態推理任務的結果卻對這一看法構成了挑戰 —— 其中沒有前綴的模型超過有前綴的模型 10 個點。似乎包含線索可能會讓模型對特定于模態的信息進行編碼,這在聯合推理場景中是有益的。
但是,這種針對性的編碼并不能讓模型識別和處理通常與其它模態相關的特征,而這些特征卻是增強對比任務性能所需的。其根本原因是:語言模型已經過調整,就是為了生成與模態相關的輸出,這就導致 Q-Former 在訓練期間主要接收與特定于模態的生成相關的反饋。這一機制還可以解釋模型在單模態任務上出人意料的性能提升。
跨模態判別式推理
該團隊使用新提出的 DisCRn 基準評估了 X-InstructBLIP 在不同模態上執行判別式推理的能力。他們將該問題描述成了一個現實的開放式生成問題。在給 LLM 的 prompt 中會加上如下前綴:
在向 X-InstructBLIP (7b) 輸入 prompt 時,該團隊發現:使用 Q-Former 字幕描述 prompt(這不同于提供給 LLM 模型的比較式 prompt)會導致得到一種更適用于比較任務的更通用的表征,因此他們采用這種方法得到了表 8 的結果。其原因很可能是微調過程中缺乏比較數據,因為每個模態的 Q-Former 都是分開訓練的。

為了對新提出的模型進行基準測試,該團隊整合了一個穩健的字幕描述基準,其做法是使用 Vicuna 7b 模型用對應于各模態的字幕描述來替換查詢輸出。對于圖像、3D 和視頻模態,他們的做法是向 InstructBLIP 輸入 prompt 使其描述圖像 / 視頻,從而得出字幕描述。對于 3D 輸入,輸入給 InstructBLIP 的是其點云的一個隨機選取的渲染視圖。
結果可以看到,在準確度方面,X-InstructBLIP 分別優于音頻 - 視頻和圖像 - 3D 基準模型 3.2 和 7.7 個百分點。用等價的線性投影模塊替換其中一個 Q-Former 后,圖像 - 3D 的性能會下降一半以上,音頻 - 視頻的性能會下降超過 10 個點。























