穿越時間的引擎:解密 Kafka 消息的時序之謎

一、概括
1、介紹 Kafka 消息延遲和時序性
Kafka 消息延遲和時序性對于大多數實時數據流應用程序至關重要。本章將深入介紹這兩個核心概念,它們是了解 Kafka 數據流處理的關鍵要素。
(1)什么是 Kafka 消息延遲?
Kafka 消息延遲是指消息從生產者發送到消息被消費者接收之間的時間差。這是一個關鍵的概念,因為它直接影響到數據流應用程序的實時性和性能。在理想情況下,消息應該以最小的延遲被傳遞,但在實際情況中,延遲可能會受到多種因素的影響。
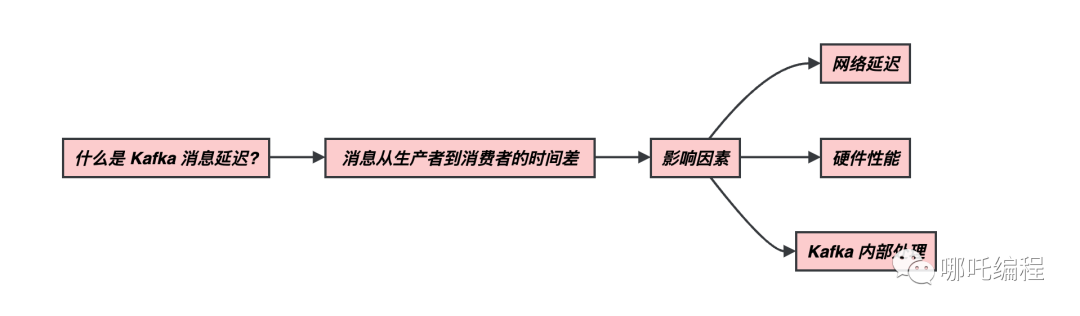
消息延遲的因素包括:
- 網絡延遲:消息必須通過網絡傳輸到 Kafka 集群,然后再傳輸到消費者。網絡延遲可能會受到網絡拓撲、帶寬和路由等因素的影響。
- 硬件性能:Kafka 集群的硬件性能,包括磁盤、內存和 CPU 的速度,會影響消息的寫入和讀取速度。
- Kafka 內部處理:Kafka 集群的內部處理能力也是一個關鍵因素。消息必須經過分區、日志段和復制等處理步驟,這可能會引入一些處理延遲。
(2)為什么消息延遲很重要?
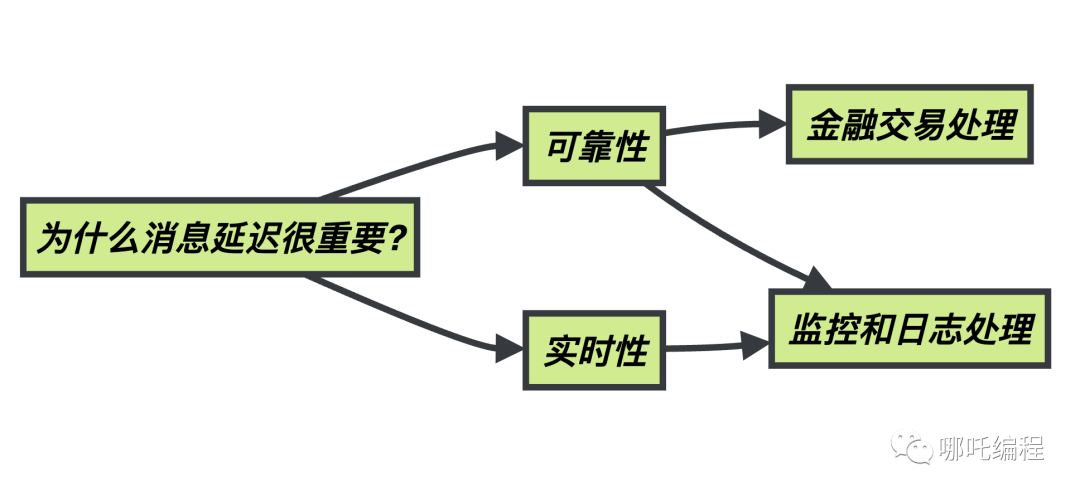
消息延遲之所以如此重要,是因為它直接關系到實時數據處理應用程序的可靠性和實時性。在一些應用中,如金融交易處理,甚至毫秒級的延遲都可能導致交易失敗或不一致。在監控和日志處理應用中,過高的延遲可能導致數據不準確或失去了時序性。
管理和優化 Kafka 消息延遲是確保應用程序在高負載下仍能快速響應的關鍵因素。不僅需要了解延遲的來源,還需要采取相應的優化策略。
(3)什么是 Kafka 消息時序性?
Kafka 消息時序性是指消息按照它們發送的順序被接收。這意味著如果消息 A 在消息 B 之前發送,那么消息 A 應該在消息 B 之前被消費。保持消息的時序性對于需要按照時間順序處理的應用程序至關重要。
維護消息時序性是 Kafka 的一個強大特性。在 Kafka 中,每個分區都可以保證消息的時序性,因為每個分區內的消息是有序的。然而,在多個分區的情況下,時序性可能會受到消費者處理速度不一致的影響,因此需要采取一些策略來維護全局的消息時序性。
(4)消息延遲和時序性的關系
消息延遲和消息時序性之間存在密切的關系。如果消息延遲過大,可能會導致消息失去時序性,因為一條晚到的消息可能會在一條早到的消息之前被處理。因此,了解如何管理消息延遲也包括了維護消息時序性。
在接下來的章節中,我們將深入探討如何管理和優化 Kafka 消息延遲,以及如何維護消息時序性,以滿足實時數據處理應用程序的需求。
2、延遲的來源
為了有效地管理和優化 Kafka 消息延遲,我們需要深入了解延遲可能來自哪些方面。下面是一些常見的延遲來源:
(1)Kafka 內部延遲
Kafka 內部延遲是指與 Kafka 內部組件和分區分配相關的延遲。這些因素可能會影響消息在 Kafka 內部的分發、復制和再平衡。
- 分區分布不均:如果分區分布不均勻,某些分區可能會變得擁擠,而其他分區可能會滯后,導致消息傳遞延遲。
- 復制延遲:在 Kafka 中,消息通常會進行復制以確保冗余。復制延遲是指主題的所有副本都能復制消息所需的時間。
- 再平衡延遲:當 Kafka 集群發生再平衡時,消息的重新分配和復制可能導致消息傳遞延遲。
二、衡量和監控消息延遲
在本節中,我們將深入探討如何度量和監控 Kafka 消息延遲,這將幫助你更好地了解問題并采取相應的措施來提高延遲性能。
1、延遲的度量
為了有效地管理 Kafka 消息延遲,首先需要能夠度量它。下面是一些常見的延遲度量方式:
(1)生產者到 Kafka 延遲
這是指消息從生產者發送到 Kafka 集群之間的延遲。為了度量這一延遲,你可以采取以下方法:
- 記錄發送時間戳:在生產者端,記錄每條消息的發送時間戳。一旦消息成功寫入 Kafka,記錄接收時間戳。然后,通過將這兩個時間戳相減,你可以獲得消息的生產者到 Kafka 的延遲。
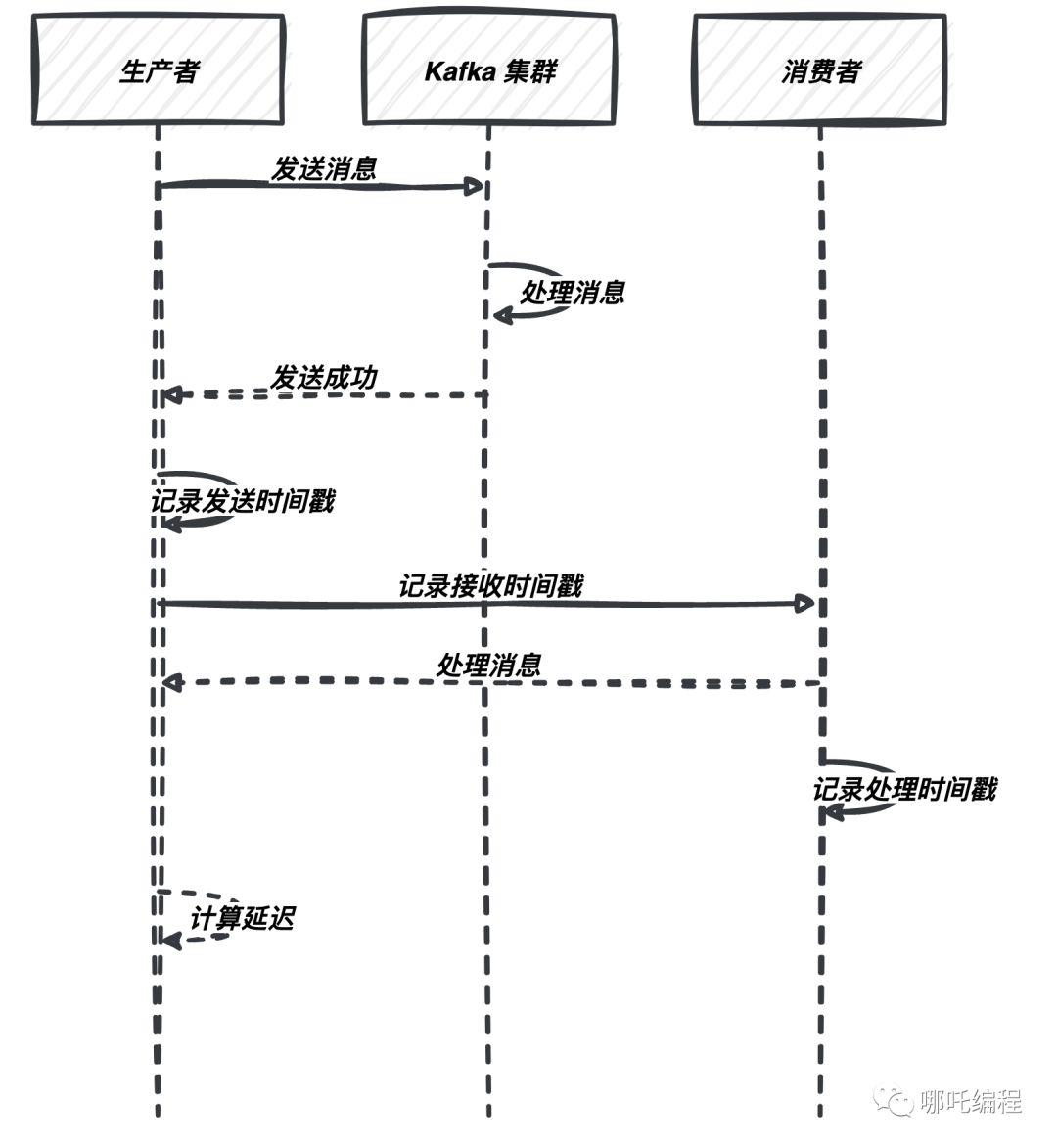
以下是如何記錄發送和接收時間戳的代碼示例:
// 記錄消息發送時間戳
long sendTimestamp = System.currentTimeMillis();
ProducerRecord<String, String> record = new ProducerRecord<>("my_topic", "key", "value");
producer.send(record, (metadata, exception) -> {
if (exception == null) {
long receiveTimestamp = System.currentTimeMillis();
long producerToKafkaLatency = receiveTimestamp - sendTimestamp;
System.out.println("生產者到 Kafka 延遲:" + producerToKafkaLatency + " 毫秒");
} else {
System.err.println("消息發送失敗: " + exception.getMessage());
}
});(2)Kafka 內部延遲
Kafka 內部延遲是指消息在 Kafka 集群內部傳遞的延遲。你可以使用 Kafka 內置度量來度量它,包括:
- Log End-to-End Latency:這是度量消息從生產者發送到消費者接收的總延遲。它包括了網絡傳輸、分區復制、再平衡等各個環節的時間。
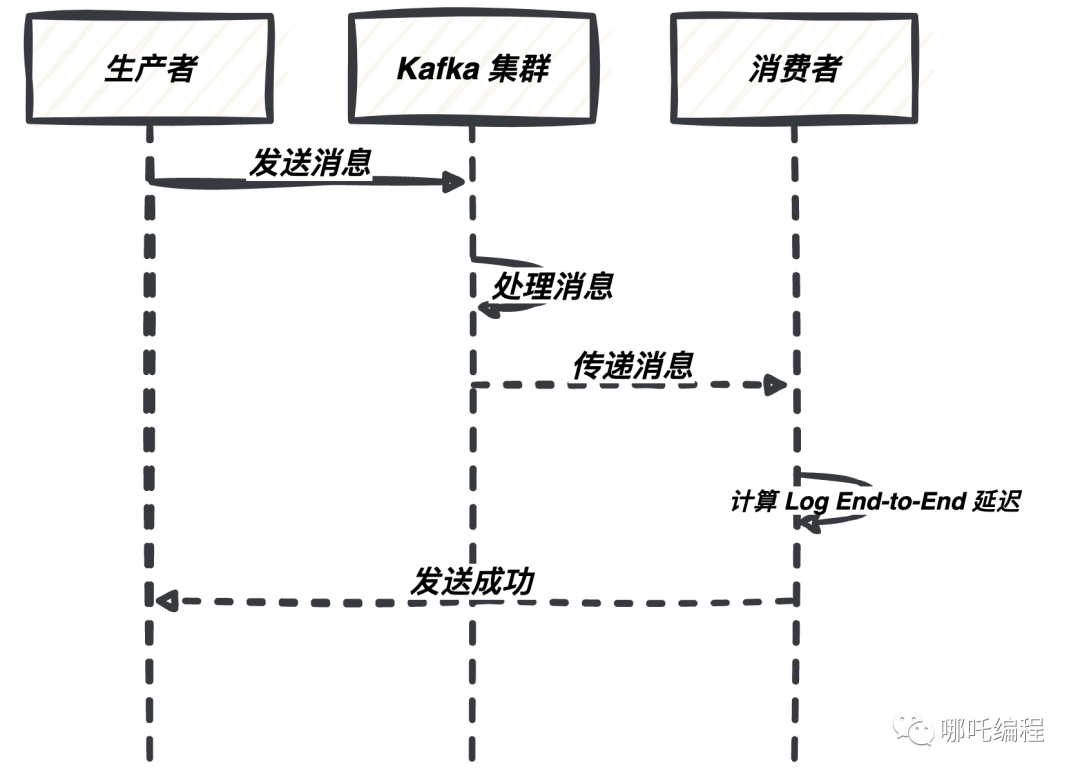
以下是一個示例:
// 創建 Kafka 消費者
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "kafka-broker:9092");
consumerProps.put("group.id", "my-group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
// 訂閱主題
consumer.subscribe(Collections.singletonList("my_topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long endToEndLatency = record.timestamp() - record.timestampType().createTimestamp();
System.out.println("Log End-to-End 延遲:" + endToEndLatency + " 毫秒");
}
}(3)消費者處理延遲
消費者處理延遲是指消息從 Kafka 接收到被消費者實際處理的時間。為了度量這一延遲,你可以采取以下方法:
- 記錄消費時間戳:在消費者端,記錄每條消息的接收時間戳和處理時間戳。通過計算這兩個時間戳的差值,你可以得到消息的消費者處理延遲。
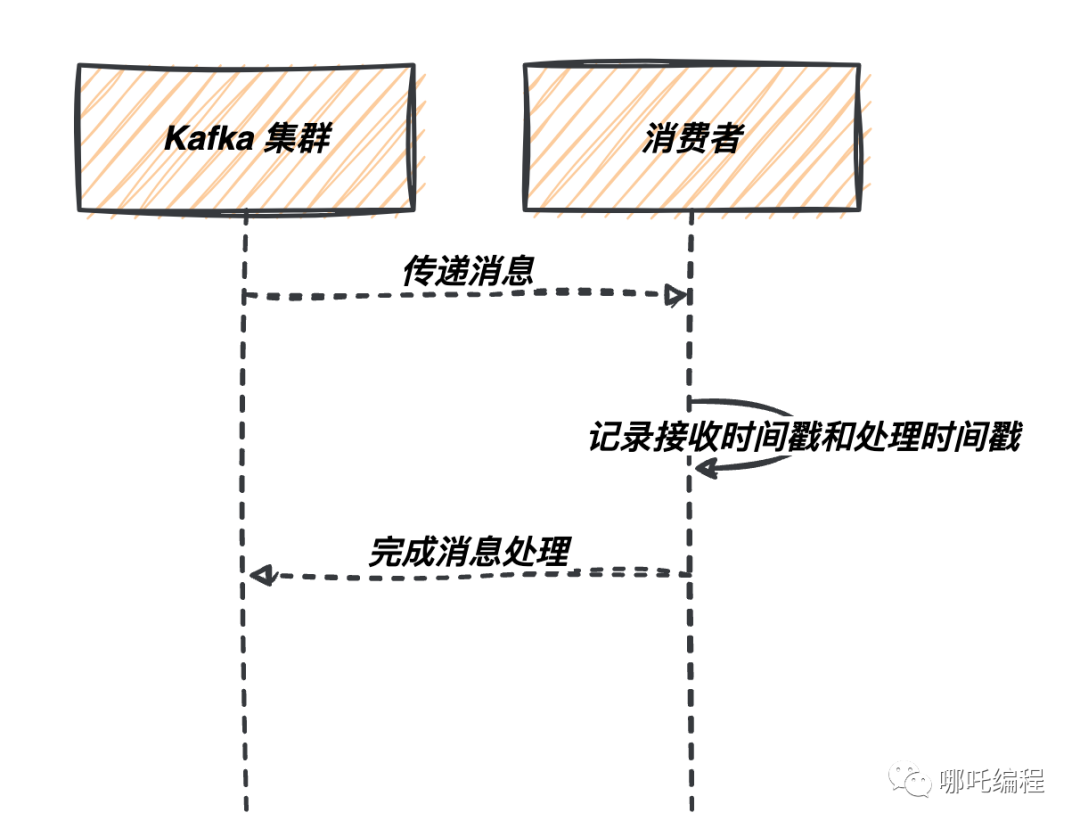
以下是如何記錄消費時間戳的代碼示例:
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList("my_topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long receiveTimestamp = System.currentTimeMillis();
long consumerProcessingLatency = receiveTimestamp - record.timestamp();
System.out.println("消費者處理延遲:" + consumerProcessingLatency + " 毫秒");
}
}2、監控和度量工具
在度量和監控 Kafka 消息延遲時,使用適當的工具和系統是至關重要的。下面是一些工具和步驟,幫助你有效地監控 Kafka 消息延遲,包括代碼示例:
(1)Kafka 內置度量
Kafka 提供了內置度量,可通過多種方式來監控。以下是一些示例,演示如何通過 Kafka 的 JMX 界面訪問這些度量:
使用 JConsole 直接連接到 Kafka Broker:
- 啟動 Kafka Broker。
- 打開 JConsole(Java 監控與管理控制臺)。
- 在 JConsole 中選擇 Kafka Broker 進程。
- 導航到 "kafka.server" 和 "kafka.consumer",以查看各種度量。
使用 Jolokia(Kafka JMX HTTP Bridge):
- 啟用 Jolokia 作為 Kafka Broker 的 JMX HTTP Bridge。
- 使用 Web 瀏覽器或 HTTP 請求訪問 Jolokia 接口來獲取度量數據。例如,使用 cURL 進行 HTTP GET 請求:
curl http://localhost:8778/jolokia/read/kafka.server:name=BrokerTopicMetrics/TotalFetchRequestsPerSec這將返回有關 Kafka Broker 主題度量的信息。
(2)第三方監控工具
除了 Kafka 內置度量,你還可以使用第三方監控工具,如 Prometheus 和 Grafana,來收集、可視化和警報度量數據。以下是一些步驟:
配置 Prometheus:
- 部署和配置 Prometheus 服務器。
- 創建用于監控 Kafka 的 Prometheus 配置文件,定義抓取度量數據的頻率和目標。
- 啟動 Prometheus 服務器。
設置 Grafana 儀表板:
- 部署和配置 Grafana 服務器。
- 在 Grafana 中創建儀表板,使用 Prometheus 作為數據源。
- 添加度量查詢,配置警報規則和可視化圖表。
可視化 Kafka 延遲數據:
在 Grafana 儀表板中,你可以設置不同的圖表來可視化 Kafka 延遲數據,例如生產者到 Kafka 延遲、消費者處理延遲等。通過設置警報規則,你還可以及時收到通知,以便采取行動。
(3)配置和使用監控工具
為了配置和使用監控工具,你需要執行以下步驟:
定義度量指標:確定你要度量的關鍵度量指標,如生產者到 Kafka 延遲、消費者處理延遲等。
設置警報規則:為了快速響應問題,設置警報規則,以便在度量數據超出預定閾值時接收通知。
創建可視化儀表板:使用監控工具(如 Grafana)創建可視化儀表板,以集中展示度量數據并實時監測延遲情況。可配置的圖表和儀表板有助于更好地理解數據趨勢。
以上步驟和工具將幫助你更好地度量和監控 Kafka 消息延遲,以及及時采取行動來維護系統的性能和可靠性。
三、降低消息延遲
既然我們了解了 Kafka 消息延遲的來源以及如何度量和監控它,讓我們繼續探討如何降低消息延遲。以下是一些有效的實踐方法,可以幫助你減少 Kafka 消息延遲:
1、優化 Kafka 配置
(1)Producer 和 Consumer 參數
生產者參數示例:
# 生產者參數示例
acks=all
compression.type=snappy
linger.ms=20
max.in.flight.requests.per.cnotallow=1- acks 設置為 all,以確保生產者等待來自所有分區副本的確認。這提高了可靠性,但可能增加了延遲。
- compression.type 使用 Snappy 壓縮消息,減小了網絡傳輸延遲。
- linger.ms 設置為 20 毫秒,以允許生產者在發送消息之前等待更多消息。這有助于減少短暫的消息發送延遲。
- max.in.flight.requests.per.connection 設置為 1,以確保在收到分區副本的確認之前不會發送新的消息。
消費者參數示例:
# 消費者參數示例
max.poll.records=500
fetch.min.bytes=1
fetch.max.wait.ms=100
enable.auto.commit=false- max.poll.records 設置為 500,以一次性拉取多條消息,提高吞吐量。
- fetch.min.bytes 設置為 1,以確保即使沒有足夠數據,也立即拉取消息。
- fetch.max.wait.ms 設置為 100 毫秒,以限制拉取消息的等待時間。
- enable.auto.commit 禁用自動提交位移,以確保精確控制消息的確認。
(2)Broker 參數
優化 Kafka broker 參數可以提高整體性能。以下是示例:
# Kafka Broker 參數示例
num.network.threads=3
num.io.threads=8
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000- num.network.threads 和 num.io.threads 設置為適當的值,以充分利用硬件資源。
- log.segment.bytes 設置為 1 GB,以充分利用磁盤性能。
- log.retention.check.interval.ms 設置為 300,000 毫秒,以降低清理日志段的頻率。
(3)Topic 參數
優化每個主題的參數以滿足應用程序需求也很重要。以下是示例:
# 創建 Kafka 主題并設置參數示例
kafka-topics.sh --create --topic my_topic --partitions 8 --replication-factor 2 --config cleanup.policy=compact- --partitions 8 設置分區數量為 8,以提高并行性。
- --replication-factor 2 設置復制因子為 2,以提高可靠性。
- --config cleanup.policy=compact 設置清理策略為壓縮策略,以減小數據保留成本。
通過適當配置這些參數,你可以有效地優化 Kafka 配置以降低消息延遲并提高性能。請根據你的應用程序需求和硬件資源進行調整。
2、編寫高效的生產者和消費者
最后,編寫高效的 Kafka 生產者和消費者代碼對于降低延遲至關重要。以下是一些最佳實踐:
(1)生產者最佳實踐
- 使用異步發送:將多個消息批量發送,而不是逐條發送。這可以減少網絡通信的次數,提高吞吐量。
- 使用 Kafka 生產者的緩沖機制:充分利用 Kafka 生產者的緩沖功能,以減少網絡通信次數。
- 使用分區鍵:通過選擇合適的分區鍵,確保數據均勻分布在不同的分區上,從而提高并行性。
(2)消費者最佳實踐
- 使用多線程消費:啟用多個消費者線程,以便并行處理消息。這可以提高處理能力和降低延遲。
- 調整消費者參數:調整消費者參數,如
fetch.min.bytes和fetch.max.wait.ms,以平衡吞吐量和延遲。 - 使用消息批處理:將一批消息一起處理,以減小處理開銷。
(3)數據序列化
選擇高效的數據序列化格式對于降低數據傳輸和存儲開銷很重要。以下是一些建議的格式:
- Avro:Apache Avro 是一種數據序列化框架,具有高度壓縮和高性能的特點。它適用于大規模數據處理。
- Protocol Buffers:Google Protocol Buffers(ProtoBuf)是一種輕量級的二進制數據格式,具有出色的性能和緊湊的數據表示。
四、Kafka 消息時序性
消息時序性是大多數實時數據流應用程序的核心要求。在本節中,我們將深入探討消息時序性的概念、為何它如此重要以及如何保障消息時序性。
1、什么是消息時序性?
消息時序性是指消息按照它們發送的順序被接收和處理的特性。在 Kafka 中,每個分區內的消息是有序的,這意味著消息以它們被生產者發送的順序排列。然而,跨越多個分區的消息需要額外的工作來保持它們的時序性。
(1)為何消息時序性重要?
消息時序性對于許多應用程序至關重要,特別是需要按照時間順序處理數據的應用。以下是一些應用領域,消息時序性非常關鍵:
- 金融領域:在金融交易中,確保交易按照它們發生的確切順序進行處理至關重要。任何失去時序性的交易可能會導致不一致性或錯誤的交易。
- 日志記錄:在日志記錄和監控應用程序中,事件的時序性對于分析和排查問題非常關鍵。失去事件的時序性可能會導致混淆和數據不準確。
- 電商應用:在線商店的訂單處理需要確保訂單的創建、支付和發貨等步驟按照正確的順序進行,以避免訂單混亂和不準確。
2、保障消息時序性
在分布式系統中,保障消息時序性可能會面臨一些挑戰,特別是在跨越多個分區的情況下。以下是一些策略和最佳實踐,可幫助你確保消息時序性:
(1)分區和消息排序
使用合適的分區策略對消息進行排序,以確保相關的消息被發送到同一個分區。這樣可以維護消息在單個分區內的順序性。對于需要按照特定鍵排序的消息,可以使用自定義分區器來實現。
以下是如何使用合適的分區策略對消息進行排序的代碼示例:
// 自定義分區器,確保相關消息基于特定鍵被發送到同一個分區
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 在此處根據 key 的某種規則計算分區編號
// 例如,可以使用哈希函數或其他方法
int numPartitions = cluster.partitionsForTopic(topic).size();
return Math.abs(key.hashCode()) % numPartitions;
}
@Override
public void close() {
// 可選的資源清理
}
@Override
public void configure(Map<String, ?> configs) {
// 可選的配置
}
}(2)數據一致性
確保生產者發送的消息是有序的。這可能需要在應用程序層面實施,包括對消息進行緩沖、排序和合并,以確保它們按照正確的順序發送到 Kafka。
以下是如何確保數據一致性的代碼示例:
// 生產者端的消息排序
ProducerRecord<String, String> record1 = new ProducerRecord<>("my-topic", "key1", "message1");
ProducerRecord<String, String> record2 = new ProducerRecord<>("my-topic", "key2", "message2");
// 發送消息
producer.send(record1);
producer.send(record2);
// 消費者端保證消息按照鍵排序
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 處理消息,確保按照鍵的順序進行
}(3)消費者并行性
在消費者端,使用適當的線程和分區分配來確保消息以正確的順序處理。這可能涉及消費者線程數量的管理以及確保每個線程只處理一個分區,以避免順序混亂。
以下是如何確保消費者并行性的代碼示例:
// 創建具有多個消費者線程的 Kafka 消費者
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "kafka-broker:9092");
consumerProps.put("group.id", "my-group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 創建 Kafka 消費者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
// 訂閱主題
consumer.subscribe(Collections.singletonList("my-topic"));
// 創建多個消費者線程
int numThreads = 3;
for (int i = 0; i < numThreads; i++) {
Runnable consumerThread = new ConsumerThread(consumer);
new Thread(consumerThread).start();
}五、總結
在本篇技術博客中,我們深入探討了 Kafka 消息延遲和時序性的重要性以及如何度量、監控和降低消息延遲。我們還討論了消息時序性的挑戰和如何確保消息時序性。對于構建實時數據流應用程序的開發人員來說,深入理解這些概念是至關重要的。通過合理配置 Kafka、優化網絡和硬件、編寫高效的生產者和消費者代碼,以及維護消息時序性,你可以構建出高性能和可靠的數據流系統。
無論你的應用是金融交易、監控、日志記錄還是其他領域,這些建議和最佳實踐都將幫助你更好地處理 Kafka 消息延遲和時序性的挑戰,確保數據的可靠性和一致性。