













超逼真!實時高質量渲染,用于動態城市場景建模的Street Gaussians
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
不得不說,技術更新太快了,Nerf在學術界慢慢被替換下去了。Gaussians登場了,浙江大學的工作
論文:Street Gaussians for Modeling Dynamic Urban Scenes
鏈接:https://arxiv.org/pdf/2401.01339.pdf
本文旨在解決從單目視頻中建模動態城市街道場景的問題。最近的方法擴展了NeRF,將跟蹤車輛姿態納入animate vehicles,實現了動態城市街道場景的照片逼真視圖合成。然而,它們的顯著局限性在于訓練和渲染速度慢,再加上跟蹤車輛姿態對高精度的迫切需求。這篇論文介紹了Street Gaussians,一種新的明確的場景表示,它解決了所有這些限制。具體地說,動態城市街道被表示為一組點云,這些點云配備有語義logits和3D Gaussians,每一個都與前景車輛或背景相關聯。
為了對前景對象車輛的動力學進行建模,使用可優化的跟蹤姿態以及動態外觀的動態球面諧波模型對每個對象點云進行優化。顯式表示允許簡單地合成目標車輛和背景,這反過來又允許在半小時的訓練內以133 FPS(1066×1600分辨率)進行場景編輯操作和渲染。所提出的方法在多個具有挑戰性的基準上進行了評估,包括KITTI和Waymo Open數據集。
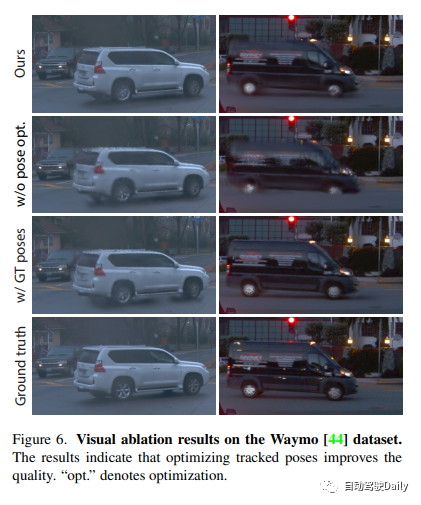
實驗表明,所提出的方法在所有數據集上始終優于現有技術的方法。此外,盡管僅依賴于現成跟蹤器的pose,但所提出的表示提供的性能與使用GT pose所實現的性能不相上下。
代碼:https://zju3dv.github.io/streetgaussians/
Street Gaussians方法介紹
給定從城市街道場景中的移動車輛捕獲的一系列圖像,本文的目標是開發一個能夠為任何給定的輸入時間步長和任何視點生成真實感圖像的模型。為了實現這一目標,提出了一種新的場景表示,命名為Street Gaussians,專門用于表示動態街道場景。如圖2所示,將動態城市街道場景表示為一組點云,每個點云對應于靜態背景或移動車輛。顯式基于點的表示允許簡單地合成單獨的模型,從而實現實時渲染以及編輯應用程序的前景對象分解。僅使用RGB圖像以及現成跟蹤器的跟蹤車輛姿態,就可以有效地訓練所提出的場景表示,通過我們的tracked車輛姿態優化策略進行了增強。
Street Gaussians概覽如下所示,動態城市街道場景表示為一組具有可優化tracked車輛姿態的基于點的背景和前景目標。每個點都分配有3D高斯,包括位置、不透明度和由旋轉和比例組成的協方差,以表示幾何體。為了表示apperence,為每個背景點分配一個球面諧波模型,而前景點與一個動態球面諧波模型相關聯。顯式的基于點的表示允許簡單地組合單獨的模型,這使得能夠實時渲染高質量的圖像和語義圖(如果在訓練期間提供2D語義信息,則是可選的),以及分解前景目標以編輯應用程序

實驗結果對比
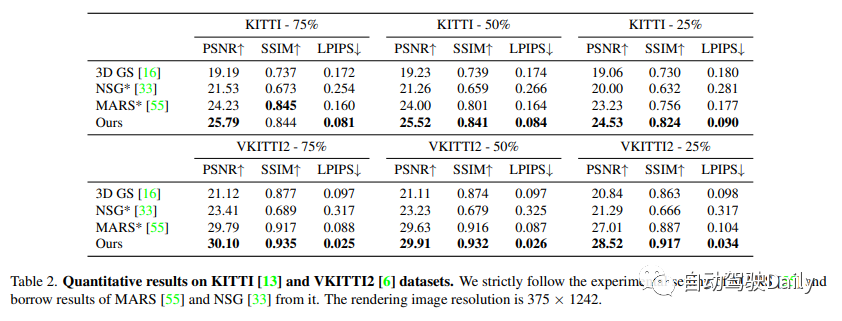
我們在Waymo開放數據集和KITTI基準上進行了實驗。在Waymo開放數據集上,選擇了6個記錄序列,其中包含大量移動物體、顯著的ego運動和復雜的照明條件。所有序列的長度約為100幀,選擇序列中的每10張圖像作為測試幀,并使用剩余的圖像進行訓練。當發現我們的基線方法在使用高分辨率圖像進行訓練時存在較高的內存成本時,將輸入圖像縮小到1066×1600。在KITTI和Vitural KITTI 2上,遵循MARS的設置,并使用不同的訓練/測試分割設置來評估。在Waymo數據集上使用檢測器和跟蹤器生成的邊界框,并使用KITTI官方提供的目標軌跡。

將本文的方法與最近的三種方法進行比較。
(1) NSG將背景表示為多平面圖像,并使用每個目標學習的潛在代碼和共享解碼器來對運動目標進行建模。
(2) MARS基于Nerfstudio構建場景圖。
(3) 3D高斯使用一組各向異性高斯對場景進行建模。
NSG和MARS都是使用GT框進行訓練和評估的,這里嘗試了它們實現的不同版本,并報告了每個序列的最佳結果。我們還將3D高斯圖中的SfM點云替換為與我們的方法相同的輸入,以進行公平比較。詳見補充資料。



原文鏈接:https://mp.weixin.qq.com/s/oikZWcR47otm7xfU90JH4g




















