













無懼圖像中的文字,TextDiffuser提供更高質量文本渲染
近幾年來,Text-to-Image 領域取得了巨大的進展,特別是在 AIGC(Artificial Intelligence Generated Content)的時代。隨著 DALL-E 模型的興起,學術界涌現出越來越多的 Text-to-Image 模型,例如 Imagen,Stable Diffusion,ControlNet 等模型。然而,盡管 Text-to-Image 領域發展迅速,現有模型在穩定地生成包含文本的圖像方面仍面臨一些挑戰。
嘗試過現有 sota 文生圖模型可以發現,模型生成的文字部分基本上是不可讀的,類似于亂碼,這非常影響圖像的整體美觀度。

現有 sota 文生圖模型生成的文本信息可讀性較差
經過調研,學術界在這方面的研究較少。事實上,包含文本的圖像在日常生活中十分常見,例如海報、書籍封面和路牌等。如果 AI 能夠有效地生成這類圖像,將有助于輔助設計師的工作,激發設計靈感,減輕設計負擔。除此之外,用戶可能只希望修改文生圖模型結果的文字部分,保留其他非文本區域的結果。
因此,研究者希望設計一個全面的模型,既能直接由用戶提供的 prompt 生成圖像,也能接收用戶給定的圖像修改其中的文本。目前該研究工作已被NeurIPS 2023接收。

- 論文地址:https://arxiv.org/abs/2305.10855
- 項目地址:https://jingyechen.github.io/textdiffuser/
- 代碼地址:https://github.com/microsoft/unilm/tree/master/textdiffuser
- Demo地址:https://huggingface.co/spaces/microsoft/TextDiffuser
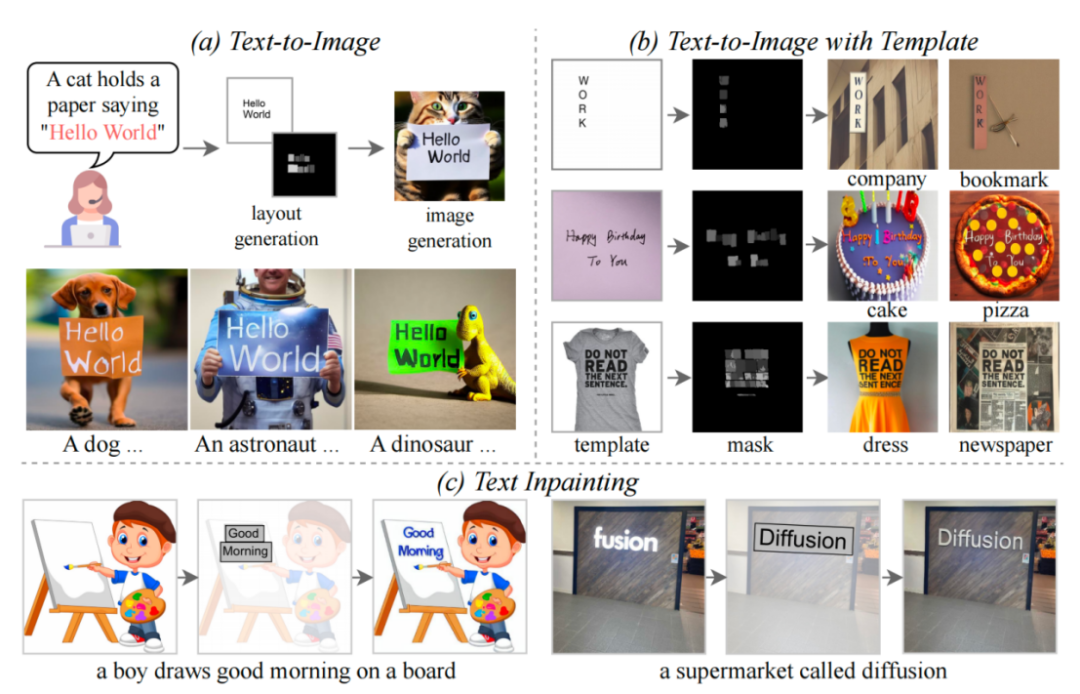
TextDiffuser 的三個功能
本文提出了 TextDiffuser 模型,該模型包含兩個階段,第一階段生成 Layout,第二階段生成圖像。

TextDiffuser框架圖
模型接受一段文本 Prompt,然后根據 Prompt 中的關鍵詞確定每個關鍵詞的 Layout(也就是坐標框)。研究者采用了 Layout Transformer,使用編碼器-解碼器的形式自回歸地輸出關鍵詞的坐標框,并用 Python 的 PILLOW 庫渲染出文本。在這個過程中,還可以利用 Pillow 現成的 API 得到每個字符的坐標框,相當于得到了字符級別的 Box-level segmentation mask。基于此信息,研究者嘗試微調 Stable Diffusion。
他們考慮了兩種情況,一種是用戶想直接生成整張圖片(稱為 Whole-Image Generation)。另一種情況是 Part-Image Generation,在論文中也稱之為 Text-inpainting,指的是用戶給定一張圖像,需要修改圖里的某些文本區域。
為了實現以上兩種目的,研究者重新設計了輸入的特征,維度由原先的 4 維變成了 17 維。其中包含 4 維加噪圖像的特征,8 維字符信息,1 維圖像掩碼,還有 4 維未被 mask 圖像的特征。如果是 Whole-image generation,研究者將 mask 的區域設為全圖,反之,如果是 part-image generation,就只 mask 掉圖像的一部分即可。擴散模型的訓練過程類似于 LDM,有興趣的伙伴可以參考原文方法部分的描述。
在 Inference 階段,TextDiffuser 非常靈活,有三種使用方式:
- 根據用戶給定的指令生成圖像。并且,如果用戶不大滿意第一步 Layout Generation 生成的布局,用戶可以更改坐標也可以更改文本的內容,這增加了模型的可控性。
- 直接從第二個階段開始。根據模板圖像生成最終結果,其中模板圖像可以是印刷文本圖像,手寫文本圖像,場景文本圖像。研究者專門訓練了一個字符集分割網絡用于從模板圖像中提取 Layout。
- 同樣也是從第二個階段開始,用戶給定圖像并指定需要修改的區域與文本內容。并且,這個操作可以多次進行,直到用戶對生成的結果感到滿意為止。

構造的 MARIO 數據
為了訓練 TextDiffuser,研究者搜集了 1000 萬張文本圖像,如上圖所示,包含三個子集:MARIO-LAION, MARIO-TMDB 與 MARIO-OpenLibrary。
研究者在篩選數據時考慮了若干方面:例如在圖像經過 OCR 后,只保留文本數量為 [1,8] 的圖像。他們篩掉了文本數量超過 8 的文本,因為這些文本往往包含大量密集文本,OCR 的結果一般不太準確,例如報紙或者復雜的設計圖紙。除此之外,他們設置文本的區域大于 10%,設置這個規則是為了讓文本區域在圖像的比重不要太小。
在 MARIO-10M 數據集訓練之后,研究者將 TextDiffuser 與現有其他方法做了定量與定性的對比。例如下圖所示,在 Whole-Image Generation 任務中,本文的方法生成的圖像具有更加清晰可讀的文本,并且文本區域與背景區域融合程度較高。
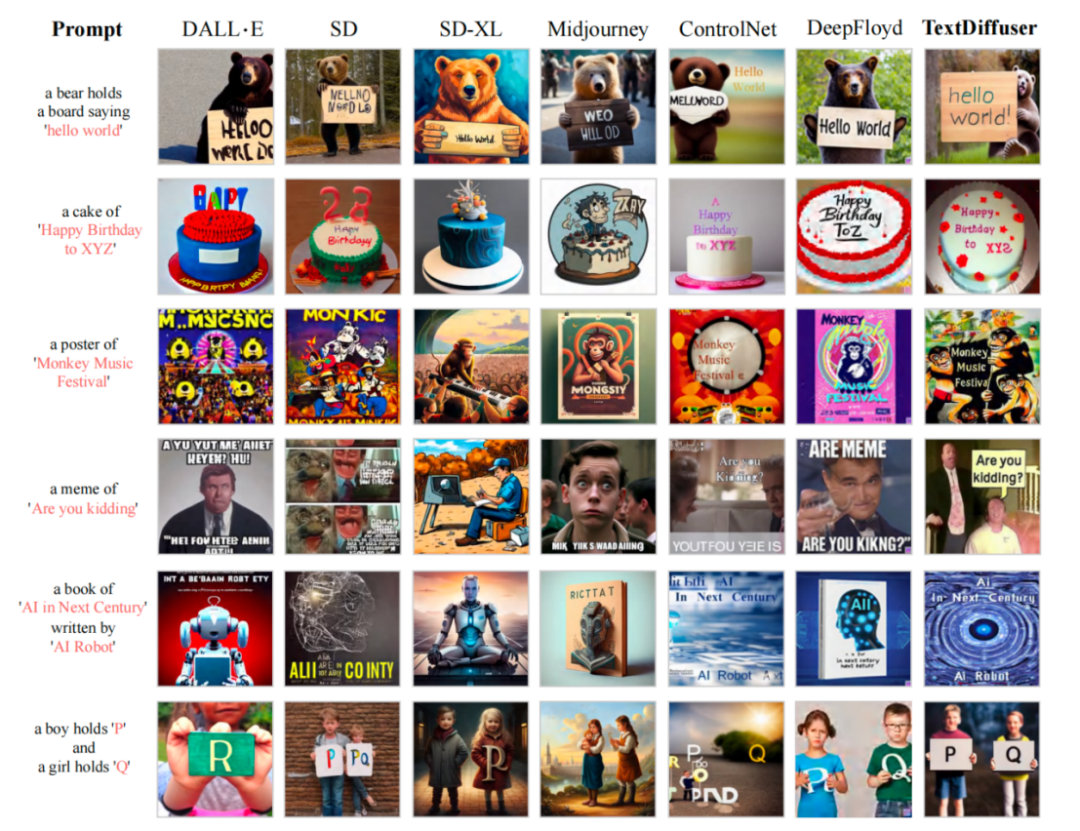
與現有工作比較文本渲染性能
研究者還做了定性的實驗,如表 1 所示,評估指標有 FID,CLIPScore 與 OCR。尤其是 OCR 指標,本文方法相對于對比方法有很大的提升。

表1:定性實驗
對于 Part-Image Generation 任務,研究者嘗試著在給定的圖像上增加或修改字符,實驗結果表明 TextDiffuser 生成的結果很自然。

文本修復功能可視化
總的來說,本文提出的 TextDiffuser 模型在文本渲染領域取得了顯著的進展,能夠生成包含易讀文本的高質量圖像。未來,研究者將進一步提升 TextDiffuser 的效果。

















