













何為交互感知?全面回顧自動駕駛中的社會交互動態模型與決策前沿!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
交互感知自動駕駛(IAAD)是一個迅速發展的研究領域,專注于開發能夠與人類道路使用者安全、高效交互的自動駕駛車輛。這是一項具有挑戰性的任務,因為它要求自動駕駛車輛能夠理解和預測人類道路使用者的行為。在這份文獻綜述中,作者對IAAD研究的當前狀態進行了調研。從對術語的調研開始,關注點集中在仿真駕駛員和行人行為的挑戰和現有模型上。接下來,對用于交互建模的各種技術進行了全面的回顧,涵蓋了認知方法、機器學習方法和博弈論方法。通過討論與IAAD相關的潛在優勢和風險,以及對未來研究探索至關重要的關鍵問題,最終得出結論。
交互感知介紹
近年來,隨著機器人技術和機器學習的最新進展,對自動駕駛汽車技術的開發越來越引起人們的興趣。這使得自動駕駛工程師能夠開發能夠解決自動駕駛任務復雜性的算法。自動駕駛汽車有潛力提高交通質量,減少交通事故,提高出行時間的質量。如今,越來越多的自動駕駛汽車被部署到現實世界中,與其他人類道路使用者共享環境。這引發了一些擔憂,即自動駕駛汽車可能無法理解并與其他人類道路使用者順利交互,可能導致交通困境和安全問題。為了以高效且安全的方式運行,自動駕駛汽車需要以類似于人類的方式行為,并生成考慮與其他人類道路使用者的交互的最優行為。這對于減少潛在的交通沖突至關重要。例如,在十字路口謹慎但不必要的停車可能導致追尾事故。為了開發全自動駕駛汽車,需要在自動駕駛汽車技術的許多方面取得進展,包括感知、決策、規劃和控制。在預測周圍人類道路使用者的行為并相應地為自動駕駛汽車做出決策方面,與周圍人類道路使用者的交互變得越來越重要,因為自動駕駛汽車的行為會影響他們的行為,反之亦然。
本文的目的是在自動駕駛背景下,對交互感知運動規劃和決策的最新技術進行詳盡調研。具體而言,文本首先涵蓋人類道路使用者行為模型,以突顯影響人類道路使用者在道路上做出決策的因素。駕駛員和行人行為模型對自動駕駛汽車來說有多重要是有原因的。首先,它們可用于評估和預測圍繞自動駕駛汽車的道路使用者的行為。其次,它們可以幫助開發類似于人類的自動駕駛汽車行為。因此,它們既具有預測價值,又為模型/系統設計添加了相關的見解。
本綜述分為5個主要部分,涵蓋了交互感知自動駕駛中的不同領域。第2節介紹了交互感知自動駕駛中使用的術語。請參考下圖1,了解論文結構的概覽。第3節將涵蓋影響人類駕駛決策的人因研究,以及行人行為研究。第4節廣泛概述和分類了用于交互建模的現有技術。最后,第5和第6節涵蓋了在交互場景中用于運動規劃和決策制定的最新技術。
雖然自動駕駛近年來一直是一個活躍的研究領域,但大部分研究集中在僅涉及車輛的情景中。相對較少的工作涉及異構場景,其中既包括車輛又包括行人。在本文中,焦點是異構場景,但第5和第6節還將涵蓋處理沒有行人的場景的相關工作。這是因為這些論文中使用的技術可以輕松地適應混合交通場景,或者它們可以為處理混合交通場景的一般問題提供重要的見解。

交互感知自動駕駛術語
在討論交互感知運動規劃和決策制定的最新進展之前,本文首先定義了該領域中使用的一些術語。在自動駕駛領域,術語"ego-vehicle"指的是要進行控制和研究的特定車輛。所有其他占據環繞自車區域的車輛、騎行者、行人等,都被視為交互障礙物,并被稱為周圍交通參與者,參見下圖2a。由于道路交通不太可能在不久的將來變得完全自動化,自動駕駛汽車將不可避免地在與人類道路使用者(HRUs)混合的環境中運行,例如人類駕駛員和行人。因此,交互感知自動駕駛是一項研究領域,重點是開發能夠安全有效地與周圍HRUs交互的自動駕駛汽車。傳統的自動駕駛方法通常將周圍HRUs視為動態障礙物。然而,這并不是一種現實的方法,因為它們會不斷地改變它們的行為以適應當前情況。
通常,多個周圍HRUs可能在它們自己之間或與自車之間產生共享空間的沖突:這種情況可以合理地推斷兩個或兩個以上的道路使用者打算在不久的將來的相同空間區域內占據相同的位置,見圖2b。參與沖突的道路使用者被認為表現出交互行為,這意味著如果沒有空間共享沖突,他們的行為將會不同。此外,交互不一定涉及沖突。它可以是明確或隱含的溝通,表明道路使用者的意圖并影響HRUs。例如,駕駛員可以根據前方車輛的轉向燈信號制定駕駛策略,使自車和前方車輛不在同一車道,且在不久的將來不會發生沖突。因此,交互行為是指道路使用者的不同行為方式,以適應他人的行為或請求對反應進行請求并采取行動以實現他們期望的目標。由于交互在駕駛時隨時發生,因此開發的自動駕駛汽車算法必須了解道路使用者之間的交互動態。這樣的算法被稱為交互感知,通常是近期自動駕駛研究的焦點。目前,安全且社會接受的交互感知自動駕駛系統受到一些挑戰的制約。其中一個挑戰是缺乏關于HRUs如何交互的創新理論。這是一項困難的任務,因為要開發的理論不僅限于預測和建模HRUs的行為,還包括探索行為模式及其基礎機制。將自動駕駛汽車無縫整合到交通中,就如同人類一樣,需要更先進的行為理論和模型。另一個挑戰是需要開發能夠與其他HRUs安全有效地交互并產生符合人類標準的自動駕駛汽車行為的算法。下圖3顯示了構成自動駕駛汽車系統的主要部分。傳感器的原始數據由感知模塊處理,該模塊檢測周圍環境并執行定位,允許為自車生成達到目標目的地的全局路線規劃。場景還可以進行進一步的解釋,并可以對周圍交通參與者的預測進行操作。交互感知模型在預測任務中起著重要作用,因為道路使用者會影響彼此的軌跡和決策。
決策和路徑規劃是自動駕駛中最重要的兩項任務之一。它們負責確定車輛如何在環境中移動。決策是從一組可能的選項中選擇行動的過程。例如,車輛可能需要決定是否變道、減速或停車。路徑規劃是生成車輛可跟隨的安全和可行軌跡的過程。決策和路徑規劃密切相關。決策過程通常輸出高層次的計劃,例如“向左變道”。然后,路徑規劃過程接受此計劃并生成車輛可以跟隨的詳細軌跡。這兩項任務都必須考慮車輛的當前位置、車輛的能力和周圍的交通情況,這就是為什么交互感知模型對這兩項任務非常相關的原因。從控制系統的角度來看,車輛的動態由其狀態表示,即位置和方向,以及它們的時間導數。環境的狀態由所有動態和靜態實體的狀態決定。物理狀態空間還可以通過捕捉附加的潛在空間變量而得到擴充,這些變量捕捉周圍用戶的意圖或行為偏好,這是場景理解系統的一部分。


人類行為研究與交互
本節綜合了關于HRUs(人類道路用戶)行為的實證和建模研究結果,包括與自動駕駛汽車或傳統車輛交互的人類駕駛員和行人,尤其是從溝通角度來看。焦點是研究涉及道路交互的內容,旨在發現可能促進交互感知自動駕駛汽車開發的見解。此處超出本文范圍的研究還包括宏觀交通條件的影響,如路徑選擇、天氣或法規等。
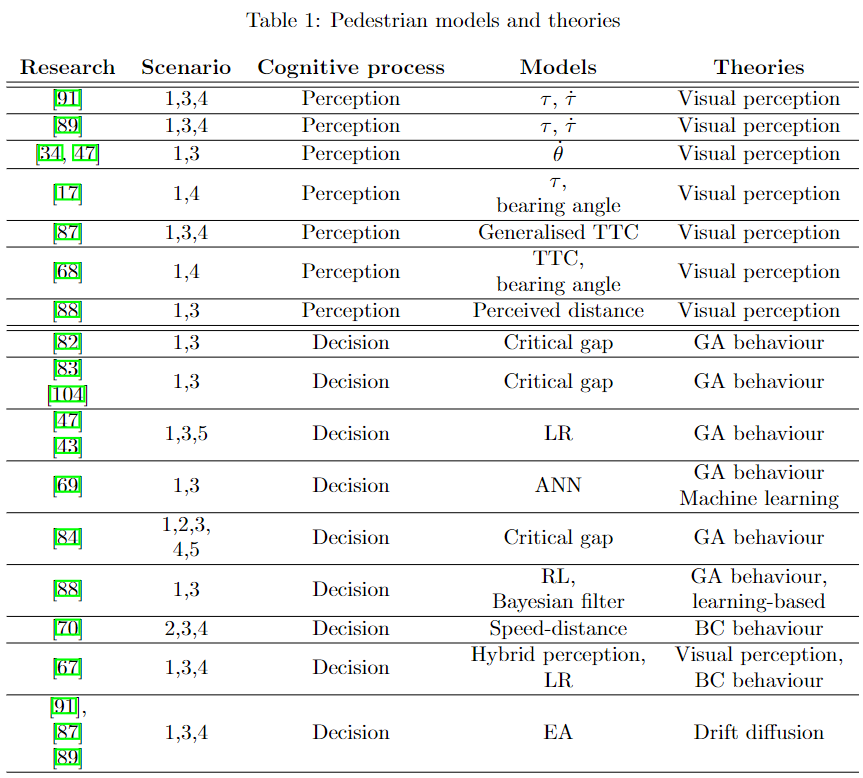
駕駛員行為研究
駕駛員行為模型用于預測和了解駕駛員在不同駕駛場景中的行為方式。這些模型可用于改善交通系統的安全性和效率,并有助于自動駕駛汽車的設計過程。許多因素可能影響駕駛行為,包括個體特征(年齡、性別、個性、經驗)、環境因素,即道路和天氣條件,以及社會因素,包括駕駛員與HRUs的交互。這里將重點放在與車輛-行人交互相關的DBM上。
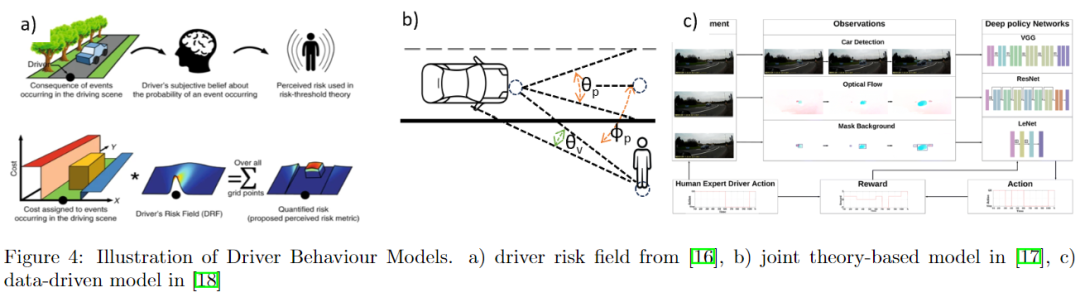
最常見的駕駛員行為模型包括:
- 駕駛員風險場模型:(下圖4a)該模型預測駕駛員在不同駕駛情況下如何感知風險。DRF模型的基礎理念是駕駛員基于對風險的感知做出決策。[16] 的研究結果表明,駕駛行為受到成本函數的控制,該函數考慮到噪聲對人類感知和行為的影響。自動駕駛汽車上的風險感知也在 [19]中進行了分析,該研究采用了駕駛仿真場景。
- 基于理論的:(下圖4b)感知和認知模型。基于感知信息的模型根據感知線索(如距離、車速、加速度、擴展角、反應時間等)描述駕駛員行為。認知模型概述了駕駛員作為心理人類的內部狀態流和調節其行為的動機。
- 數據驅動模型:(下圖4c)這組方法依賴于使用機器學習分析自然駕駛數據來分析駕駛員行為。數據驅動模型可以學習人類行為的生成或判別模型,以對駕駛員未來的決策或首選駕駛風格進行預測。模型驗證可以通過將預測與實際數據進行比較以及通過人在環仿真來完成。
現有研究通過自然駕駛數據分析突顯了駕駛員在行人存在的情況下的行為。[24]的作者發現在超越沿車道行走的行人、超越相反方向行走的行人或當對向交通存在時,駕駛員傾向于保持較小的最小橫向間隙和較低的超車速度。最小橫向間隙和時間-碰撞的關系與超車速度僅有弱相關。[25]中的結果顯示,車輛減速行為與初始時間到碰撞(TTC)、對行人過馬路意圖的主觀判斷、車速、行人位置和過馬路方向相關。
較少關注多道路使用者設置,其中多輛車和行人相互作用。在[26]中,作者基于在路口收集的數據開發了一個多道路使用者對抗逆強化學習(IRL)框架,以仿真路口的駕駛員和行人行為。總體而言,DBM是一個有前途的研究領域,有望顯著改進交通系統的安全性和效率。然而,仍然需要在開發和驗證這些模型方面進行大量工作。未來的研究應著重于開發更全面的模型,考慮到更廣泛的因素,如駕駛員的內部狀態、環境和與其他HRU的交互。
行人行為研究
由于行人被認為是最脆弱的道路使用者,缺乏保護裝備且移動速度較慢,因此調研行人行為與自動駕駛汽車與行人交互對安全性和可接受性具有明顯的相關性。幾十年來,行人行為一直是廣泛研究的對象。自動駕駛汽車的出現最近引發了許多關于行人行為的新研究問題。鑒于這個領域的大量工作以及作者的目標,本節調研了主要的研究而不是提供詳盡的調研。綜述涵蓋了與車輛交互的行人行為研究,從三個角度進行:溝通、橫穿行為的理論和模型,以及涉及自動駕駛汽車的應用。旨在確定和總結它們對開發具有交互感知能力的自動駕駛汽車的價值。
通信
在動態交通環境中,道路用戶通過其運動和空間暗示向彼此故意或無意地傳遞信號信息,產生了明確和隱含的交流。研究結果一致認為,由于缺乏駕駛員角色,自動駕駛汽車的運動學和信號信息對行人道路行為產生了顯著影響。因此,識別影響行人道路行為的關鍵動作提示和信號的研究具有重要意義(見下圖5a)。

隱含的溝通信號,如車輛的運動線索,涉及到影響其自身運動的道路用戶行為,但可以被解釋為另一道路用戶的意圖或運動的線索。接近的車輛與行人之間的距離或TTC是影響行人行為的最關鍵的隱含信息。證據表明,行人更傾向于更多地依賴距離而不是TTC。也就是說,對于相同的TTC,當車輛以較高的速度接近時,更多情況下,行人會過馬路。最近的研究表明,行人利用了來自車輛運動的多個信息源,而不是依賴于一個。速度、距離和TTC對行人行為的影響是相互耦合的。
剎車動作,是影響行人行為的另一個關鍵的隱含信息。車輛的運動與行人對車輛的信任、情感和對行人決策的影響相關。當接近的車輛早早減速并輕剎車時,行人感到舒適,開始迅速過馬路。急剎車導致行人回避行為。另一方面,早期的剎車動作和強烈的俯仰減少了行人理解車輛意圖所需的時間。以較慢的速度接近行人且禮讓的車輛可能阻礙理解。
交通特征 ,如交通量和間隙大小,為行人提供了隱含信息。高交通量迫使行人接受較小的交通間隙,因為時間成本的增加,增加了他們冒險的傾向。然而,大量證據表明,傾向等待的行人更為謹慎,不太可能接受冒險的間隙。交通量和行人過馬路行為之間的關系依賴于上下文,可能受到交通中間隙的大小和順序的影響。
此外,行人朝著道路的移動、站在路邊和行人頭部方向可能向接近的車輛傳遞關鍵的隱含信息。行人通常通過踏上道路或看向接近的車輛來主張他們的通行權。
明確的溝通信號 涉及道路用戶的行為,向其他道路用戶傳遞信號信息,而不影響自己的運動或感知。一個常見情況是車輛通過外部人機界面(eHMI)向行人傳遞信息。在自動駕駛汽車的背景下,沒有人類駕駛員,eHMI變得很重要。大量證據支持了eHMI在行人與自動駕駛汽車的交互中的益處。已經提出了各種類型的eHMI原型,如車頭燈、燈帶、擬人符號,但對于最佳eHMI形式和要傳達的信息的共識仍然難以確定。
許多研究表明,eHMI的性能取決于各種因素。行人對eHMI的熟悉程度、信任和解釋可能會顯著影響eHMI向行人傳達信息的有效性。例如,行人更好地理解傳統的eHMI(閃爍的大燈)作為車輛讓行的信號,而不是新穎的eHMI(燈帶)。如果eHMI失效,行人過度信任eHMI可能導致他們對車輛運動線索過于依賴,這是危險的。eHMI傳遞的以自我為中心的信息,如“OK TO CROSS”,比分配給他人的信息如“STOPPING”更具有說服力。此外,eHMI的可靠性受到天氣、光照條件和車輛行為的影響。例如,在惡劣天氣下,行人可能無法讀取車輛標志。當車輛不讓行或急劇減速時,行人愿意過馬路的意愿不受eHMI的影響。其他概念,如將eHMI安裝在道路基礎設施上而不是車輛上,以及將eHMI與車輛運動線索結合使用,可能勝過純粹的eHMI。
此外,從車輛的角度來看,雖然較少見,行人也使用明確的信號與自動駕駛汽車進行交流。這些信號包括眼神接觸和手勢,行人用這些信號確保自動駕駛汽車能看到他們并請求通行權。為了彌補沒有人類駕駛員的缺陷,自動駕駛汽車可以利用駕駛座位上的類人視覺化身和無線通信技術,以增強車輛與行人的溝通。
橫穿行為的理論和模型
行人橫穿行為涉及各種認知過程。先前的研究表明,在交互中構建行人橫穿行為涉及三個層次的過程,即感知、決策、開始和運動。基于這一假設,以下各節將綜合有關這三個認知過程的行人橫穿行為的理論和模型(見圖5b)。
視覺感知理論,由吉布森(Gibson)奠定,解釋了當物體接近觀察者時,其在視網膜上的圖像會擴展,形成人類碰撞感知的基礎。在橫越場景中,當車輛在視網膜上的圖像擴展速率達到一定閾值時,行人會感知到車輛正在靠近,這被稱為視覺逼近現象。一個心理物理模型將這種擴展速率簡化為逼近行人瞳孔處的車輛形成的視覺角度變化,表示為 ?θ(圖6a)。最近的研究表明,行人使用 ?θ 作為觀察逼近車輛的關鍵視覺線索。然而,雖然 ?θ 提供了空間信息,但它并不傳達車輛何時到達行人的位置。在橫越場景中,當車輛禮讓時,行人需要時間信息來估計車輛是否能及時停下。Lee的數學演示表明,表示為 θ 與 ?θ 比值的視覺線索 τ 可能指示接近車輛的TTC。此外,τ 的第一時間導數,表示為 ?τ,用于檢測當前減速率是否足以避免碰撞。此外,研究發現,在給定角度下,即方位角,行人可能會視覺感知即將發生的碰撞事件,方位角是車輛與行人注視線之間的角度(圖6b)。

除了視覺線索外,行人的感知可能取決于感知策略。田等人的研究表明,對車輛行為的行人估計可能是一個單獨的過程或橫穿決策的一個子過程。當有較大的交通間隙時,行人傾向于不依賴車輛駕駛行為,而更依賴間隙大小。同樣,Delucia 指出,當碰撞事件距離較遠時,人類傾向于使用'啟發式'視覺線索,如θ和 ?θ。然而,隨著碰撞變得迫在眉睫,光學不變量如τ支配感知,提供更豐富的時空信息。
除了感知機制,各種因素可能影響行人的感知。研究表明,由于與年齡相關的感知限制,老年人或兒童行人面臨較高的碰撞風險。老年行人更傾向于更多地依賴距離而不是TTC來判斷靠近的車輛,而兒童難以檢測以較高速度靠近的車輛。分心,特別是涉及視覺和手動部位(如使用智能手機)的分心,會分散大量的注意資源,并影響行人觀察交通狀況。相比之下,認知分心,比如聽音樂,可能不會顯著影響行人的感知。
決策 在沒有信號燈的無控制交叉口,行人通常會與讓行或不讓行的車輛進行交互。在不讓行的情況下,行人通常通過評估靠近車輛之間的間隔來做出橫穿決策,這被稱為間隙接受行為(GA)。這一概念導致了關鍵間隙模型的發展,包括Raff的模型、HCM2010的模型和Rasouli的模型。另外,二元logit模型將橫穿決策視為二元變量,利用人工神經網絡(ANN)、支持向量機(SVM)和邏輯回歸(LR)等機器學習算法。例如,Kadali等人使用ANN根據各種獨立變量(圖6c)預測橫穿決策,而Sun等人使用LR與諸如行人年齡、性別、組大小和車輛類型的變量。
在涉及讓行車輛的場景中,橫穿決策往往遵循一個稱為雙峰橫穿行為(BC)的雙峰模式。當交通間隙足夠大或車輛即將停車時,行人更傾向于橫穿。然而,在這種情況下做出決策可能是具有挑戰性的,因為決策線索與碰撞風險之間存在對立關系,碰撞風險與交通間隙呈負相關,與車輛速度呈正相關。Zhu等人根據車輛速度和距離將橫穿決策分為三組:橫穿、困境條件和等待(圖6d)。此外,田等人假設行人根據BC行為采用不同的決策策略,并將橫穿決策建模為對不同視覺線索的響應。
雖然上述方法是基于觀察到的行為模式來仿真橫穿決策,其他模型則深入研究了支撐這些決策的心理機制。具體而言,田等人基于行人的視覺線索仿真了行人的GA行為,并在具有更復雜的視覺感知機制的讓行場景中進行了擴展。王等人利用強化學習(RL)模型捕捉了基于有限感知機制的行人橫穿行為。此外,一類模型,即證據積累(EA)模型,如漂移擴散模型,提出橫穿決策是由視覺證據和噪聲的積累決定的,一旦達到一定閾值,決策就確定了。整合了大規模的心理理論,詳細解釋了行人橫穿決策(圖6e)。此外,博弈論也被應用于在行人與車輛協商通行權時仿真橫穿決策。傳統的博弈論、序列雞(SC)博弈和雙累積器(DA)博弈被用來表征動態橫穿決策。
環境的多樣性和行人的異質性進一步復雜化了橫穿決策建模。例如,橫穿多條車道通常涉及行人在車道線等待并逐個接受交通間隙,被稱為滾動間隙行為。在車道線等待的行人可能更有可能接受較小的交通間隙,而在路緣等待的行人可能不太可能接受。另一個復雜的場景是橫穿雙向道路,這在物理上和認知上都是具有挑戰性的。行人需要考慮兩邊的車輛。同樣,在交叉口處穿越擁擠的連續交通也是具有挑戰性的,因為行人需要預測交通上游的交叉間隙,并在安全性和時間效率之間做出權衡。通常認為,隨著等待時間的增加,行人傾向于接受更冒險的橫穿機會。然而,最新的證據表明,傾向等待的行人更為謹慎,不太可能接受冒險的間隙。關于行人的異質性,應用ANN和LR模型來表征年齡對橫穿決策的影響。分心,如手機使用,也可能影響行人的橫穿決策。應用ANN來仿真手機使用對橫穿決策的影響。此外,行人通常成群過馬路,展示出群體行為。該行為被描述為群體成員保持與群體中心一定距離的趨勢。使用EA模型來表征群體決策中信息級聯,考慮了先前道路使用者的決策的影響。
開始和運動 橫穿啟動時間(CIT)代表行人開始過馬路所需的時間,反映了他們決策的動態特性。一般來說,CIT是橫穿機會可用時和行人開始移動之間的持續時間。漂移擴散理論認為CIT受認知系統中噪聲證據的積累影響,反映了行人認知和運動系統的效率。各種因素可能影響CIT,包括車輛運動、年齡、性別和分心。面對更高的車速,行人傾向于更慢地開始橫穿。此外,女性行人傾向于比男性更快地開始橫穿,老年人傾向于比年輕行人更早開始。分心的影響取決于其組成部分。
在行人面對不讓行車輛的情況下,隨著車輛與行人之間距離的減小,碰撞的風險增加。因此,行人通常通過評估靠近車輛的“snapshots”來迅速做出決策。在這些情況下,CIT的分布通常是集中且右偏的。響應時間模型,如指數高斯模型和偏移瓦爾德(SW)分布,被用來仿真這些情況下的CIT。例如,將CIT建模為遵循SW分布的變量(下面圖7a)。
在車輛讓行場景中,如前節所述,CIT表現為雙峰分布。對于早期的CIT組,分布類似于不讓行場景中的分布,因為行人采用相似的決策策略。然而,對于晚期組,分布是復雜的,不能用標準的響應時間分布來描述。已經提出了具有時變證據的EA模型來解決這種復雜性,允許生成具有復雜形狀的CIT分布(下面圖7b)。此外,使用響應時間模型的聯合分布對車輛讓行場景中的CIT進行建模。此外,應用RL模型來學習行人的橫穿啟動模式。
在行人啟動橫穿后,他們需要穿過道路。步行是橫穿行為的關鍵部分,受到許多因素的影響,如靠近車輛的存在、基礎設施、行人年齡和分心。行人調整其行走軌跡以避讓車輛。在多車道橫穿中,他們傾向于移動到并等待在車道線上,依次接受每個車道的交通間隙。橫穿時,行人的行走速度通常比其他場景中的正常行走速度要快。雖然性別對行走速度沒有顯著影響,但青少年和老年人的步行速度較慢。分心,如使用手機,可能會降低行人的步行速度。
行為可以使用微觀行人運動模型來仿真,包括元胞自動機(CA)模型、社會力(SF)模型和基于學習的方法。CA模型在空間、時間和狀態上是離散的,使其成為仿真復雜動態系統(如行人-車輛相互作用)的理想選擇。基于牛頓第二定律的SF模型被用于仿真行人-車輛相互作用和大規模行人流(下面圖7c)。使用SF模型仿真了在涉及低速車輛的復雜交互場景中的行人群體的橫穿行為。
與上述白盒模型相對,還有基于學習方法的黑盒模型,它們從自然數據集或預定義環境中學習行人行走行為。例如,采用人工神經網絡(ANN)通過將視頻中提取的行人與其他物體之間的相對空間和運動關系納入考慮來學習行人的行走行為。將SF模型的輸出作為輸入輸入到ANN中,以仿真多種行人行走行為。提出了一種長短時記憶網絡(LSTM)行人軌跡預測模型(下面圖7d)。此外,RL和IRL模型也被用于仿真行人的行走行為。應用RL模型學習在SF環境中多個行人的行走行為。開發了一種IRL模型,從視頻數據集中學習行人的行走行為。

自動駕駛汽車涉及的應用
近年來,研究自動駕駛汽車與行人之間的交互關系的興趣逐漸增長。這種興趣導致了大量研究,將行人橫穿行為的理論和模型應用于增強或評估自動駕駛汽車在這些交互中的性能(下表2)。
一種普遍的方法是使用基于學習的方法,該方法從現實世界的數據集中學習行人的意圖和軌跡,以幫助自動駕駛汽車的決策制定。例如,提出了一種基于圖卷積神經網絡的行人軌跡預測模型,該模型考慮了過去的行人軌跡,以預測自動駕駛汽車使用案例的確定性和概率性未來軌跡。其他類似的模型旨在通過考慮交互的社會背景來提高預測準確性。例如,提出了一種LSTM行人軌跡預測模型,該模型考慮了過去的軌跡、行人頭部方向和與靠近車輛的距離作為輸入。此外,還有研究旨在預測行人橫穿意圖。分別應用SVM、LSTM和ANN來預測行人的橫穿意圖。
學習方法在預測行人軌跡和意圖方面已經證明是有效的。然而,這些模型需要大量的數據才能獲得強大的性能,在處理缺乏足夠數據的交互案例時受到限制。此外,這些模型的黑盒性質可能使得難以解釋生成的軌跡和意圖,這對自動駕駛汽車的決策建模構成了挑戰。為了解決這些問題,專家模型已經被開發出來。例如,SF模型已經被修改以通過納入更多的交互細節(如TTC和車輛與行人之間的交互角度)來預測自動駕駛汽車的行人軌跡。此外,SF和CA模型還嵌入到自動駕駛汽車決策模塊中,以表示行人橫穿行為并指導自動駕駛汽車在與行人的交互中的決策。
此外,橫穿決策模型也已應用于自動駕駛汽車研究。例如,采用了橫穿關鍵間隙模型來表征其自動駕駛汽車決策模塊中的行人橫穿決策。將其速度-距離模型應用于為自動駕駛汽車設計防御性和競爭性的交互行為。在其提出的自動駕駛汽車決策模塊中使用LR模型作為行人橫穿決策模型。為了增強橫穿決策的動態和交互性質,還使用博弈論模型來仿真在與自動駕駛汽車協商讓行權利時的橫穿決策。研究人員還嘗試使用行人感知理論或模型來設計自動駕駛汽車的決策策略。例如,使用控制理論基于視覺線索、τ和方位角仿真了自動駕駛汽車-行人耦合行為。用方位角對自動駕駛汽車和行人的讓行行為進行建模。
交互建模
交互建模技術對各種自動駕駛任務都至關重要,從交通預測到自動駕駛規劃和決策。在自動駕駛中理解和建模社交交互對于預測場景動態并確保安全的自動駕駛行為至關重要。準確的預測提高安全性,而誤解的自動駕駛行為可能導致事故。此外,理解自動駕駛行為的社會影響還可以影響周圍的交通,比如通過提前停車來鼓勵行人過馬路。由于交互建模技術可以應用于不同的任務領域,因此作者將重點放在無論它們被設計用于哪種具體駕駛任務,都將其劃分為不同的交互建模技術。
首先,可以在學習方法和基于模型的方法之間進行區分。在自動駕駛領域進行了廣泛的研究,利用了機器學習和深度學習技術。在學習方法中,從大量數據集中學習模型。這一系列方法不需要對系統有任何先驗知識。數據驅動方法是在示例數據集上訓練的,然后用于進行預測或決策。相反,基于模型的方法從對系統的理論理解開始。這種先驗知識用于創建系統的數學模型。然后使用經驗數據來驗證模型或調整其參數,以最小化模型預測與數據之間的差異。
基于另一個區分是方法是否明確利用人類思維的認知特征來解釋人類行為,或者只是隱含地仿真交互,試圖將環境輸入映射到決策/行為。第三節介紹的人類行為研究可以作為發展明確方法的指南。例如,博弈論方法采用更明確的方法,將交通參與者視為理性的道路使用者商,他們積極考慮彼此的行動。另一方面,作為非認知方法的示例,社交力方法提供了更經驗主義的觀點,捕捉參與者對彼此行為的影響,而不明確詳細說明解釋道路使用者商在交互期間的推理的過程。作者建議根據它們是否明確地或隱含地仿真交互來區分現有的建模方法。
根據這兩個標準,作者確定了四大交互建模類別,它們如下圖8所示。

基于學習的隱式方法
這些方法依賴于機器學習或深度學習技術。交互是隱式建模的,這意味著道路使用者的行為無法通過模型解釋。模型只從數據中學習輸入-輸出映射。模型學習可以通過利用交互式模型架構來實現。一般來說,使用專門用于交互的神經網絡架構的深度學習方法屬于這個類別。
在這種類型的方法中,目標是學習一個概率生成模型,該模型預測道路使用者的未來行為a。該模型是在環境狀態x的條件下的概率分布,其中包括周圍道路使用者的狀態,以及一組可學習的參數θ。

基于學習的帶認知特征的方法
這些方法依賴于明確手工制作的交互特征,這些特征被用作學習系統的輸入。這種類型的交互特征可以包括時間間隔(TTC),相對距離等,反映了人類推理背后的某些認知過程。例如,在中,開發了一種利用車輛間交互的LSTM,用于分類周圍車輛的變道意圖。交互特征由風險矩陣組成,該矩陣考慮了周圍車道中車輛的最壞情況TTC和相對距離。圖卷積網絡也屬于這一類別,因為交互特征可以在圖的鄰接矩陣中明確建模。
在這種類型的方法中,目標是學習一個概率生成模型,該模型類似于1中預測道路使用者的未來行為。在這種情況下,概率分布可以在環境狀態x和明確手工制作的交互特征I(x)的條件下。

基于模型的非認知方法
這些方法中的建模是非認知的,因為交互不會主動推理出道路使用者行為背后的認知過程。該組方法包括社交力和勢場。交互通過潛在函數(或SF)來描述,其中包含一組可學習的參數,這些參數可以根據經驗數據進行調整。另一組方法包括基于駕駛風險場的方法,這些方法基于這樣一個假設,即駕駛員行為是由基于風險的場域引起的。基于模型的隱式方法的優勢在于它們可以很容易解釋,并且可以嵌入領域知識,比如交通規則和場景背景。一些模型定義了一個潛在場,并將道路使用者的動作定義為與該場的梯度成正比。

否則,可以直接對力進行建模,從而不需要梯度運算a∝F*(*x)。
基于模型的認知方法
基于模型的認知方法描述了人類決策背后的推理過程。可以區分為兩類主要方法:效用最大化模型和認知模型。
在效用最大化方法中,人類被建模為優化器,選擇其行動以最大化其未來效用。

這些方法包括博弈論和馬爾可夫決策過程(MDP)。在博弈論方法中,道路使用者被建模為相互競爭或合作的玩家,從而考慮到他們如何對彼此的反應。博弈論框架為建模人類駕駛員之間的動態交互提供了透明且明確的解決方案,允許對決策過程進行清晰的解釋。然而,由于這種方法在道路使用者數量增加時計算復雜性不好處理,因此很難滿足計算可處理性的要求。另一個可能的解決方案是將人類行為建模為MDP的道路使用者,這為在結果受到機會和決策者決策影響的情況下建模決策提供了出色的框架。MDPs的解決方案可以通過學習方法找到,例如DRL算法或蒙特卡洛樹搜索,或者使用動態規劃技術。
第二組方法旨在使用心理認知過程捕獲道路使用者行為背后的行為動機。這組方法可以包括:
- 刺激-響應模型,其中駕駛員或行人的行為取決于視網膜上的視覺刺激;
- 證據積累,其中決策被描述為累積證據的結果;
- 心靈理論,它表明人類使用對他人思想和行為的理解來做出決策。通過預測他人的行動并推斷他們的知識,人類可以有效而安全地駕駛。

在接下來的部分,將更詳細地分析每個類別的交互建模。特別是,認知和非認知學習方法將在下一節中討論。基于模型的認知方法已在第前面章節中進行了詳細討論,其中包括社交力和勢場、駕駛風險場模型、心靈理論、刺激-響應模型和證據積累模型。后面章節將包括效用模型方法,其中包括MDP和博弈論。
基于學習的方法
機器學習(ML)方法廣泛應用于自動駕駛的各種任務,包括目標檢測、場景理解、路徑規劃和控制。通過從大量數據中學習,ML方法可以學會做出比人類更準確和高效的決策。本節將包括在前一節中確定的隱式和顯式基于學習的方法,并更詳細地介紹相關論文。下圖9展示了一些基于學習的方法的概述。

由于神經網絡學習表示方面的最新進展,現在可以使用端到端的駕駛方法,將原始傳感器數據作為輸入,輸出控制命令,如轉向和油門,以解決路徑規劃和控制問題。然而,從高維原始感知數據(例如LiDAR點云、相機圖像)中學習整個駕駛任務是具有挑戰性的,因為這涉及同時學習感知和決策制定。在大多數工作中,學習如何行動的過程假設場景表示對運動規劃和決策制定模塊可用。實際上,這需要將端到端駕駛分為兩個主要模塊,一個模塊中自動駕駛汽車學習如何看,另一個模塊中學習如何行動。
有兩種主要的端到端自動駕駛規劃和控制任務的方法(學習如何行動):
- 模仿學習:道路使用者學習模仿專家的行為。
- 深度強化學習(DRL):道路使用者試圖在仿真環境中進行的一種試錯過程中學習如何行動。DRL方法將在后面章節中更詳細地分析。
模仿學習是一種機器學習范例,道路使用者通過模仿專家演示者的行為來執行任務,這使其成為訓練自主系統和機器人的有價值的方法。在[151]中,通過圖注意力網絡(GAT)學習交互特征。該網絡的輸入包括周圍道路使用者的運動學信息以及編碼來自鳥瞰圖的場景表示的特征向量。該模型在CARLA仿真器中由專業駕駛員生成的合成數據上進行訓練。模仿學習方法在與訓練場景相似的情景中通常表現出色,但在場景偏離訓練分布時通常會失敗。像數據集聚合(DAgger)這樣的算法可以通過為看不見的情況增加人標注的數據來改善模仿學習策略的性能。然而,要求專家標注新的訓練樣本可能既昂貴又不可行。
在場景理解和運動預測的背景下,深度神經網絡已廣泛使用。[127]等人在其神經網絡架構中提出了一種社交池操作,以考慮人群運動預測中的周圍鄰居。類似地,使用具有最大池化操作的星形拓撲網絡來考慮多智能體預測中的交互特征。CIDNN 使用LSTM跟蹤人群中每個行人的移動,并根據他們與目標行人的接近程度為每個行人的運動特征分配權重,以進行位置預測。[129]的研究創建了一個數據集,并提出了一個名為VP-LSTM的框架,通過利用異質道路使用者的不同LSTM架構,預測擁擠混合場景中車輛和行人的軌跡。[130]中應用了生成對抗網絡(GAN)來為場景中的任何道路使用者生成合理的預測。這些方法的共同特點是使用循環神經網絡,結合池化操作,捕捉時空交互特征。在社交池操作期間,周圍道路使用者的隱藏狀態成為用于預測當前道路使用者運動的特征。擴散模型是另一組在建模時空軌跡方面越來越受歡迎的深度學習技術,可用于預測行人和車輛軌跡。
圖卷積網絡(GCNs)已廣泛用于具有相互作用道路使用者的軌跡預測任務。在這些方法中,道路結構被表示為一個圖,其中每個節點表示交通參與者。每個節點可以攜帶信息,如交通參與者的類別(汽車、卡車、行人等)、其位置或速度。顯式交互可以在圖的鄰接矩陣中建模,而隱式部分包括圖卷積層。GCNs廣泛用于交通預測,并且最近還在運動規劃中與DRL結合使用。
可以用于建模交互的其他機器學習技術包括高斯過程和概率圖模型,包括隱馬爾可夫模型。
基于效用的方法
基于效用的道路使用者使用效用函數來指導決策制定,為可能的世界狀態分配值并選擇導致最高效用的行動。與基于目標的道路使用者不同,后者根據目標滿足程度評估狀態,效用基的道路使用者可以處理多個目標并考慮概率和行動成本。效用基的方法包括馬爾可夫決策過程(MDP)和博弈論模型。
馬爾可夫決策過程
MDP是一種數學框架,用于建模決策問題,其中結果部分是隨機的,部分是由決策者控制的。MDP的建模框架如下圖10所示。有兩種主要方法可以解決MDP問題:動態規劃和強化學習。通常,后者更適用于自動駕駛,因為它們更適合高維狀態空間。

強化學習
強化學習(RL)利用馬爾可夫決策過程(MDP)來建模復雜的環境,并包括一組算法來學習最大化期望獎勵的策略。傳統上,動態規劃是實現這一目標的可靠方法,通過迭代計算每個狀態的值,從終端狀態開始,逆向工作到初始狀態。該方法在狀態空間較小的情況下表現出色。然而,在面對具有龐大狀態空間的RL挑戰時,例如自動駕駛的領域時,這可能會導致計算負擔。更常見的是,使用深度神經網絡(DRL)增強的RL。DRL算法在樣本效率和可擴展性方面可能優于動態規劃算法,但它們也可能更復雜,訓練難度較大。有關DRL應用于自動駕駛的更詳細調研,請參閱。
自動駕駛中的DRL解決方案將根據使用的場景、狀態空間表示、動作空間和使用的算法進行分類。DRL中常用的狀態表示見下圖11:
- 基于向量的表示:在這種表示類型中,有關周圍車輛的信息,如位置和速度,包含在長度固定的向量中;
- 鳥瞰圖(BEV):從頂部視角呈現自車周圍環境的2D圖像表示;
- 占用柵格表示:類似于BEV圖像,它是圍繞自車的環境的2D離散表示。它是一個2D或3D的單元格網格,每個單元格被分配被障礙物占用的概率,以及關于占用單元格的實體類型的分割信息。
- 圖表示:這是將自動駕駛汽車周圍環境的狀態表示為圖的一種方式。圖中的節點表示環境中的對象,如車輛、行人和紅綠燈。圖中的邊表示對象之間的關系,如距離或潛在碰撞的可能性。圖表示緊湊而高效,是表示環境狀態的有前途的方法。

基于向量的表示通過以緊湊而高效的方式表示對象,但以犧牲交通信息的方式,將其限制為周圍車輛的固定維度子集。BEV圖像和占用柵格提供了一種用固定方式表示環境的簡單方法,可以輕松更新。然而,在高混雜度或不確定性的環境中,它們可能不準確。圖表示可以以緊湊的方式輕松表示道路使用者之間的關系。另一方面,隨著周圍道路使用者數量的增加,更新圖可能會變得復雜和計算昂貴。
動作空間可以是連續的或離散的。連續動作通常包括自車的縱向加速度和轉向角。離散動作通常取決于正在解決的特定任務。例如,在變道場景中,離散動作包括左變道、保持當前道路或右變道。較低層控制器調節車輛的轉向和加速度以執行該動作。
盡管大多數DRL論文關注僅有車輛的交通場景,但處理混合交通場景或車輛-行人交互的論文數量較有限。一些研究涉及移動機器人的人群導航。在[174]中,使用DRL在多智能體環境中導航機器人。在[175]中,通過使用基于注意力的神經網絡和社交池提高了[174]中的模型。在[176]中,使用DQN道路使用者開發了一種自動制動系統。作者實現了一種創傷記憶,類似于優先經驗重播(PER),用于從碰撞場景中采樣。在[178]中,訓練了一個DQN道路使用者來避免與橫穿行人的碰撞,并進一步用于開發輔助駕駛員在行人避免碰撞情景中的ADAS系統。Deshpande等人使用了一個四層的網格狀態表示。在類似的情景中,[180]的作者開發了一個使用連續動作的SAC道路使用者。通過在獎勵函數中集成SVO組件,可以訓練車輛具有不同的社交符合行為,從親社會行為到更具打擊性的行為。
在實際場景中部署深度強化學習(DRL)面臨著重大挑戰,是一個開放的研究領域。一些研究,直接在實際應用中實施DRL策略,無需額外微調,展示了它們在無信號交叉口等場景中的有效性。遷移學習,深度學習的一個子領域,目前正在探索將知識從仿真環境轉移到現實世界。兩種主要技術包括域自適應和域隨機化。在域隨機化中,該方法旨在具有足夠大的訓練數據集,以涵蓋真實世界作為特定情況。通過域自適應,目標是從源分布中學習一個在目標分布上表現良好的模型。
與DRL相關的另一個問題是,基于學習的策略具有較高的訓練成本,并且很難實現語義解釋。最近,一些研究人員專注于可解釋的學習算法和終身學習算法來解決上述缺點。
多智能體強化學習
當多個RL道路使用者被部署到真實世界并相互交互時,問題變為多智能體強化學習(MARL)。為了處理多智能體系統,有多種方法可行。第一種方法是使用一個集中式控制器來管理整個車隊。通過增加狀態維度以包含所有車輛,并具有聯合動作向量,問題可以再次變成單智能體問題。缺點是狀態和動作空間的維度增加,這可能使學習變得更加復雜。最近,圖形表示法已被用于克服問題的維度詛咒。另一種方法,受到Level-k博弈論的啟發,是使用單個DRL學習器,但用其先前副本替換一些周圍道路使用者。這種技術類似于在競爭性DRL場景中使用的自我對弈。最后一種方法是采用MARL方法來制定問題,其中多個學習器并行工作。在[187]中提出了一種多智能體深度確定性策略梯度(MADDPG)方法,該方法為每個道路使用者學習一個單獨的集中式評論家,使每個道路使用者可以具有不同的獎勵函數。詳見,其中對MARL進行了廣泛的調研。在自動駕駛中,MARL的其他應用可以在中找到。
部分可觀察馬爾可夫決策過程
部分可觀察馬爾可夫決策過程(POMDPs)是MDPs的一般化。如果過程狀態s不能直接被決策者觀察到,則MDP被認為是部分可觀察的。POMDP在計算上很昂貴,但提供了一個通用的框架,可以對各種現實決策制定過程進行建模。由于硬件的改進,POMDP在自動駕駛的應用越來越受歡迎。在[190]中,POMDP已被用于在人群中導航移動機器人。機器人對行人的可能未來目標保持信念。POMDP還在存在行人時用于汽車決策制定。在POMDP中,將自車周圍的道路使用者建模為環境的一部分,并使用信念向量來建模它們的意圖。在[189]中,作者開發了一種多智能體相互作用感知的決策制定策略,該問題被建模為POMDP,并且使用基于注意力的神經網絡機制來建模交互。POMDP還被用于解決交叉口處環境遮擋下的決策制定問題。有關POMDP在交互決策中的其他應用,請參見[193] [194]。傳統的控制方法通常按順序處理傳感器不確定性和規劃,在其中狀態估計器處理傳感器噪聲和不確定性,然后使用確定性策略根據估計的狀態確定動作。另一方面,POMDP不做這樣的分離,策略是基于信念狀態確定的。周圍道路使用者可以被明確地建模為決策者(MARL),也可以被視為單個道路使用者在其中操作的環境(RL或DRL)。

博弈論模型
博弈論是研究理性道路使用者之間戰略交互的數學模型。博弈論主要應用于經濟學,但也在自動駕駛中出現。特別是,對于自動駕駛來說,動態的非合作博弈論非常重要。如果博弈涉及多個決策且決策順序重要,那么它是動態的;如果每個參與者都追求自己的興趣,與其他人的興趣部分沖突,那么它是非合作的。動態非合作博弈論包括離散時間和連續時間的博弈,并且它提供了對多智能體環境的最優控制的自然擴展。
博弈論研究在最優玩家假設下的平衡解,其中多個概念適用于軌跡博弈。動態博弈分為開環和反饋博弈,基于可用信息,開環假設每個玩家只能獲得博弈的初始狀態的信息。對于反饋博弈,每個道路使用者可獲得博弈的當前狀態的信息。盡管第二種類型的博弈更準確地描述了自動駕駛設置,但通常出于其簡單性而更喜歡使用開環解決方案。自動駕駛中的常見平衡包括開環納什、開環斯塔克爾伯格、閉環納什和閉環斯塔克爾伯格平衡。有關該主題的更多詳細信息,請參見[197]。
當道路使用者的動態必須符合一組約束,例如避免碰撞的約束時,平衡被稱為廣義平衡。[220]中研究了廣義平衡問題的數值解。開環納什均衡配方的缺點是玩家無法直接推斷他們的行為如何影響周圍道路使用者的行為。這方面的第一個簡化是開環斯塔克爾伯格均衡,例如在[203]中應用于無人機自主比賽的背景下。在斯塔克爾伯格競賽中,領導者首先行動,然后依次跟隨后續玩家,允許那些具有較高優先級的人考慮那些具有較低優先級的人將如何計劃他們的行動。在[207]中,作者提出了一種基于開環斯塔克爾伯格博弈的自主賽車的順序雙矩陣博弈方法。也可以找到斯塔克爾伯格配方的其他應用。可以在[223]中找到解決廣義反饋納什均衡問題的配方。Sadigh等人將自動駕駛汽車-人交互建模為Stackelberg競賽中的部分可觀察隨機游戲。人類估計自動駕駛汽車的計劃并相應行動,而自動駕駛汽車優化其自己的行動,假設對人類的行動具有間接控制權。
通常,博弈論方法面臨以下問題:(1)計算復雜性隨著道路使用者數量的增加和時間視角的增加而呈指數增長,(2)它們假設解釋其他道路使用者行為的效用函數對自車輛是已知的,并且道路使用者根據這些獎勵函數理性行事-然而在博弈論金融問題中已知,人類往往不是理性行事;(3)道路使用者的行為可能是隨機的,并且解決混合或行為策略的計算變得更加棘手。自然地,博弈論還具有捕捉行為相互依賴性和一些問題的確切解決方案的巨大優勢。博弈論自動駕駛領域的許多論文嘗試通過進一步簡化問題或找到近似解決方案來緩解這些問題。現在,將看一下該領域的一些論文,分析它們的簡化假設。

Level-k理論打破了納什均衡理性期望邏輯,假設人們認為其他人比自己不那么復雜。這就是Level-k推理,其中迭代過程在k步之后停止。其他道路使用者被建模為Level-k-1的參與者。Level-k道路使用者假設所有其他道路使用者都是Level-(k-1),并基于這一假設進行預測,并相應地做出反應。在[219]中,Level-k推理被應用于環狀交叉口場景。這種方法還在[206]中被納入了一個RL框架中:作者將問題限制為兩個交互道路使用者,并使用基于DQN的RL方法解決了具有兩輛車的馬爾可夫博弈。在[218]中,Level-k推理被采用來解決交叉口的沖突。作者們表明,在自車輛是Level-k道路使用者且所有周圍車輛都是Level-k-1或更低級別的情況下,沖突可以很容易地解決。然而,當兩個道路使用者都是相同級別時,碰撞的數量增加,這表明需要進一步改進以處理具有相同類型道路使用者的場景,這在多個自動駕駛汽車的情況下是至關重要的。
為了保持計算復雜性可控,可以通過確定與自車輛進行交互的所有道路使用者的子集來減少道路使用者的數量。時間視角也可以通過考慮遠程視角控制器或暗示分層博弈規劃而進行限制。后者包括具有短視角戰術規劃者和具有長視角戰略規劃者的組合。第一個負責準確仿真問題的動力學,第二個負責使用近似動力學決定戰略。
迭代線性二次(LQ)方法在機器人學和控制領域日益普遍。[201]的作者將問題表述為具有非線性系統動力學的一般和差分博弈。在[202]中,他們將他們的方法擴展到具有反饋線性化動力學的系統。解決博弈理論問題的另一種方法是使用迭代最佳響應來計算純納什均衡,即純策略中的納什均衡。[216]的作者提出了一種“敏感性增強”的迭代最佳響應求解器。在[204]中,提出了一種基于IBR的在線博弈論軌跡規劃器。該規劃器適用于在線規劃,并在競爭性賽車場景中展示出復雜的行為。Williams等人提出了一個IBR算法,以及一個信息論規劃器,用于控制兩個地面車輛在緊密接觸中。
在[13]中,Schwarting等人提出了解決納什均衡問題的迭代最佳響應的替代方法,該方法基于將優化問題重新制定為使用Karush–Kuhn–Tucker條件的本地單層優化。在[137]中,博弈論被用來建模其他車輛的決策制定。他們提出了一個并行游戲交互模型(PGIM),用于提供積極和社會合規的駕駛交互。為了解決環境不確定性,將博弈論的納什均衡概念擴展到POMDPs。在[215]中,作者通過構建關于其他道路使用者目標和約束的多個假設,對其他道路使用者的意圖存在不確定性進行了考慮。
討論與未來挑戰
在這次全面的調研中,介紹了對自動駕駛進展至關重要的兩個關鍵部分:人類行為研究和交互建模。這些部分構成了理解和優化自動駕駛場景中復雜交交互態的基礎。在本部分,將強調未來自動駕駛研究中交互場景的挑戰和研究方向。
人類行為研究
在社會對自動駕駛的強烈愿望驅動下,人類行為研究在近年來再次成為一個熱門話題,尤其是在自動駕駛汽車背景下的研究。為了更好地理解自動駕駛汽車交互過程中的行人行為,仍然需要克服許多挑戰。
總體而言,駕駛員行為模型的探索是一個具有潛力的研究領域,有望在交通系統的安全性和效率方面取得實質性的改進。然而,在這些模型的開發和驗證方面仍有大量工作需要進行。未來研究應優先考慮創建更全面的模型,涵蓋更廣泛的因素,包括駕駛員的心理狀態、周圍環境以及與道路上其他人的交互。
對于行人行為研究,一個重要的挑戰是溝通。首先,盡管大多數研究者都同意eHMI的有效性,但在其內容、形式和視角方面仍然缺乏共識。一個懸而未決的問題是,eHMI是否應該是擬人化的還是非擬人化的。對于文本和非文本的eHMI,也出現了類似的問題。此外,由于道路上存在多個行人,當前的eHMI主要設計為一對一的相遇,這可能會誤導其他行人。還存在許多類似的問題,阻礙了eHMI的標準化。另一方面,由于諸如車輛運動學之類的隱含信號被廣泛接受、普遍、常見且可靠,因此它們的關鍵作用不能被忽視。雖然研究人員已經嘗試通過操縱隱含信號(如車輛減速率、橫向距離和俯仰)來影響行人,但這些努力不足以確保安全有效的溝通。這些溝通方法缺乏相關理論支持,以證明溝通信息的準確有效傳遞。此外,在研究方法方面,包括車輛駕駛行為設計、主觀和客觀實驗設計等方面,可靠的研究范式的缺乏也是一個問題。另外,如何有效而流暢地將eHMI和隱含信號結合起來,以利用雙方的優勢,也是一個有趣的研究方向。
另一個挑戰是行人行為研究。行人的決策制定和行為模式受到交互情境、交通環境和參與者多樣性的影響。然而,這些方面目前缺乏足夠的研究關注。現有研究通常側重于特定和簡單的交互情境,以控制變量或簡化研究復雜性。然而,現實生活中涉及大量復雜情景,包括多車道、雙向或非結構化道路的過路口、面對密集連續交通流的過路口、多行人過馬路的情景等。此外,行人的異質性,如性別、年齡、分心和群體效應,也在交互中發揮著重要作用。值得注意的是,許多影響因素,如等待時間和分心,仍然缺乏共識。因此,由于缺乏充足且可靠的結果,研究結論主要依賴于假設,突顯了對行人道路行為基本機制理解的不足。
關于行人行為建模,近年來基于學習的方法變得越來越吸引人。端到端的深度神經網絡可以有效捕捉復雜的行為機制,在行人意圖預測和軌跡預測領域取得了顯著進展。然而,其黑盒性質不能忽視。這些方法需要大量的數據來實現穩健的性能,這限制了它們對數據不足的零星案例的可擴展性。此外,黑盒模型在解釋其決策和行為邏輯方面存在困難,這給建模帶來了新問題。相反,專家模型,如社會力模型、證據積累模型或博弈論模型,具有堅實的心理和行為基礎,其行為決策邏輯清晰且可解釋。然而,大多數這些模型只在有限的數據集上進行了驗證,或者仍處于實驗室驗證階段,缺乏大量的工程實踐。因此,未來需要進一步完善專家模型的理論,并在大量真實數據集上進行廣泛驗證。此外,專家模型和數據驅動模型在不同方面具有優勢。可能的未來趨勢是找到兩種模型共同使用的平衡點。
最后,考慮到關于自動駕駛的整體文獻中只有很小一部分明確考慮了行人行為,有必要增加行人行為模型的應用,可能包括但不限于行人行為預測、自動駕駛汽車行為設計和虛擬自動駕駛汽車驗證。
交互建模
隨著自動駕駛技術的不斷發展,對交互建模的研究將在解決挑戰和推動更安全、可靠的自動駕駛車輛發展中發揮關鍵作用。
自動駕駛研究中引起關注的一種突出方法是使用基于學習的方法。這些方法具有端到端解決方案的吸引力,直接將感知輸入和目的地知識映射到自動駕駛車輛的行為中。然而,這樣的系統可能表現為黑盒,導致在出現故障時解釋性問題以及對模型進行驗證的困難。此外,完成整個駕駛過程的任務龐大,即學習整個駕駛過程,這也帶來了重大挑戰。因此,當前的研究努力將這一任務分解為子任務,包括路線規劃、感知、運動規劃和控制,并利用基于學習的方法來解決這些部分挑戰。
通過模仿學習或在深度強化學習(DRL)方法中進行仿真來學習交互行為的優勢也在不斷增強。然而,挑戰依然存在。大多數基于深度學習的決策假設理想的道路場景和對周圍環境的完美感知。然而,現實世界的條件往往涉及遮擋、傳感器噪聲和環境異常。在這些偶發事件中保持系統性能并處理部分或嘈雜信息是一個持續存在的研究挑戰。不確定性來自周圍交通參與者的不可預測行為,以及傳感器噪聲和車輛模型。此外,在仿真環境中訓練的模型(如DRL模型)引發了一個問題,即如何彌合仿真和現實之間的差距。已經提出了幾種策略,包括使仿真更加現實、領域隨機化和領域自適應。這些方法旨在使模型能夠應對現實世界的不可預測性和復雜性,確保其在道路上有效應用所學到的知識。
學習為基礎的方法的另一種替代方法是基于模型的方法。這組方法包括博弈論模型、行為模型(在前一部分中已討論)、社會力和勢場。
博弈論提供了靈活性和適應性,可以有效處理各種情況,而無需依賴特定的數據分布。其關鍵優勢之一是能夠在給定情境中處理道路使用者的規劃和預測。然而,計算方面存在一種權衡。隨著道路使用者數量和時間范圍的增加,計算負擔也增加。研究人員提出了一些增強博弈論解決方案的策略,包括分層博弈論公式、將周圍道路使用者的優化問題限制為近似解決方案、級別k博弈論,或提高非線性優化求解器的性能。
另一方面,社會力或勢場方法提供了一種快速計算的解決方案。它們可以用于預測周圍道路使用者的行為,也可以用于自動駕駛車輛的控制。社會力模型依賴于對人類行為的簡化假設。它們通常將行人視為具有固定特征的粒子或道路使用者,忽視了人類決策制定的認知方面,這可能導致對復雜且動態的人類行為的不切實際的表示。這些方法的未來研究方向包括整合認知元素或上下文信息,如道路規則和交通信號。探索整合機器學習技術以提高社會力模型的適應性和預測能力也是可能的未來研究方向。
現有研究主要集中在車輛之間的交互中,這在自動駕駛中無疑起著關鍵作用。然而,有迫切需要開發能夠處理與人類道路用戶的交互,尤其是行人交互的方法。隨著自動駕駛領域的不斷發展,揭示治理與各種道路用戶之間的溝通和交互的理論和模型,將在技術上變得更加重要,有望推動自動駕駛場景中的安全性和效率。

原文鏈接:https://mp.weixin.qq.com/s/VDDLPUHU3HsQZ08iaFDGWw


























