













GPT-5前瞻!艾倫人工智能研究所發布最強多模態模型,預測GPT-5新能力
GPT-5何時到來,會有什么能力?
來自艾倫人工智能研究所(Allen Institute for AI)的新模型告訴你答案。
艾倫人工智能研究所推出的Unified-IO 2是第一個可以處理和生成文本、圖像、音頻、視頻和動作序列的模型。
這個新的高級人工智能模型使用幾十億個數據點進行訓練,雖然模型大小只有7B,卻展現出迄今為止最廣泛的多模態能力。

論文地址:https://arxiv.org/pdf/2312.17172.pdf
那么,Unified-IO 2和GPT-5有什么關系呢?
早在2022年6月,艾倫人工智能研究所就推出了第一代Unified-IO,它是首批能夠處理圖像和語言的多模態模型之一。
大約在同一時間,OpenAI正在內部測試GPT-4,并在2023年3月正式發布。
所以,Unified-IO可以看作是對于未來大規模AI模型的前瞻。
也就是說,OpenAI可能正在內部測試GPT-5,并將在幾個月后發布。
而本次Unified-IO 2向我們展現的能力,也將是我們在新的一年可以期待的內容:
GPT-5等新的AI模型可以處理更多模態,通過廣泛的學習以本地方式執行許多任務,并且對與物體和機器人的交互有基本的了解。

Unified-IO 2的訓練數據包括:10億個圖像-文本對、1 萬億個文本標記、1.8億個視頻剪輯、1.3億張帶文本的圖像、300萬個3D資產和100萬個機器人代理運動序列。
研究團隊將總共120多個數據集組合成一個600 TB的包,涵蓋220個視覺、語言、聽覺和動作任務。
Unified-IO 2采用編碼器-解碼器架構,并進行了一些更改,以穩定訓練并有效利用多模態信號。
模型可以回答問題、根據指令撰寫文本、以及分析文本內容。

模型還可以識別圖像內容,提供圖像描述,執行圖像處理任務,并根據文本描述創建新圖像。

它還可以根據描述或說明生成音樂或聲音,以及分析視頻并回答有關視頻的問題。
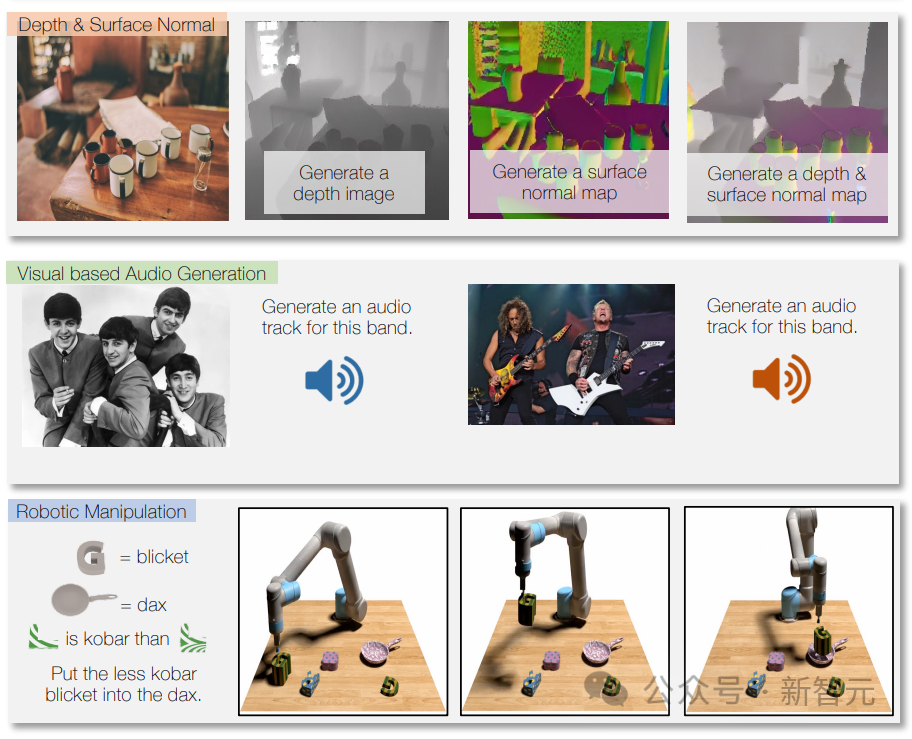
通過使用機器人數據進行訓練,Unified-IO 2還可以為機器人系統生成動作,例如將指令轉換為機器人的動作序列。
由于多模態訓練,它還可以處理不同的模態,例如,在圖像上標記某個音軌使用的樂器。

Unified-IO 2在超過35個基準測試中表現良好,包括圖像生成和理解、自然語言理解、視頻和音頻理解以及機器人操作。
在大多數任務中,它能夠比肩專用模型,甚至更勝一籌。
在圖像任務的GRIT基準測試中,Unified-IO 2獲得了目前的最高分(GRIT用于測試模型如何處理圖像噪聲和其他問題)。
研究人員現在計劃進一步擴展Unified-IO 2,提高數據質量,并將編碼器-解碼器模型,轉換為行業標準的解碼器模型架構。
Unified-IO 2
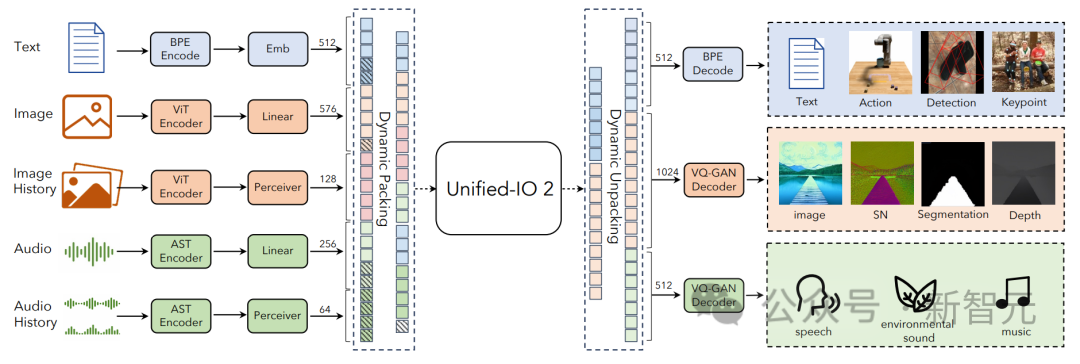
Unified-IO 2是第一個能夠理解和生成圖像、文本、音頻和動作的自回歸多模態模型。
為了統一不同的模態,研究人員將輸入和輸出(圖像、文本、音頻、動作、邊界框等)標記到一個共享的語義空間中,然后使用單個編碼器-解碼器轉換器模型對其進行處理。
由于訓練模型所采用的數據量龐大,而且來自各種不同的模態,研究人員采取了一系列技術來改進整個訓練過程。
為了有效地促進跨多種模態的自監督學習信號,研究人員開發了一種新型的去噪器目標的多模態混合,結合了跨模態的去噪和生成。
還開發了動態打包,可將訓練吞吐量提高4倍,以處理高度可變的序列。
為了克服訓練中的穩定性和可擴展性問題,研究人員在感知器重采樣器上做了架構更改,包括2D旋轉嵌入、QK歸一化和縮放余弦注意力機制。
對于指令調整,確保每個任務都有一個明確的提示,無論是使用現有任務還是制作新任務。另外還包括開放式任務,并為不太常見的模式創建合成任務,以增強任務和教學的多樣性。
統一任務表示
將多模態數據編碼到共享表示空間中的標記序列,包括以下幾個方面:
文本、稀疏結構和操作
文本輸入和輸出使用LLaMA中的字節對編碼進行標記化,邊界框、關鍵點和相機姿勢等稀疏結構被離散化,然后使用添加到詞匯表中的1000個特殊標記進行編碼。
點使用兩個標記(x,y)進行編碼,盒子用四個標記(左上角和右下角)的序列進行編碼,3D長方體用12個標記表示(編碼投影中心、虛擬深度、對數歸一化框尺寸、和連續同心旋轉)。
對于具身任務,離散的機器人動作被生成為文本命令(例如,「向前移動」)。特殊標記用于對機器人的狀態進行編碼(例如位置和旋轉)。
圖像和密集結構
圖像使用預先訓練的視覺轉換器(ViT)進行編碼。將ViT的第二層和倒數第二層的補丁特征連接起來,以捕獲低級和高級視覺信息。
生成圖像時,使用VQ-GAN將圖像轉換為離散標記,這里采用patch大小為8 × 8的密集預訓練VQ-GAN模型,將256 × 256的圖像編碼為1024個token,碼本大小為16512。
然后將每個像素的標簽(包括深度、表面法線和二進制分割掩碼)表示為RGB圖像。
音頻
U-IO 2將長達4.08秒的音頻編碼為頻譜圖,然后使用預先訓練的音頻頻譜圖轉換器(AST)對頻譜圖進行編碼,并通過連接AST的第二層和倒數第二層特征并應用線性層來構建輸入嵌入,就像圖像ViT一樣。
生成音頻時,使用ViT-VQGAN將音頻轉換為離散的標記,模型的patch大小為8 × 8,將256 × 128的頻譜圖編碼為512個token,碼本大小為8196。
圖像和音頻歷史記錄
模型最多允許提供四個額外的圖像和音頻片段作為輸入,這些元素也使用ViT或AST進行編碼,隨后使用感知器重采樣器,進一步將特征壓縮為較少數量(圖像為32個,音頻為16個)。
這大大縮短了序列長度,并允許模型在使用歷史記錄中的元素作為上下文時,以高細節檢查圖像或音頻片段。
穩定訓練的模型架構和技術
研究人員觀察到,隨著我們集成其他模式,使用 U-IO 之后的標準實現會導致訓練越來越不穩定。
如下圖(a)和(b)所示,僅對圖像生成(綠色曲線)進行訓練會導致穩定的損失和梯度范數收斂。
與單一模態相比,引入圖像和文本任務的組合(橙色曲線)略微增加了梯度范數,但保持穩定。然而,包含視頻模態(藍色曲線)會導致梯度范數的無限制升級。

如圖中(c)和(d)所示,當模型的XXL版本在所有模態上訓練時,損失在350k步后爆炸,下一個標記預測精度在400k步時顯著下降。
為了解決這個問題,研究人員進行了各種架構更改:
在每個Transformer層應用旋轉位置嵌入(RoPE)。對于非文本模態,將RoPE擴展到二維位置;當包括圖像和音頻模態時,將LayerNorm應用于點積注意力計算之前的Q和K。
另外,使用感知器重采樣器,將每個圖像幀和音頻片段壓縮成固定數量的標記,并使用縮放余弦注意力在感知者中應用更嚴格的歸一化,這顯著穩定了訓練。
為了避免數值不穩定,還啟用了float32注意力對數,并在預訓練期間凍結ViT和 AST,并在指令調整結束時對其進行微調。

上圖顯示,盡管輸入和輸出模態存在異質性,但模型的預訓練損失是穩定的。
多模態訓練目標
本文遵循UL2范式。對于圖像和音頻目標,這里定義了兩種類似的范式:
[R]:掩碼去噪,隨機屏蔽x%的輸入圖像或音頻補丁特征,并讓模型重新構建它;
[S]:要求模型在其他輸入模態條件下生成目標模態。
在訓練期間,用模態標記([Text]、[Image] 或 [Audio])和范式標記([R]、[S] 或 [X])作為輸入文本的前綴,以指示任務,并使用動態遮罩進行自回歸。

如上圖所示,圖像和音頻屏蔽去噪的一個問題是解碼器側的信息泄漏。
這里的解決方案是在解碼器中屏蔽token(除非在預測這個token),這不會干擾因果預測,同時又消除了數據泄漏。
效率優化
對大量多模態數據進行訓練,會導致轉換器輸入和輸出的序列長度高度可變。
這里使用打包來解決這個問題:多個示例的標記被打包到一個序列中,并屏蔽注意力以防止轉換器在示例之間交叉參與。
在訓練過程中,使用啟發式算法來重新排列流式傳輸到模型的數據,以便將長樣本與可以打包的短樣本相匹配。本文的動態打包使訓練吞吐量增加了近4倍。
指令調優
多模態指令調優是使模型具備各種模態的不同技能和能力,甚至適應新的和獨特的指令的關鍵過程。
研究人員通過結合廣泛的監督數據集和任務來構建多模態指令調優數據集。

指令調諧數據的分布如上圖所示。總體而言,指令調優組合包括60%的提示數據、30%從預訓練中繼承下來的數據(為了避免災難性的遺忘)、6%使用現有數據源構建的任務增強數據、以及4%自由格式文本(以實現類似聊天的回復)。






























