一條磁力鏈爆全網,Mixtral 8x7B論文來了!碾壓Llama 2 70B,每token僅需激活13B參數
還記得一個月前,Mistral AI突然公布的一條磁力鏈接,引爆了整個AI社區。
緊接著,Mixtral 8x7B的技術細節隨之公布,其表現不僅優于Llama 2 70B,而且推理速度提高了整整6倍。
甚至,它在大多數標準基準測試上與GPT-3.5打平,甚至略勝一籌。
今天,這家法國初創正式發布了Mixtral 8x7B混合專家模型(Mixtral of Experts)的論文。

論文地址:https://arxiv.org/abs/2401.04088
網友紛紛表示,最好的開源模型論文終于發布了。

具體技術細節,我們一探究竟。
架構
Mixtral是一個稀疏的混合專家網絡,而且是一個純解碼器模型。其中前饋塊從一組8個不同的參數組中進行選擇。
在每一層,對于每個token,路由網絡都會選擇其中的兩個組「專家」來處理token,并將它們的輸出相加。
這項技術不僅增加了模型的參數數量,而且控制了成本和延遲,因為模型每處理一個token只會使用部分參數。
具體來說,Mixtral使用32000個token的上下文信息時進行了預訓練。在多項基準測試中,它的性能達到或超過Llama 2 70B和GPT-3.5。
尤其,Mixtral在數學、代碼生成和多語言理解任務方面,表現卓越,并在這些領域顯著優于Llama 2 70B。
而且研究表明,Mixtral能夠成功地從32k token的上下文窗口中檢索信息,無論序列長度和信息在序列中的位置如何。
架構細節
Mixtra基于Transformer架構打造,并使用了「Mistral 7B」論文中一些模型修改方法。
但明顯不同的是,Mixtral完全支持32k token的全密集上下文長度,并且前饋塊被混合專家層(Mixture-of-Expert layer)所取代。先看如下表1,匯總了模型架構的具體參數。

稀疏混合專家
下圖所示,研究人員具體介紹了混合專家層。
這是一個處理輸入數據的特殊層,在這里,每個輸入數據點都會被分配給8個處理單元(稱為「專家」)中的2個。
這個分配過程是由一個路由完成的,但這里的路由并不是我們通常說的網絡設備,而是神經網絡中的一個組件,它負責決定哪些「專家」來處理特定的數據點。
每個「專家」實際上是一個處理模塊,它們各自獨立處理被分配的數據,并輸出結果。
最終,這層的輸出結果是由這2個被選中的「專家」的輸出經過特定的加權計算后得到的。
在Mixtral這個系統中,每個「專家」其實就是一個標準的前饋網絡模塊,這種模塊也被用在了我們所說的標準Transformer模型架構中。
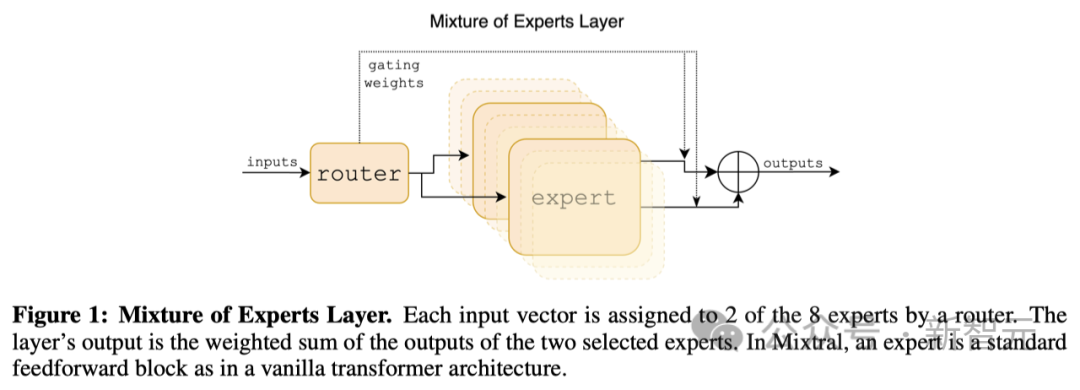
混合專家層(Mixture of Experts Layer)
MoE層可以在具有高性能專用內核的單個GPU上高效運行。
比如Megablocks將MoE層的前饋網絡(FFN)操作轉換為大型稀疏矩陣乘法,顯著提高了執行速度,并自然地處理不同專家獲得分配它們的可變數量token的情況。
此外,MoE層可以通過標準模型并行技術以及一種稱為專家并行(EP)的特殊分區策略分布到多個GPU。
在MoE層執行期間,本應由特定專家處理的token將被路由到相應的GPU進行處理,并且專家的輸出將返回到原始token位置。
結果
研究人員對Mixtral和Llama進行了對比研究,為了確保比較的公正性,并重新運行了所有的基準測試,這一次采用了內部開發的評估流程。
研究人員在多種不同的任務上進行了性能評估,這些任務可以分為以下幾類:
- 常識推理(零樣本):包括Hellaswag,Winogrande,PIQA,SIQA,OpenbookQA,ARC-Easy,ARC-Challenge,以及CommonsenseQA
- 世界知識(少樣本,5個樣本):涵蓋了NaturalQuestions和TriviaQA
- 閱讀理解(零樣本):BoolQ和QuAC
- 數學:GSM8K(少樣本,8個樣本)使用了多數投票法(maj@8),以及MATH(少樣本,4個樣本)同樣采用了多數投票法(maj@4)
- 編程代碼:Humaneval(零樣本)和MBPP(少樣本,3個樣本)
- 綜合性測試:MMLU(少樣本,5個樣本),BBH(少樣本,3個樣本),還有AGI Eval(少樣本,3至5個樣本,僅限英語選擇題)
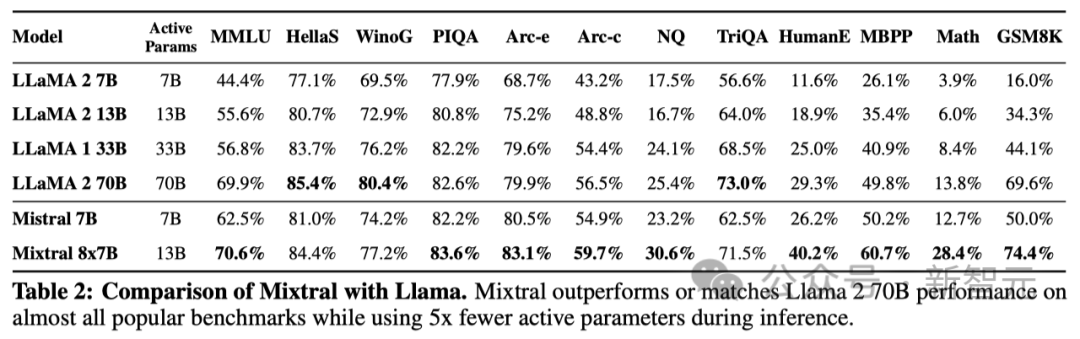
可以看到,在所有基準測試中,Mixtral的表現都超過,或至少與Llama 2 70B相當。值得一提的是,在數學和代碼生成這兩個領域,Mixtral顯著優于Llama 2 70B。

Mixtral與不同參數的Llama模型在一系列基準測試中的性能對比
如下表2展示了Mixtral 8x7B、Mistral 7B以及Llama 2 7B/13B/70B和Llama 1 34B的詳細結果。
模型參數規模與效率對比
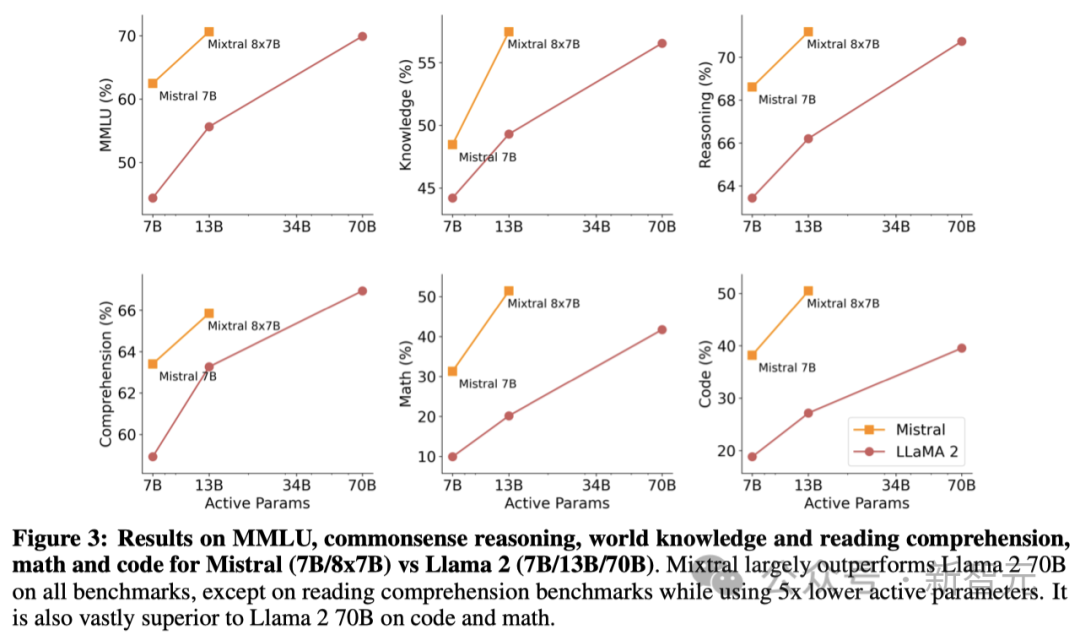
研究人員將Mixtral模型的性能與Llama 2系列做了對比,目的是要探究Mixtral在成本與性能比上的高效性(圖3)。
作為一種稀疏的混合專家模型(Sparse Mixture-of-Experts model),Mixtral每處理一個token只需激活13B參數。盡管活躍參數減少了5倍,但Mixtral在大部分領域的表現仍然超過了Llama 2 70B。
此外,需要指出的是,這項分析主要關注活躍參數的數量,這個數量直接關聯到推理階段的計算成本,不過并未涉及內存成本和硬件的使用效率。
用于運行Mixtral的內存成本與其稀疏參數的總數有關,總共為47B,這仍然比Llama 2 70B參數要少。
關于硬件的使用率,研究人員注意到由于專家模型的路由機制,SMoEs層會引入額外的計算成本。
而且當每個硬件設備運行多個專家模型時,由于內存需求增加,也會帶來更高的成本。這種模型更適用于可以實現高運算密度的批量處理任務。
與Llama 2 70B和GPT-3.5的性能比較
在表3中,研究人員展示了Mixtral 8x7B與Llama 2 70B、GPT-3.5在性能上的對比結果。
通過對比,研究人員還發現Mixtral在多個方面表現媲美,甚至超越了另外兩個模型。
在多模態學習理解(MMLU)的評測中,Mixtral盡管在模型參數量上較小(47B token對比70B),性能卻更勝一籌。
至于機器翻譯評測(MT Bench),研究人員則是報告了當前最新的GPT-3.5-Turbo模型,即gpt-3.5-turbo-1106版本的性能數據。
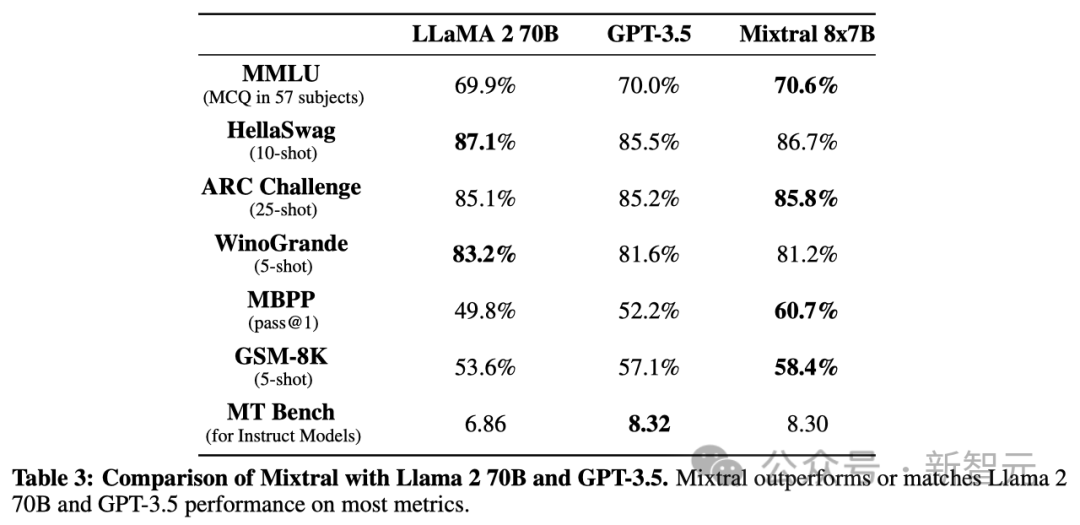
可以看到,在所有基準測試中,Mixtral的表現普遍優于Llama 2 70B,唯一的例外是在閱讀理解基準測試中,當其激活參數數量僅為Llama 2 70B的1/5時。
特別是在代碼和數學領域,Mixtral顯著勝過Llama 2 70B。
Mixtral(7B/8x7B)與 Llama 2(7B/13B/70B)在MMLU、常識推理、世界知識、閱讀理解、數學和代碼方面的比較結果
多語言基準
與Mistral 7B相比較,研究人員在模型預訓練階段,顯著提高了多語言數據的比重。
這種增加的模型參數讓Mixtral在多語種的性能評估中表現出色,同時還不損失對英語的準確度。
尤其值得一提的是,Mixtral在處理法語、德語、西班牙語和意大利語的任務上,明顯勝過了Llama 2 70B,具體成績可以參見表4。

長距離性能
為了檢驗Mixtral在處理涉及廣泛信息的情境下的表現,研究人員還提出了一項稱為passkey檢索的任務對其進行測試。
這項任務是專門設計來評估模型在面對一個包含隨機插入的passkey的長篇提示信息時,恢復passkey的能力。
圖4(左)的結果表明,無論上下文有多長或者passkey出現在文本序列的哪個位置,Mixtral都能保持100%的恢復精度。
而圖4(右)則展示了Mixtral在proof-pile數據集的一個子集上的困惑度(perplexity),隨著上下文量的增加,其困惑度呈現出單調下降的趨勢。

指令微調
此外,研究人員還開發了Mixtral–Instruct模型,首先在一個指令數據集上進行了監督微調(SFT),然后在一個成對的反饋數據集上采用了直接偏好優化(DPO)。
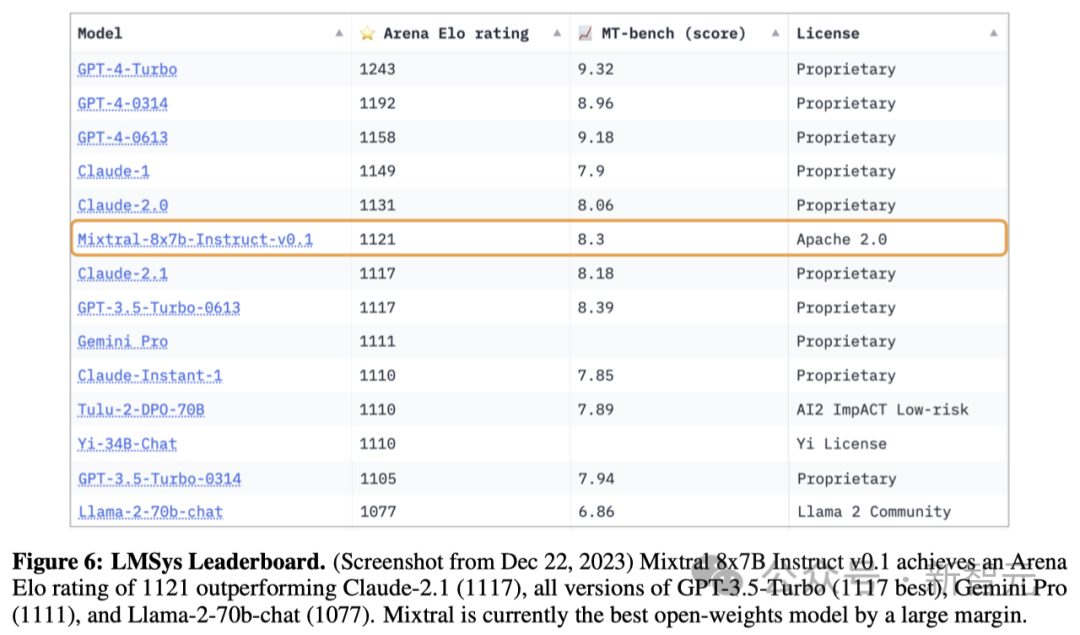
在MT-Bench的評估中,Mixtral–Instruct取得了8.30的高分(表2),成為了截至2023年12月表現最佳的開源權重模型。
LMSys進行的人工評估結果顯示在圖6,結果表明Mixtral–Instruct的表現超越了GPT-3.5-Turbo、Gemini Pro、Claude-2.1以及Llama 2 70B chat模型。
路由分析
最后,研究人員對路由器如何選擇「專家」進行了簡要分析。特別是在訓練期間,是否會有「專家」選擇專攻某些特定的領域(如數學、生物學、哲學等)。
為了探究這一點,研究人員對The Pile驗證數據集的不同子集進行了「專家」選擇分布的測量,結果如圖7所示。涉及模型的第0層、第15層和第31層(最后一層)。
出乎意料的是,這里并沒有發現明顯的基于主題分配「專家」的模式。
比如,在所有層中,無論是arXiv論文(用LaTeX編寫)、生物學領域(PubMed摘要)還是哲學領域(PhilPapers文件),「專家」的分配分布都非常相似。
只有在數學領域(DM Mathematics)中,「專家」的分布略有不同。
研究人員認為,這種差異可能是因為數據集本身是合成的,且對自然語言的覆蓋上有限,尤其是在模型的第一層和最后一層,隱藏狀態分別與輸入和輸出嵌入高度相關。
而這也表明,路由器確實表現出了一些結構化的句法行為。
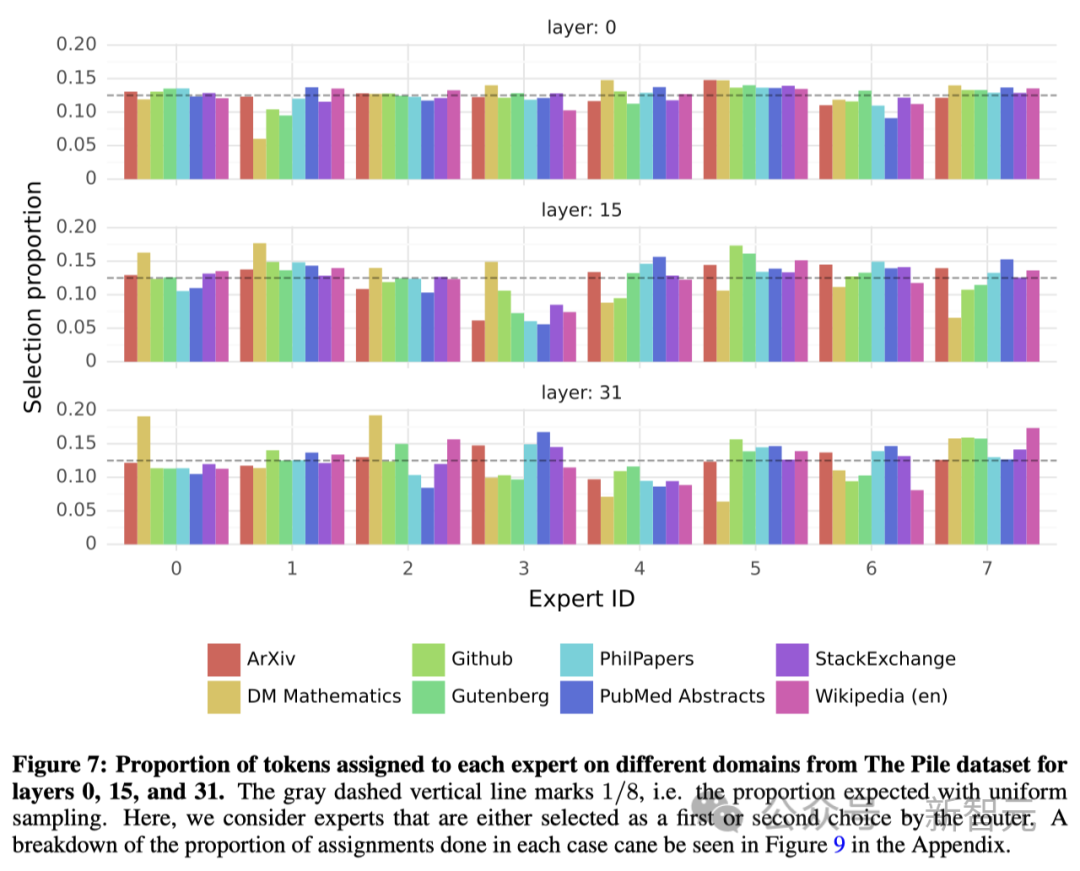
圖8展示了不同領域(Python 代碼、數學和英語)的文本示例。其中,每個token都用不同的背景色標注,便于查看對應分配到的「專家」。
可以發現,像Python中的「self」和英文中的「Question」這樣的詞語,雖然包含有多個token,但往往被分配給同一個「專家」。同樣,相鄰的token也會被分配給同一位「專家」。
在代碼中,縮進的token也總是被指派給相同的「專家」,這一點在模型的第一層和最后一層尤為顯著,因為這些層的隱藏狀態與模型的輸入和輸出更加緊密相關。
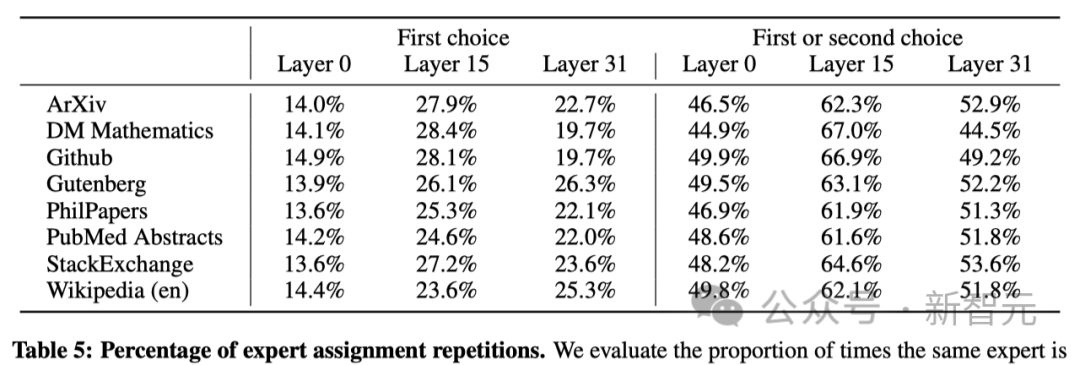
此外,根據The Pile數據集,研究人員還發現了一些位置上的鄰近性(positional locality)。

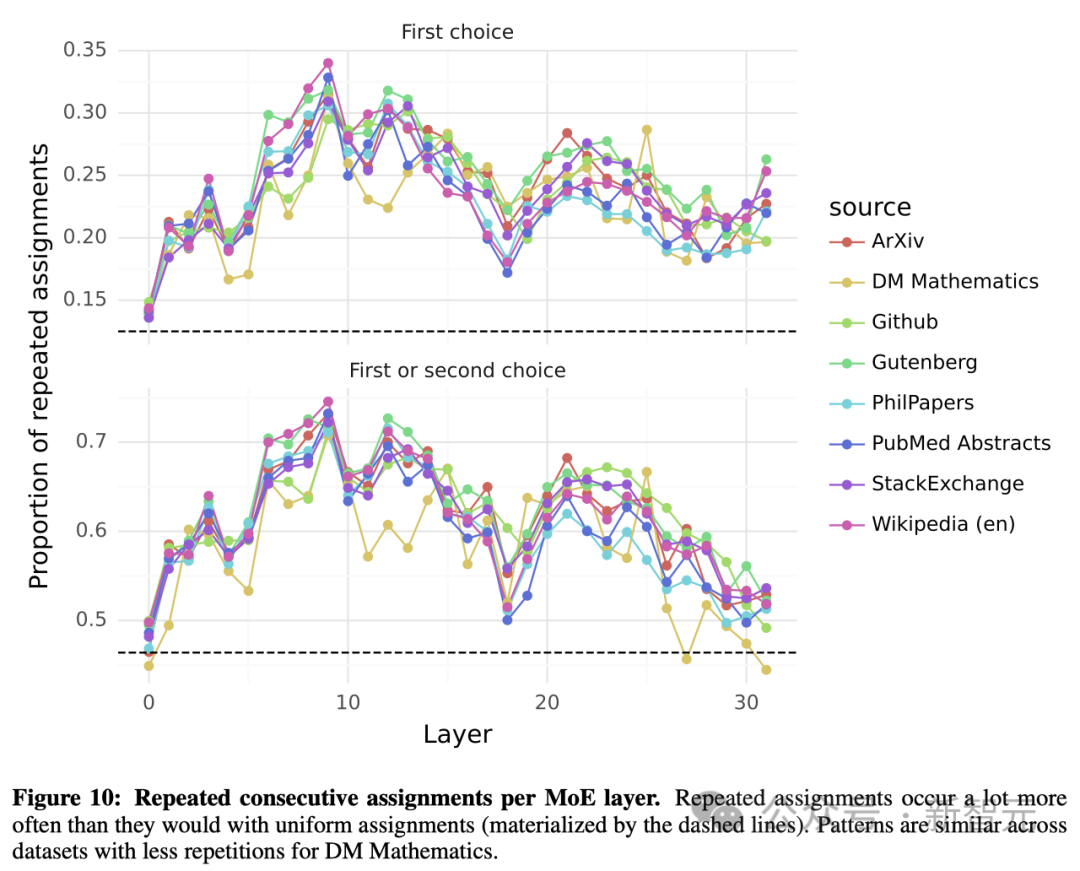
表5展示了在不同領域和網絡層中,連續token被同一個「專家」選中的比例。
在網絡的上層,這種連續性的重復分配遠高于隨機分配的概率。這一現象對于模型的優化——加速訓練和推理過程,有重要的啟示。
例如,在專家并行(Expert Parallelism)處理中,那些位置上具有高鄰近性的情況更容易導致某些「專家」被過度使用。不過,這種鄰近性也可以用于緩存技術。
關于這些「專家」被選擇的頻率,圖10提供了一個更全面的視角,涵蓋了所有網絡層和不同的數據集。
結論
在這篇論文中,研究人員介紹了第一個性能達到SOTA的開源專家混合網絡——Mixtral 8x7B。
在人類評估基準中,Mixtral 8x7B Instruct的表現超越了Claude-2.1、Gemini Pro以及GPT-3.5-Turbo。
Mixtral的一大特點是,它在處理每個token時,僅激活使用13B參數,而這一數值遠低于Llama 2 70B所使用的70B參數。
現在,研究人員已經把訓練和微調后的模型在Apache 2.0開源許可下公開,以便社區成員可以自由使用。