我被 Parallel 函數雷了
一、問題&分析
性能優化是技術人的永恒話題,當我們遇到性能問題時,你的第一反應是什么?
數據庫索引優化,緩存優化,算法優化?
但,有時性能殺手往往就是性能優化引入的。
1.1. 案例
今天一大早,小艾剛到公司便收到一組系統報警,原來有一個接口報了一堆的慢情況。仔細排查,發現是前兩天為服務域提供的一個訂單的查詢接口,該接口剛上線不久,正處于放量階段,小艾立即驚出一身冷汗,不會是數據庫出現了 慢SQL?記得上線前通過 explain 指令對 sql 進行過分析,明確已經使用了數據庫索引。他趕緊打開阿里云控制臺,快速進入 慢查詢功能進行查看,但奇怪的是監控顯示沒有一條 慢查詢,真是太詭異了。
還好不是數據庫慢查詢,不然可能存在將整個 MySQL 數據庫拖垮的可能,小艾的懸著的心也終于放了下來。
可問題出在哪里呢?
這個查詢接口非常簡單,示例代碼如下:
@GetMapping("getOrdersByUsers")
public RestResult<List<OrderVO>> allOrderByUsers(@RequestParam List<Long> users){
Stopwatch stopwatch = Stopwatch.createStarted();
List<Order> orders = getByUserId(users);
List<OrderVO> orderVOS = orders.stream()
.map(order -> OrderVO.applyByParallel(order))
.collect(Collectors.toList());
log.info("get order by user cost {} ms", stopwatch.stop().elapsed(TimeUnit.MILLISECONDS));
return RestResult.success(orderVOS);
}邏輯簡單到令人發指,只有兩步:
- 根據傳入的 user id 從數據庫中查詢訂單
- 將查詢的 Order 轉換為 OrderVO 返回用戶
小艾,仔細觀察這個接口,發現一個現象:當入參較多時,接口的性能變的非常差。
這個也比較好理解,系統使用的是 in 語句對數據進行查詢,示例:select * from order_info where user_id in (?),當入參數據量非常大時,sql 執行耗時變高。這可能是一個原因,但MySQL 慢請求中未記錄任何信息,說明 sql 的執行時間沒有超過 1 秒,所以,這個只是一個表因。
為了更好的驗證猜想,小艾對日志進行完善,整體如下:
@GetMapping("getOrdersByUsers")
public RestResult<List<OrderVO>> allOrderByUsers(@RequestParam List<Long> users){
Stopwatch stopwatch = Stopwatch.createStarted();
List<Order> orders = getByUserId(users);
log.info("get data from DB cost {} ms", stopwatch.stop().elapsed(TimeUnit.MILLISECONDS));
stopwatch = Stopwatch.createStarted();
List<OrderVO> orderVOS = orders.stream()
.map(order -> OrderVO.applyByParallel(order))
.collect(Collectors.toList());
log.info("convert to OrderVO cost {} ms", stopwatch.stop().elapsed(TimeUnit.MILLISECONDS));
return RestResult.success(orderVOS);
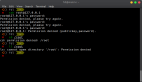
}選了幾個訂單較多的用戶進行測試,打印日志如下:
 圖片
圖片
好奇怪,數據庫操作耗時有限,但 Order 向 OrderVO 的轉換居然耗時這么多,真是太不可思議!
1.2. 問題分析
很明顯是轉化這步出了問題,其核心代碼如下所示:
// 使用 Stream 流進行類型轉化
List<OrderVO> orderVOS = orders.stream()
.map(order -> OrderVO.applyByParallel(order))
.collect(Collectors.toList());
// Order 到 OrderVO 的轉化邏輯
public static OrderVO applyByParallel(Order order){
OrderVO orderVO = new OrderVO();
orderVO.setId(order.getId());
orderVO.setUserId(order.getUserId());
orderVO.setStatus(OrderStatus.parallelParseByCode(order.getOrderStatus()));
orderVO.setOrderType(OrderType.parallelParseByCode(order.getOrderType()));
orderVO.setProductType(ProductType.parallelParseByCode(order.getProductType()));
orderVO.setPromotionType(PromotionType.parallelParseByCode(order.getPromotionType()));
return orderVO;
}
// 將 Code 轉換為對應的枚舉
public static OrderStatus parallelParseByCode(int code) {
return Stream.of(values())
.parallel()
.filter(status -> status.getCode() == code)
.findFirst()
.orElse(null);
}看完核心代碼,請思考幾分鐘,問題可能出現在哪里?
- Stream 操作?Stream 比 for 循環性能超差些,但還不至于有這么大差異
- 反射、BeanCopy?核心代碼沒有使用這些 API,乖乖的進行 Coding
那問題究竟在哪?答案是 Stream 的 parallel() 函數。使用 parallel 函數最初的目標便是提升性能,為什么在這里卻成了性能殺手?在解答前,先快速了解下這個函數:
`Stream.parallel()` 函數是 Java 8 中引入的新特性,底層采用了 Fork/Join 框架來實現并行處理。當你調用 `parallel()` 函數時,實際上是將流的并行性設計為 true。這意味著所進行的任何操作,如 `map` 或 `filter`,都是在并行流(parallel stream)上執行的。Fork/Join 框架首先會將一個大任務拆分成若干個小任務(Fork),然后分別對這些小任務進行處理,最后將得到的結果合并(Join)來得到最終結果。
這種方式能有效地將任務進行了分解,使得每個線程都可以獨立地處理一部分任務,從而發揮了多核 CPU 的優勢,提高了整體的處理效率。
從上述解釋中可以看出,parallel 底層使用 Fork/Join 框架,對任務進行拆解,可以發揮多核的優勢,那怎么就成了性能殺手呢?
先看下 Fork/Join 的整體執行流程:
 圖片
圖片
其執行主要分為以下幾個階段:
- 分割階段(Fork Phase):將大任務拆分成若干個小任務,直到任務的規模足夠小,可以直接執行。這通常是通過遞歸方式實現的。
- 執行階段(Computation Phase):執行每個小任務,并生成結果。
- 結果合并階段(Join Phase):合并小任務的結果,生成大任務的結果。這也通常通過遞歸的方式實現,與拆分階段對應。
- 善后階段(Finalize Phase):所有任務的結果都已合并完畢,大任務的結果也已經生成,可以進行善后工作,比如釋放資源等。
每個階段都有一定開銷,從整個執行流程上看,執行階段占的時間越長,性能提升就越高。在數據量較少,或者執行操作開銷較大時,并行處理不但不能提高性能,還會由于線程管理和任務分配的開銷而導致性能下降。
再次回到上面這個案例:
// 將 Code 轉換為對應的枚舉
public static OrderStatus parallelParseByCode(int code) {
return Stream.of(values())
.parallel()
.filter(status -> status.getCode() == code)
.findFirst()
.orElse(null);
}首先,枚舉的數量非常小,其次,執行邏輯非常簡單,僅進行一個等值比較。在這種情況下使用 parallel 函數,將致使線程管理和任務分配開銷巨大,從而成為系統瓶頸。
二、解決方案
既然問題是通過 parallel 函數引入的,那解決方案便是:刪除 parallel 函數調用,直接串行執行即可。
修改后的代碼如下:
public static OrderStatus parseByCode(int code) {
return Stream.of(values())
// .parallel() 直接使用串行執行
.filter(status -> status.getCode() == code)
.findFirst()
.orElse(null);
}使用相同的數據重新測試,耗時如下圖所示:
 圖片
圖片
可見,性能直接提升 10 倍不止。
三、示例&源碼
代碼倉庫:https://gitee.com/litao851025/learnFromBug
代碼地址:https://gitee.com/litao851025/learnFromBug/tree/master/src/main/java/com/geekhalo/demo/thread/parallelfun