驚訝!我定的日志規范被CTO在全公司推廣了
打印日志是一門藝術,但長期被開發同學所忽視。日志就像車輛保險,沒人愿意為保險付錢,但是一旦出了問題又都想有保險可用。
圖片來自 Pexels
我們打印日志的時候都很隨意,可是用的時候會吐槽各種 SB 包括自己!寫好每一條日志吧,與君共勉!
日志是什么?
日志,維基百科的定義是記錄服務器等電腦設備或軟件的運作。
日志文件提供精確的系統記錄,根據日志最終定位到錯誤詳情和根源。日志的特點是,它描述一些離散的(不連續的)事件。
例如:應用通過一個滾動的文件輸出 INFO 或 ERROR 信息,并通過日志收集系統,存儲到一些存儲引擎(Elasticsearch)中方便查詢。
日志有什么用?
在上文中我們解釋了日志的作用是提供精準的系統記錄方便根因分析。那么具體在哪些具體方面它可以發揮作用?
①打印調試:即可以用日志來記錄變量或者某一段邏輯。記錄程序運行的流程,即程序運行了哪些代碼,方便排查邏輯問題。
②問題定位:程序出異常或者出故障時快速的定位問題,方便后期解決問題。因為線上生產環境無法 DEBUG,在測試環境去模擬一套生產環境,費時費力。
所以依靠日志記錄的信息定位問題,這點非常重要。還可以記錄流量,后期可以通過 ELK(包括 EFK 進行流量統計)。
③用戶行為日志:記錄用戶的操作行為,用于大數據分析,比如監控、風控、推薦等等。
這種日志,一般是給其他團隊分析使用,而且可能是多個團隊,因此一般會有一定的格式要求,開發者應該按照這個格式來記錄,便于其他團隊的使用。
當然,要記錄哪些行為、操作,一般也是約定好的,因此,開發者主要是執行的角色。
④根因分析(甩鍋必備):即在關鍵地方記錄日志。方便在和各個終端定位問題時,別人說是你的程序問題,你可以理直氣壯的拿出你的日志說,看,我這里運行了,狀態也是對的。這樣,對方就會乖乖去定位他的代碼,而不是互相推脫。
什么時候記錄日志?
上文說了日志的重要性,那么什么時候需要記錄日志?
①系統初始化:系統或者服務的啟動參數。核心模塊或者組件初始化過程中往往依賴一些關鍵配置,根據參數不同會提供不一樣的服務。務必在這里記錄 INFO 日志,打印出參數以及啟動完成態服務表述。
②編程語言提示異常:如今各類主流的編程語言都包括異常機制,業務相關的流行框架有完整的異常模塊。
這類捕獲的異常是系統告知開發人員需要加以關注的,是質量非常高的報錯。應當適當記錄日志,根據實際結合業務的情況使用 WARN 或者 ERROR 級別。
③業務流程預期不符:除開平臺以及編程語言異常之外,項目代碼中結果與期望不符時也是日志場景之一,簡單來說所有流程分支都可以加入考慮。
取決于開發人員判斷能否容忍情形發生。常見的合適場景包括外部參數不正確,數據處理問題導致返回碼不在合理范圍內等等。
④系統核心角色,組件關鍵動作:系統中核心角色觸發的業務動作是需要多加關注的,是衡量系統正常運行的重要指標,建議記錄 INFO 級別日志。
比如電商系統用戶從登錄到下單的整個流程;微服務各服務節點交互;核心數據表增刪改;核心組件運行等等,如果日志頻度高或者打印量特別大,可以提煉關鍵點 INFO 記錄,其余酌情考慮 DEBUG 級別。
⑤第三方服務遠程調用:微服務架構體系中有一個重要的點就是第三方永遠不可信,對于第三方服務遠程調用建議打印請求和響應的參數,方便在和各個終端定位問題,不會因為第三方服務日志的缺失變得手足無措。
日志打印
Slf4j&Logback
Slf4j 英文全稱為 “ Simple Logging Facade for Java ”,為 Java 提供的簡單日志門面。
Facade 門面,更底層一點說就是接口。它允許用戶以自己的喜好,在工程中通過 Slf4j 接入不同的日志系統。
Logback 是 Slf4j 的原生實現框架,同樣也是出自 Log4j 一個人之手,但擁有比 Log4j 更多的優點、特性和更做強的性能,Logback 相對于 Log4j 擁有更快的執行速度。
基于我們先前在 Log4j 上的工作,Logback 重寫了內部的實現,在某些特定的場景上面,甚至可以比之前的速度快上 10 倍。在保證 Logback 的組件更加快速的同時,同時所需的內存更加少。
日志文件
日志文件放置于固定的目錄中,按照一定的模板進行命名,推薦的日志文件名稱:
- 當前正在寫入的日志文件名:<應用名>[-<功能名>].log
- 如:example-server-book-service-access.log
- 已經滾入歷史的日志文件名:<應用名>[-<功能名>].yyyy-MM-dd-hh.[滾動號].log
- 如:example-server-book-service-access.2019-12-01-10.1.log
日志變量定義
推薦使用 lombok(代碼生成器) 注解 @lombok.extern.slf4j.Slf4j 來生成日志變量實例:
- <!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- <version>1.18.10</version>
- <scope>provided</scope>
- </dependency>
代碼示例:
- import lombok.extern.slf4j.Slf4j;
- @Slf4j
- public class LogTest {
- public static void main(String[] args) {
- log.info("this is log test");
- }
- }
日志配置
日志記錄采用分級記錄,級別與日志文件名相對應,不同級別的日志信息記錄到不同的日志文件中。
如有特殊格式日志,如 access log,單獨使用一個文件,請注意避免重復打印(可使用 additivity="false" 避免 )。
參數占位格式
使用參數化形式 {} 占位,[] 進行參數隔離,這樣的好處是可讀性更高,而且只有真正準備打印的時候才會處理參數。
- // 正確示例,必須使用參數化信息的方式
- log.debug("order is paying with userId:[{}] and orderId : [{}]",userId, orderId);
- // 錯誤示例,不要進行字符串拼接,那樣會產生很多 String 對象,占用空間,影響性能。及日志級別高于此級別也會進行字符串拼接邏輯。
- log.debug("order is paying with userId: " + userId + " and orderId: " + orderId);
日志的基本格式
①日志時間
作為日志產生的日期和時間,這個數據非常重要,一般精確到毫秒。
yyyy-MM-dd HH:mm:ss.SSS
②日志級別
日志的輸出都是分級別的,不同的設置不同的場合打印不同的日志。主要使用如下的四個級別:
DEBUG:DEUBG 級別的主要輸出調試性質的內容,該級別日志主要用于在開發、測試階段輸出。
該級別的日志應盡可能地詳盡,開發人員可以將各類詳細信息記錄到 DEBUG 里,起到調試的作用,包括參數信息,調試細節信息,返回值信息等等,便于在開發、測試階段出現問題或者異常時,對其進行分析。
INFO:INFO 級別的主要記錄系統關鍵信息,旨在保留系統正常工作期間關鍵運行指標,開發人員可以將初始化系統配置、業務狀態變化信息,或者用戶業務流程中的核心處理記錄到 INFO 日志中,方便日常運維工作以及錯誤回溯時上下文場景復現。
建議在項目完成后,在測試環境將日志級別調成 INFO,然后通過 INFO 級別的信息看看是否能了解這個應用的運用情況,如果出現問題后是否這些日志能提供有用的排查問題的信息。
WARN:WARN 級別的主要輸出警告性質的內容,這些內容是可以預知且是有規劃的,比如,某個方法入參為空或者該參數的值不滿足運行該方法的條件時。在 WARN 級別的時應輸出較為詳盡的信息,以便于事后對日志進行分析。
ERROR:ERROR 級別主要針對于一些不可預知的信息,諸如:錯誤、異常等,比如,在 catch 塊中抓獲的網絡通信、數據庫連接等異常,若異常對系統的整個流程影響不大,可以使用 WARN 級別日志輸出。
在輸出 ERROR 級別的日志時,盡量多地輸出方法入參數、方法執行過程中產生的對象等數據,在帶有錯誤、異常對象的數據時,需要將該對象一并輸出。
③DEBUG/INFO 的選擇
DEBUG 級別比 INFO 低,包含調試時更詳細的了解系統運行狀態的東西,比如變量的值等等,都可以輸出到 DEBUG 日志里。
INFO 是在線日志默認的輸出級別,反饋系統的當前狀態給最終用戶看的。輸出的信息,應該對最終用戶具有實際意義的。
從功能角度上說,INFO 輸出的信息可以看作是軟件產品的一部分,所以需要謹慎對待,不可隨便輸出。
如果這條日志會被頻繁打印或者大部分時間對于糾錯起不到作用,就應當考慮下調為 DEBUG 級別:
- 由于 DEBUG 日志打印量遠大于 INFO,出于前文日志性能的考慮,如果代碼為核心代碼,執行頻率非常高,務必推敲日志設計是否合理,是否需要下調為 DEBUG 級別日志。
- 注意日志的可讀性,不妨在寫完代碼 review 這條日志是否通順,能否提供真正有意義的信息。
- 日志輸出是多線程公用的,如果有另外一個線程正在輸出日志,上面的記錄就會被打斷,最終顯示輸出和預想的就會不一致。
④WARN/ERROR 的選擇
當方法或者功能處理過程中產生不符合預期結果或者有框架報錯時可以考慮使用。
常見問題處理方法包括:
- 增加判斷處理邏輯,嘗試本地解決:增加邏輯判斷吞掉報警永遠是最優選擇拋出異常,交給上層邏輯解決
- 拋出異常,交給上層邏輯解決
- 記錄日志,報警提醒
- 使用返回碼包裝錯誤做返回
一般來說,WARN 級別不會短信報警,ERROR 級別則會短信報警甚至電話報警,ERROR 級別的日志意味著系統中發生了非常嚴重的問題,必須有人馬上處理,比如數據庫不可用,系統的關鍵業務流程走不下去等等。
錯誤的使用反而帶來嚴重的后果,不區分問題的重要程度,只要有問題就 ERROR 記錄下來。
其實這樣是非常不負責任的,因為對于成熟的系統,都會有一套完整的報錯機制,那這個錯誤信息什么時候需要發出來,很多都是依據單位時間內 ERROR 日志的數量來確定的。
⑤強調 ERROR 報警
ERROR 級別的日志打印通常伴隨報警通知。ERROR 的報出應該伴隨著業務功能受損,即上面提到的系統中發生了非常嚴重的問題,必須有人馬上處理。
ERROR 日志目標:給處理者直接準確的信息,ERROR 信息形成自身閉環。
問題定位:
- 發生了什么問題,哪些功能受到影響
- 獲取幫助信息:直接幫助信息或幫助信息的存儲位置
- 通過報警知道解決方案或者找何人解決
⑥線程名稱
輸出該日志的線程名稱,一般在一個應用中一個同步請求由同一線程完成,輸出線程名稱可以在各個請求產生的日志中進行分類,便于分清當前請求上下文的日志。
⑦opentracing 標識
在分布式應用中,用戶的一個請求會調用若干個服務完成,這些服務可能還是嵌套調用的,因此完成一個請求的日志并不在一個應用的日志文件,而是分散在不同服務器上不同應用節點的日志文件中。
該標識是為了串聯一個請求在整個系統中的調用日志:
- 唯一字符串(trace id)
- 調用層級(span id)
通過搜索 trace id 就可以查到這個 trace id 標識的請求在整個系統中流轉(處理)過程中產生的所有日志。
⑧biz 標識
在業務開發中,我們的日志都是和業務相關聯的,有時候是需要根據用戶或者業務做聚類的,因此一次請求如果可以通過某項標識做聚類的時候,可以將聚類標識打印到日志中:
- 用戶標識(user id)
- 業務標識(biz id)
⑨日志記錄器名稱
日志記錄器名稱一般使用類名,日志文件中可以輸出簡單的類名即可,看實際情況是否需要使用包名和行號等信息。主要用于看到日志后到哪個類中去找這個日志輸出,便于定位問題所在。
⑩日志內容
禁用 System.out.println 和 System.err.println。
變參替換日志拼接,輸出日志的對象,應在其類中實現快速的 toString 方法,以便于在日志輸出時僅輸出這個對象類名和 hashCode。
預防空指針:不要在日志中調用對象的方法獲取值,除非確保該對象肯定不為 null,否則很有可能會因為日志的問題而導致應用產生空指針異常。
⑪異常堆棧
異常堆棧一般會出現在 ERROR 或者 WARN 級別的日志中,異常堆棧含有方法調用鏈的系統,以及異常產生的根源。異常堆棧的日志屬于上一行日志的,在日志收集時需要將其劃至上一行中。
最佳實踐
①日志格式
2019-12-01 00:00:00.000|pid|log-level|[svc-name,trace-id,span-id,user-id,biz-id]|thread-name|package-name.class-name : log message
日志格式如下:
- 時間
- pid,pid
- log-level,日志級別
- svc-name,應用名稱
- trace-id,調用鏈標識
- span-id,調用層級標識
- user-id,用戶標識
- biz-id,業務標識
- thread-name,線程名稱
- package-name.class-name,日志記錄器名稱
- log message,日志消息體
②日志模塊擴展
日志模塊是基于以下技術點做擴展的:
- Slf4j MDC 實現原理。
- Opentracing Scope 原理。
在每個 tracing 鏈路中,將 Opentracing Scope 中的上下文信息放置 MDC 中,根據 Spring Boot Logging 擴展接口擴展的取值邏輯 logging.pattern.level 的取值邏輯。
相關源碼參考:
- Spring Cloud Sleuth:
- https://github.com/spring-cloud/spring-cloud-sleuth/blob/master/spring-cloud-sleuth-core/src/main/java/org/springframework/cloud/sleuth/autoconfig/TraceEnvironmentPostProcessor.java
- https://github.com/spring-cloud/spring-cloud-sleuth/blob/master/spring-cloud-sleuth-core/src/main/java/org/springframework/cloud/sleuth/log/Slf4jCurrentTraceContext.java
修改 logback 配置文件中每個 appender 的 pattern 為以下默認值即可實現標準化。
- %d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}|${PID:- }|%level|${LOG_LEVEL_PATTERN:-%5p}|%t|%-40.40logger{39}: %msg%n
logback.xml 節選:
- <configuration><property name="LOG_PATH"
- value="${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}"/>
- <springProperty scope="context" name="APP_NAME"
- source="spring.application.name" defaultValue="spring-boot-fusion"/>
- <!-- 全局統一 pattern -->
- <property name="LOG_PATTERN"
- value="%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}|${PID:- }|%level|${LOG_LEVEL_PATTERN:-%5p}|%t|%-40.40logger{39}: %msg%n"/>
- <!-- 輸出模式 file,滾動記錄文件,先將日志文件指定到文件,當符合某個條件時,將日志記錄到其他文件 -->
- <appender name="fileInfo" class="ch.qos.logback.core.rolling.RollingFileAppender">
- <!--被寫入的文件名,可以是相對目錄,也可以是絕對目錄,如果上級目錄不存在會自動創建,沒有默認值。-->
- <file>${LOG_PATH}/${APP_NAME}-info.log</file>
- <!--滾動策略 基于時間的分包策略 -->
- <rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
- <!-- yyyy-MM-dd 時間策略則為一天一個文件 -->
- <FileNamePattern>${LOG_PATH}/${APP_NAME}-info.%d{yyyy-MM-dd-HH}.%i.log</FileNamePattern>
- <!--日志文件保留小時數-->
- <MaxHistory>48</MaxHistory>
- <maxFileSize>1GB</maxFileSize>
- <totalSizeCap>20GB</totalSizeCap>
- </rollingPolicy>
- <!-- layout 負責把事件轉換成字符串,格式化的日志信息的輸出 -->
- <layout class="ch.qos.logback.classic.PatternLayout">
- <pattern>${LOG_PATTERN}</pattern>
- </layout>
- <!--級別過濾器,根據日志級別進行過濾。如果日志級別等于配置級別,過濾器會根據onMath 和 onMismatch接收或拒絕日志-->
- <filter class="ch.qos.logback.classic.filter.LevelFilter">
- <!--設置過濾級別-->
- <level>INFO</level>
- <!--用于配置符合過濾條件的操作-->
- <onMatch>ACCEPT</onMatch>
- <!--用于配置不符合過濾條件的操作-->
- <onMismatch>DENY</onMismatch>
- </filter>
- </appender>
- </configuration>
代碼使用示例:
- @Override
- public Result<PagingObject<SimpleResponse>> page(@RequestParam(value = "page-num", defaultValue = "1") int pageNum,
- @RequestParam(value = "page-size", defaultValue = "10") int pageSize) {
- LogStandardUtils.putUserId("userId123");
- LogStandardUtils.putBizId("bizId321");
- producerService.sendMsg("xxx");
- simpleClient.page(pageNum, pageSize);
- return new Result<>(simpleService.page(pageNum, pageSize));
- }
日志記錄:
- 2019-12-04 16:29:08.223|43546|INFO|[example-server-book-service,ac613cff04bac8b1,4a9adc10fdf0eb5,userId123,bizId321]|XNIO-1 task-4|c.n.u.concurrent.ShutdownEnabledTimer : Shutdown hook installed for: NFLoadBalancer-PingTimer-example-server-order-service
- 2019-12-04 16:29:08.224|43546|INFO|[example-server-book-service,ac613cff04bac8b1,4a9adc10fdf0eb5,userId123,bizId321]|XNIO-1 task-4|c.netflix.loadbalancer.BaseLoadBalancer : Client: example-server-order-service instantiated a LoadBalancer: DynamicServerListLoadBalancer:{NFLoadBalancer:name=example-server-order-service,current list of Servers=[],Load balancer stats=Zone stats: {},Server stats: []}ServerList:null
- 2019-12-04 16:29:08.234|43546|INFO|[example-server-book-service,ac613cff04bac8b1,4a9adc10fdf0eb5,userId123,bizId321]|XNIO-1 task-4|c.n.l.DynamicServerListLoadBalancer : Using serverListUpdater PollingServerListUpdater
- 2019-12-04 16:29:08.247|43546|INFO|[example-server-book-service,ac613cff04bac8b1,4a9adc10fdf0eb5,userId123,bizId321]|XNIO-1 task-4|c.n.l.DynamicServerListLoadBalancer : DynamicServerListLoadBalancer for client example-server-order-service initialized: DynamicServerListLoadBalancer:{NFLoadBalancer:name=example-server-order-service,current list of Servers=[],Load balancer stats=Zone stats: {},Server stats: []}ServerList:ConsulServerList{serviceId='example-server-order-service', tag=null}
- 2019-12-04 16:29:08.329|43546|WARN|[example-server-book-service,ac613cff04bac8b1,4a9adc10fdf0eb5,userId123,bizId321]|XNIO-1 task-4|c.p.f.l.ctl.common.rule.StrategyRule : No up servers available from load balancer: DynamicServerListLoadBalancer:{NFLoadBalancer:name=example-server-order-service,current list of Servers=[],Load balancer stats=Zone stats: {},Server stats: []}ServerList:ConsulServerList{serviceId='example-server-order-service', tag=null}
- 2019-12-04 16:29:08.334|43546|WARN|[example-server-book-service,ac613cff04bac8b1,4a9adc10fdf0eb5,userId123,bizId321]|XNIO-1 task-4|c.p.f.l.ctl.common.rule.StrategyRule : No up servers available from load balancer: DynamicServerListLoadBalancer:{NFLoadBalancer:name=example-server-order-service,current list of Servers=[],Load balancer stats=Zone stats: {},Server stats: []}ServerList:ConsulServerList{serviceId='example-server-order-service', tag=null}
- 2019-12-04 16:29:08.342|43546|ERROR|[example-server-book-service,ac613cff04bac8b1,4a9adc10fdf0eb5,userId123,bizId321]|XNIO-1 task-4|c.p.f.w.c.advice.ExceptionHandlerAdvice : 當前程序進入到異常捕獲器,出錯的 url 為:[ http://127.0.0.1:10011/simples ],出錯的參數為:[ {"querystring":"{}","payload":""} ]
- java.lang.RuntimeException: com.netflix.client.ClientException: Load balancer does not have available server for client: example-server-order-service
日志服務
SLS 阿里云日志服務
阿里云日志服務(簡稱 SLS)是針對日志類數據的一站式服務,在阿里巴巴集團經歷大量大數據場景錘煉而成。
您無需開發就能快捷完成日志數據采集、消費、投遞以及查詢分析等功能,提升運維、運營效率,建立 DT 時代海量日志處理能力。
project:項目、管理日志基礎單元,服務日志建議一個環境建為一個 Project,這樣日志記錄是整體一個閉環,日志記錄隨整個環境內的服務調用產生。
logstore:日志庫,日志庫建議按照日志類型分為不同的,如特定格式的 access 日志,以及 info / warn / error 日志,特定格式可以配置更為方面的索引以及告警設置。
注意:請勿按照應用服務區分為不同的 logstore,在微服務架構中,一次請求交叉了多個應用服務,日志是散落在各個應用服務中的,按照服務區分 logstore,需要開發同學十分了解應用運行狀況和調用拓撲圖,這點往往是不具備的。
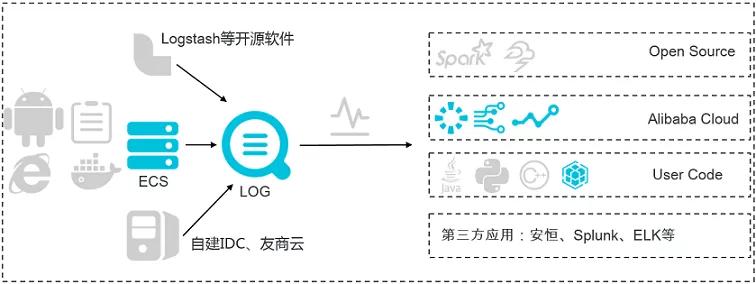
①實時采集與消費
功能:
- 通過 ECS、容器、移動端、開源軟件、JS 等接入實時日志數據(例如 Metric、Event、BinLog、TextLog、Click 等)。
- 提供實時消費接口,與實時計算及服務對接。
用途:數據清洗(ETL)、流計算(Stream Compute)、監控與報警、 機器學習與迭代計算。
②查詢分析
實時索引、查詢分析數據:
- 查詢:關鍵詞、模糊、上下文、范圍。
- 統計:SQL聚合等豐富查詢手段。
- 可視化:Dashboard+報表功能。
- 對接:Grafana、JDBC/SQL92。
用途:DevOps / 線上運維,日志實時數據分析,安全診斷與分析,運營與客服系統。
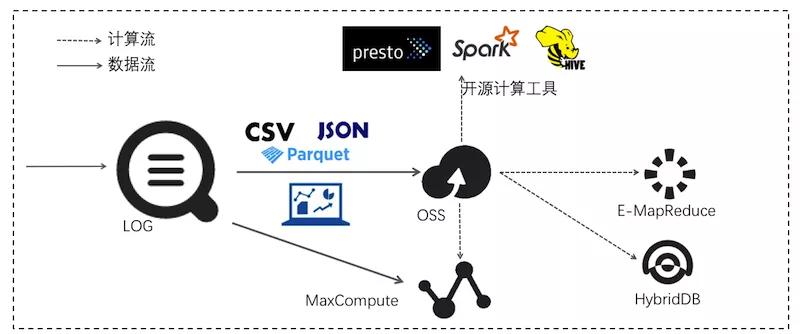
③消費投遞
穩定可靠的日志投遞。將日志中樞數據投遞至存儲類服務進行存儲。支持壓縮、自定義 Partition、以及行列等各種存儲方式。
用途:數據倉庫+數據分析、審計、推薦系統與用戶畫像。
④告警
日志服務的告警功能基于儀表盤中的查詢圖表實現。在日志服務控制臺查詢頁面或儀表盤頁面設置告警規則,并指定告警規則的配置、檢查條件和通知方式。
設置告警后,日志服務定期對儀表盤的查詢結果進行檢查,檢查結果滿足預設條件時發送告警通知,實現實時的服務狀態監控。
⑤最佳實踐
阿里云的日志服務功能相當強大,想用好日志服務可以參考:
https://help.aliyun.com/document_detail/29090.html?spm=a2c4g.11186623.6.1079.4edd3aabvs50OW
ELK 通用日志解決方案
ELK 是 Elasticsearch、Logstash、Kibana 三大開源框架首字母大寫簡稱。市面上也被成為 Elastic Stack。
其中 Elasticsearch 是一個基于 Lucene、分布式、通過 Restful 方式進行交互的近實時搜索平臺框架。
像類似百度、谷歌這種大數據全文搜索引擎的場景都可以使用 Elasticsearch 作為底層支持框架,可見 Elasticsearch 提供的搜索能力確實強大,市面上很多時候我們簡稱 Elasticsearch 為 ES。
Logstash 是 ELK 的中央數據流引擎,用于從不同目標(文件/數據存儲/MQ)收集的不同格式數據,經過過濾后支持輸出到不同目的地(文件/MQ/Redis/Elasticsearch/Kafka 等)。
Kibana 可以將 Elasticsearch 的數據通過友好的頁面展示出來,提供實時分析的功能。
實踐說明
普通格式日志:
- 2019-11-26 15:01:03.332|1543|INFO|[example-server-book-service,28f019d57b8336ab,630697c7f34ca4fa,105,45982043|XNIO-1 task-42]|c.p.f.w.pay.PayServiceImpl : order is paying with userId: 105 and orderId: 45982043
普通日志前綴是固定的,可以固定分詞索引,方便更快的查詢分析。
特定格式日志,以 access 日志為例:
- 2019-11-26 15:01:03.332|1543|INFO|[example-server-book-service,28f019d57b8336ab,630697c7f34ca4fa,105,45982043|XNIO-1 task-42]|c.p.f.w.logging.AccessLoggingFilter :
- > url: http://liweichao.com:10011/actuator/health
- > http-method: GET
- > request-header: [Accept:"text/plain, text/*, */*", Connection:"close", User-Agent:"Consul Health Check", Host:"liweichao.com:10011", Accept-Encoding:"gzip"]
- > request-time: 2019-11-26 15:01:03.309
- > querystring: -
- > payload: -
- > extra-param: -
- < response-time: 2019-11-26 15:01:03.332
- < take-time: 23
- < http-status: 200
- < response-header: [content-type:"application/vnd.spring-boot.actuator.v2+json;charset=UTF-8", content-size:"15"]
特定格式日志可按格式創建索引更方便聚焦查詢分析和告警,如根據 take-time,http-status,biz-code 等值。
參考文獻:
- Java日志記錄最佳實踐 :https://www.jianshu.com/p/546e9aace657)
- 別在 Java 代碼里亂打日志了,這才是打印日志的正確姿勢!:https://mp.weixin.qq.com/s/hJvkRlt9xQbWhYy1G7ZDsw
- 阿里云日志服務:https://help.aliyun.com/product/28958.html?spm=a2c4g.11186623.3.1.7cfd735dv8i1pB
- Spring Boot Logging:https://docs.spring.io/spring-boot/docs/2.2.1.RELEASE/reference/html/spring-boot-features.html#boot-features-logging
- Spring Cloud Sleuth:https://github.com/spring-cloud/spring-cloud-sleuth
- Opentracing:https://github.com/opentracing