圖像生成王者不是GAN?擴散模型最近有點火,效果直達SOTA
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
OpenAI剛剛推出的年末新作GLIDE,又讓擴散模型小火了一把。
這個基于擴散模型的文本圖像生成大模型參數(shù)規(guī)模更小,但生成的圖像質(zhì)量卻更高。
于是,依舊是OpenAI出品,論文標題就直接號稱“在圖像生成上打敗GAN”的ADM-G模型也重新進入了大眾眼中:

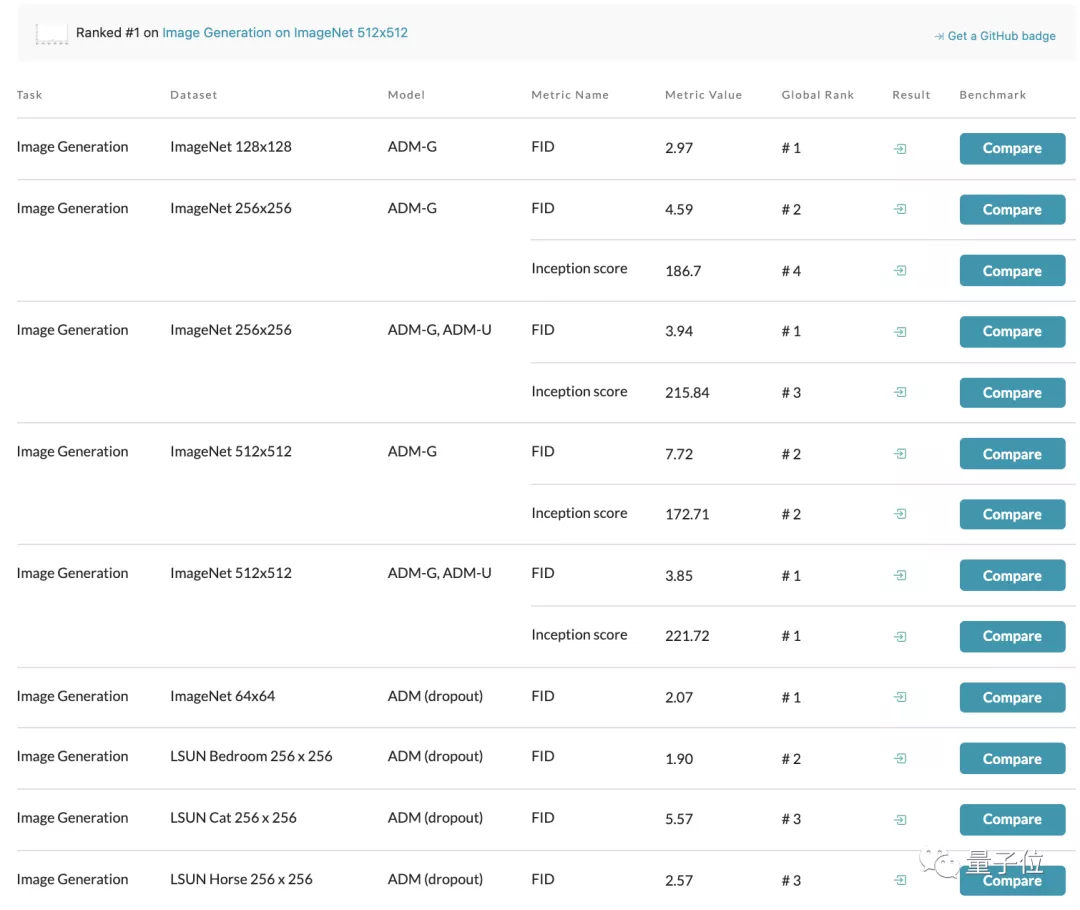
光看Papers with Code上基于ImageNet數(shù)據(jù)集的圖像生成模型榜單,從64 x 64到512 x 512分辨率都由這一模型占據(jù)榜首:
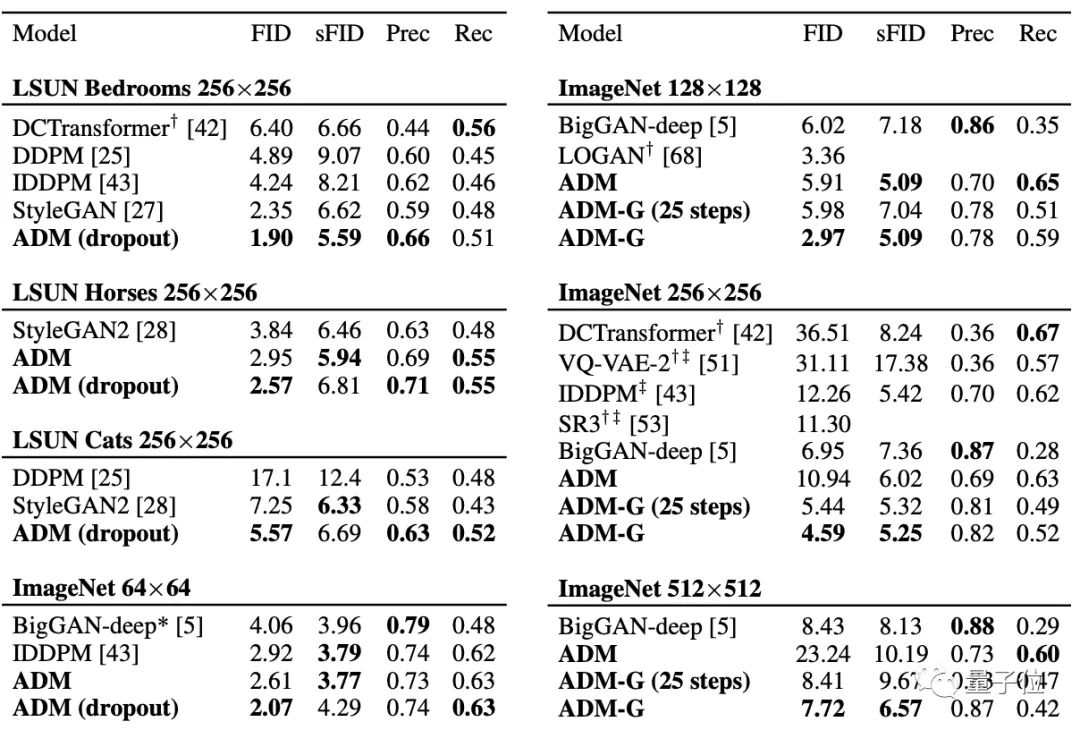
對比曾號稱史上最強圖像生成器的BigGAN-deep也不落下風(fēng),甚至還能在LSUN和ImageNet 64 × 64的圖像生成效果上達到SOTA。
有網(wǎng)友對此感嘆:前幾年圖像生成領(lǐng)域一直由GAN主導(dǎo),現(xiàn)在看來,似乎要變成擴散模型了。

加入類別條件的擴散模型
我們先來看看擴散模型的定義。
這是一種新的圖像生成的方法,其名字中的“擴散”本質(zhì)上是一個迭代過程。
具體到推理中,就是從一幅完全由噪聲構(gòu)成的圖像開始,通過預(yù)測每個步驟濾除的噪聲,迭代去噪得到一個高質(zhì)量的樣本,然后再逐步添加更多的細節(jié)。

而OpenAI的這個ADM-G模型,則是在此基礎(chǔ)上向圖像生成任務(wù)中加入了類別條件,形成了一種獨特的消融擴散模型。
研究人員分別從以下幾個方面做了改進:
基本架構(gòu)
基于UNet結(jié)構(gòu)做了五點改進:
- 在保持模型大小不變的前提下,增加深度與寬度
- 增加注意頭(Attention Head)數(shù)量
- 在32×32、16×16和8×8的分辨率下都使用注意力機制
- 使用BigGAN殘差塊對激活函數(shù)進行上采樣和下采樣
- 將殘差連接(Residual Connections)縮小為原來的1/根號2
類別引導(dǎo)(Classifier Guidance)
在噪聲逐步轉(zhuǎn)換到信號的過程中,研究人員引入了一個預(yù)先訓(xùn)練好的分類網(wǎng)絡(luò)。
它能夠為中間生成圖像預(yù)測并得到一個標簽,也就是可以對生成的圖片進行分類。
之后,再基于分類分數(shù)和目標類別之間的交叉熵損失計算梯度,用梯度引導(dǎo)下一步的生成采樣。
縮放分類梯度(Scaling Classifier Gradients)
按超參數(shù)縮放分類網(wǎng)絡(luò)梯度,以此來控制生成圖像的多樣性和精度。
比如像這樣,左邊是1.0規(guī)模大小的分類網(wǎng)絡(luò),右邊是10.0大小的分類網(wǎng)絡(luò),可以看到,右邊的生成圖像明顯類別更加一致:

也就是說,分類網(wǎng)絡(luò)梯度越高,類別就越一致,精度也越高,而同時多樣性也會變小。
生成領(lǐng)域的新熱點
目前,這一模型在GitHub上已有近千標星:

而與GAN比起來,擴散模型生成的圖像還更多樣、更復(fù)雜。
基于同樣的訓(xùn)練數(shù)據(jù)集時,擴散模型可以生成擁有全景、局部特寫、不同角度的圖像:

△左:BigGAN-deep 右:ADM
其實,自2020年谷歌發(fā)表DDPM后,擴散模型就逐漸成為了生成領(lǐng)域的一個新熱點,
除了文章中提到的OpenAI的兩篇論文之外,還有Semantic Guidence Diffusion、Classifier-Free Diffusion Guidence等多個基于擴散模型設(shè)計的生成模型。
擴散模型接下來還會在視覺任務(wù)上有哪些新的應(yīng)用呢,我們來年再看。
論文鏈接:
https://arxiv.org/abs/2105.05233
開源鏈接:
https://github.com/openai/guided-diffusion