華人博士提出模型SwinIR,33%的參數量就碾壓圖像修復領域sota
參數量和模型的性能有絕對關系嗎?蘇黎世華人博士提出SwinIR模型,實驗結果告訴你,越小的模型還可能更強!SwinIR使用Transformer力壓CNN,又在圖像修復領域屠榜,模型參數量降低67%,再也不要唯參數量論英雄了!
圖像修復(image restoration)是一個受到長期關注和研究的最基礎的CV問題,它能夠從低質量的圖像,例如縮略圖、有噪音的圖或是壓縮圖像中恢復為原始高質量圖像。
但目前圖像修復領域的sota方法都是基于卷積神經網絡CNN的,但是很少有人嘗試使用Transformer,盡管ViT在高級視覺任務中早已占據排行榜多年。
來自蘇黎世聯邦理工學院的華人博士提出一個適用于圖像修復的模型SwinIR,主要包括淺層特征提取、深層特征提取和高質量圖像重建三部分。
實驗結果證明SwinIR的性能比目前sota方法提高了0.14-0.45dB,并且參數量還降低了67%。

論文地址:https://arxiv.org/abs/2108.10257
項目地址:https://github.com/JingyunLiang/SwinIR
大多數基于CNN的方法側重于精細的架構設計,如residual learning和dense learning,通過巧妙的模型設計來提升性能,增大模型容量。
雖然與傳統的基于模型的方法相比CNN的性能有了顯著的提高,但通常會遇到兩個源于卷積層的基本問題:
1)圖像和卷積核之間的交互與內容無關。使用相同的卷積核來恢復不同的圖像區域可能不是最佳選擇;
2)由于CNN更關注局部特征,所以卷積對于長依賴性、全局的特征建模是效果不好。
在這種情況下,很容易想到Transformer來替代CNN。Transformer的自注意力機制能夠很好地捕獲上下文之間的全局交互,并在多個視覺任務上具有出了良好的表現。
然而,用于圖像修復的ViT需要將輸入圖像分割為具有固定大小(例如48×48)的patch,并對每個部分進行單獨處理。
這種策略不可避免地會產生兩個缺點:
1)邊界像素不能利用塊外的相鄰像素進行圖像恢復;
2)恢復的圖像可能會在每個圖像塊周圍引入邊界偽影。
雖然這個問題可以通過patch重疊來緩解,但它會帶來額外的計算負擔。
模型設計
SwinIR的設計基于Swin Transformer,包括三個部分:
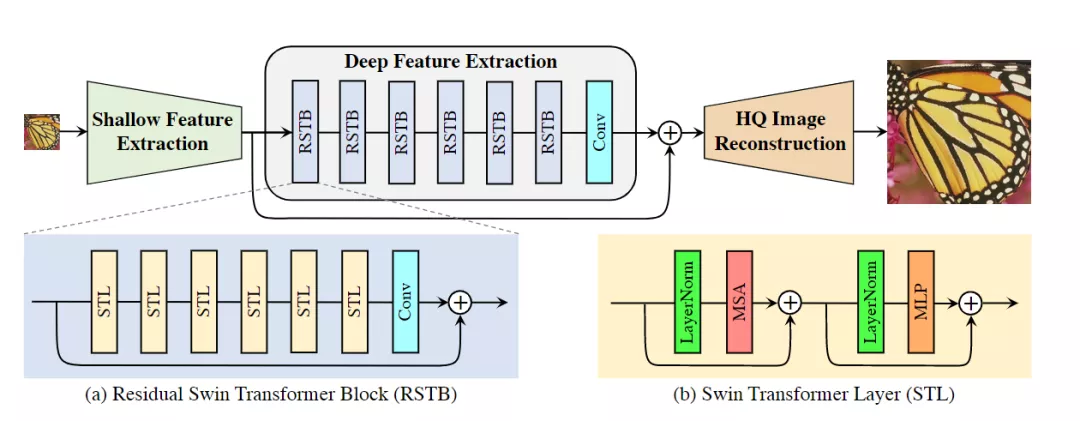
1)淺層特征抽取shallow feature extraction
淺層特征提取模塊采用卷積層提取淺層特征,并將淺層特征直接傳輸到重構模塊,以保留低頻信息。
2)深層特征抽取deep feature extraction
深層特征提取模塊主要由residual Swin Transformer Block(RSTB)組成組成,每個塊利用多個Swin Transformer layer(STL)進行局部注意力和交叉窗口的交互。此外,還在塊的末尾添加一個卷積層以增強特征,并使用殘差連接為特征聚合提供快捷方式,也就是說RSTB由多個STL和一個卷積層共同構成殘差塊,
3)高質量圖像重建high-quality(HQ) image reconstructi
重建模塊是最后一步,融合了淺層和深層特征用了恢復高質量的圖像。
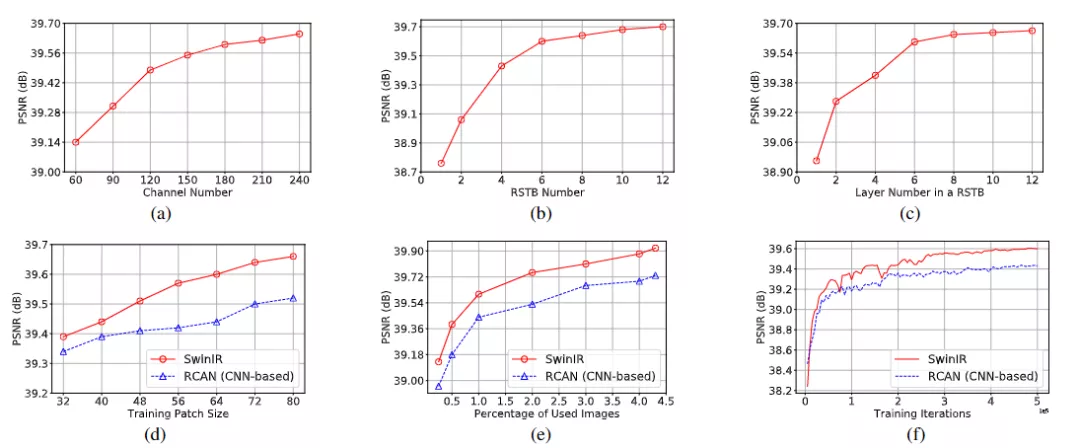
在實驗方面,作者首先研究了通道數,RSTB數目和STL數目對結果的影響。可以觀察到PSNR與這三個超參數正相關。對于信道數,雖然性能不斷提高,但參數量呈二次增長。為了平衡性能和模型尺寸,在剩下的實驗中選擇180作為通道數。對于RSTB數和層數,性能增益逐漸飽和,所以后續實驗設置為6以獲得一個相對較小的模型。
和經典的圖像超分辨率(super-resolution, SR)模型對,包括DBPN、RCAN、RRDB、SAN、IGNN、HAN、NLSA和IPT。可以看出,當在DIV2K數據上進行訓練時,SwinIR在幾乎所有五個基準數據集的所有比例因子上都取得了最佳性能,在Manga109在4倍縮放上的最大PSNR增益達到0.26dB。
不過需要注意的是,RCAN和HAN引入了通道和空間注意力,IGNN提出了自適應patch特征聚合,NLSA基于非局部注意機制。所有這些基于CNN的注意機制的表現都不如所提出的基于Transformer的SwinIR,這也表明了文中所提出模型的有效性。
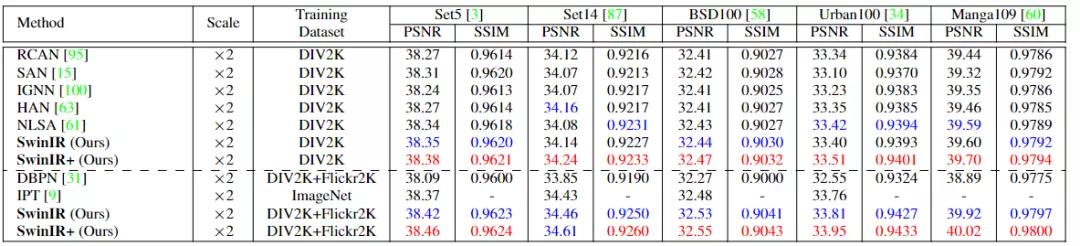
當在更大的數據集(DIV2K+Flickr2K)上訓練SwinIR時,性能進一步大幅度提高,也實現了比基于Transformer的模型IPT更好的精度,達到0.47dB。即使IPT在訓練中使用ImageNet(超過一百三十萬圖像),并且具有超過一億的參數。相比之下,即使與基于CNN的sota模型相比,SwinIR的參數也很少(1500萬-4430萬)。
在運行時方面,與基于CNN的代表性的模型RCAN相比,IPT和SwinIR在1024×1024分別需要約0.2、4.5和1.1秒。
實驗結果
從可視化結果來看,SwinIR可以恢復高頻細節并減輕模糊瑕疵,并產生銳利且自然的邊緣。
相比之下,大多數基于CNN的方法會產生模糊的圖像,甚至是不正確的紋理。與基于CNN的方法相比,IPT生成的圖像更好,但它存在圖像失真和邊界偽影。

在圖像降噪任務上,比較的方法包括傳統模型BM3D和WNNM,基于CNN的模型DnCNN,IR-CNN,FFDNet,N3Net,NLRN,FOC-Net,RNAN,MWCNN和DRUNet。可以看到SwinIR模型比所有方法都強。

特別是它在具有100個高分辨率測試圖像的大型Urban100數據集上通過最先進的DRUNet模型,最高可達0.3dB,并且SwinIR只有1200萬的參數,而DRUNet有三億參數,也就能側面證明SwinIR的架構在學習用于圖像恢復的特征表示方面是高效的。

SwinIR模型可以去除嚴重的噪聲干擾并保留高頻圖像細節,從而獲得更清晰的邊緣和更自然的紋理。相比之下,其他方法要么過于平滑,要么過于銳利,無法恢復豐富的紋理。