七個值得關注的優秀大語言模型(LLM)
在LLM領域我們了解最多的很可能是OpenAI的ChatGPT,以及最近在多模態表現非常出色的Google Gemini,這些都是AI大模型的領頭羊,代表著AI大模型發展的先進成果。然而,在大模型的實際應用中必須要綜合考慮成本、信息安全等內容,因此,開源成為了另一個選項。在開源生態中也涌現了許多優秀的LLM預練模型,這些模型有著各自的亮點,并且隨著AI技術的發展,未來將不止于此。
本文主要介紹目前為止(2024年1月)幾個值得關注的大開源LLM。

1.Llama 2:最佳開源LLM
資源:https://ai.meta.com/llama/


Llama 2是Meta于2023年推出的最重要的開源LLM。這是一個在2萬億令牌上訓練的預訓練生成AI模型,支持70億到700億個參數。Llama 2比Llama 1多了40%的訓練數據,并且支持的上下文長度多了兩倍。
目前,Llama 2仍然是市場上性能最高的開源語言模型之一,在推理、編碼、熟練度和知識測試等關鍵基準測試中表現出色。
目前 Hugging Face Open LLM 排行榜將Llama 2-70B列為市場上第二好的LLM,平均得分為67.35,ARC為67.32,HellaSwag為87.33,MMLU為69,83,TruthfulQA為44.92。
Llama 2還表現出了能夠媲美GPT 4等專有模型的良好性能。Anyscale的首席科學家兼谷歌前首席工程師Waleed Kadous發表了一篇博客文章,介紹Llama 2在總結方面的準確性與GPT-4大致相同,同時運行成本也低30倍。
值得注意的是,Meta還有一個名為Llama 2 Long的它是Llama 2的修改版本,額外增加了4000億個令牌,支持32000個上下文長度。
Meta聲稱Llama 2 Long的70B變體在長上下文任務(如:回答問題、摘要和多文檔聚合等)上的性能超過了GPT3.5-16ks。
2.Falcon 180B:最大的開源大語言預訓練模型
資源:https://huggingface.co/blog/falcon-180b

Falcon是阿拉伯聯合酋長國技術創新研究所2023年發布的最大的LLM——180B。它旨在出色地完成自然語言任務,截至2023年10月,Falcon是預訓練語言模型的Hugging Face Open LLM排行榜上排名第一的LLM,平均得分為68.74,ARC為69.8,HellaSwag為88.95,MMLU為70.54,TruthfulQA為45.67。
想要在聊天機器人環境中使用Falcon 180B,可以使用名為Falcon 180B Chat的版本,這是對聊天和指令數據進行微調的主模型的修改版本。
然而,Falcon 180B的一個關鍵限制是其基礎開源許可證非常嚴格。除了禁止用戶使用LLM違反當地或國際法律或傷害其他生物外,打算托管或提供基于LLM的管理服務的組織還需要單獨的許可證。
此外,與其他專有LLM或開源LLM(如Llama 2)相比,Falcon180B缺乏護欄,這意味著它可以更容易地用于惡意場景。
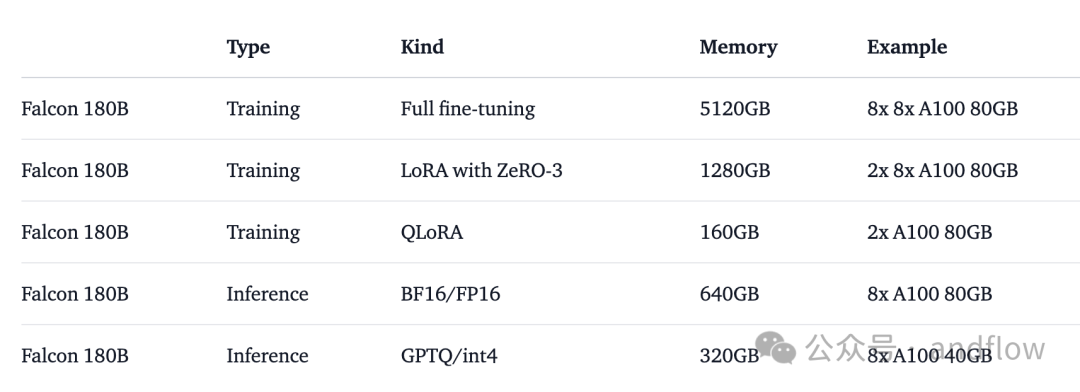
訓練和推理對硬件的要求如下:
3.Code Llama:最佳代碼生成LLM
資源:https://github.com/facebookresearch/codellama
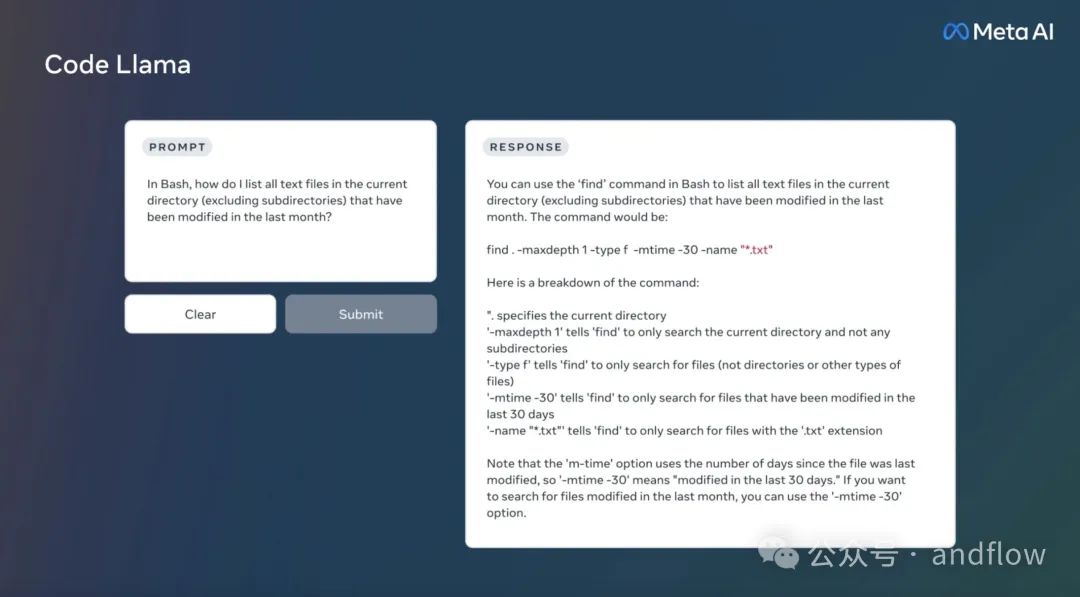
Meta的另一個佳作是Code Llama,這是一個基于Llama2,并在代碼數據集上訓練的模型,包括5000億個代碼和代碼相關數據的Token。
Code Llama支持7B、13B和34B參數,并在Python、C++,Java、PHP、Typescript(JavaScript)、C#、Bash等語言方面進行微調,以支持生成代碼并解釋代碼的作用等。
例如,用戶可以要求聊天機器人編寫一個輸出斐波那契序列的函數,或者請求有關如何列出給定目錄中所有文本文件的指令。
這使得它非常適合旨在簡化其工作流程的開發人員或希望更好地理解一段代碼的功能及其工作方式的新手。
Code Llama有兩個主要的變體:Code Llama Python和Code Llama Instruct。Code Llama - Python使用額外的100B Python代碼進行訓練,為用戶提供更好的Python編程語言代碼創建功能。
Code Llama Instruct是Code Llama的微調版本,它在50億個人類指令的令牌上進行了訓練,并已開發用于更好地理解人類指令。
4.Mistral:最佳7B預訓練模型
資源:https://github.com/mistralai/mistral-src
2023年9月,Mistral AI發布了Mistral 7B,這是一款小型但高性能的開源LLM,擁有70億個參數,其開發目的是比大型閉源模型能夠更有效地運行,使其成為實時應用的理想選擇。
Mistral 7B使用諸如分組查詢注意力之類的技術來進行更快的推理,并且使用滑動窗口注意力(SWA)來以更低的成本處理更長的序列。這些技術使LLM能夠比資源密集型的LLM更快地處理和生成大文本,并且成本更低。
該組織的發布公告顯示,Mistral 7B在arc-e上的得分為80.0%,在HellaSwag上的得分為81.3%,在MMLU上的得分為60.1%,在HumanEval基準測試中的得分為30.5%,在每個類別中都明顯優于LLama 2-7B。
Mistral AI還表示,Mistral在代碼、數學和推理方面優于并超越Llama 1-34B,同時在代碼任務上接近Code Llama 7B的性能。
另外,還有一個Mistral 7B的替代版本,稱為Mistral 7B Instruct,它已經在公開可用的會話數據集上進行了訓練,并且在MT-Bench基準測試中優于所有7B模型。
總之,這些信息表明Mistral AI是自然語言和代碼生成任務的可行選擇。
但是,一些人對Mistral 7B缺乏內容審核表示擔憂,這導致它可能生成有問題的內容,例如:如何制造炸彈的說明等。
5.Vicuna:最佳尺寸輸出質量LLM
資源:https://github.com/lm-sys/FastChat
Vicuna 13B 是由加州大學伯克利分校的學生和教職員工于2023年3月發布的一個開源聊天機器人。
LMSYS的研究人員基于Meta的Llama模型,采用ShareGPT.com上分享的7萬個ChatGPT對話數據對其進行了微調。在這些數據上訓練Llama使Vicuna能夠生成詳細和清晰的用戶響應,其復雜程度可與ChatGPT相媲美。
LMSYS機構的初步測試表明,Vicuna的質量達到了ChatGPT和Bard的90%,同時在90%的場景中優于Llama和斯坦福大學的Alpaca。
LMSYS還報告說,Vicuna 13B在MT-bench上獲得6.39分,在ELO評分為1,061分,在MMLU上獲得52.1分。另外,在AlpacaEval排行榜上,Vicuna 13B的獲勝率為82.11%,而GPT-3.5為81.71%,Llama 2 Chat 70B為92.66%。
令人印象深刻的是Vicuna 13B的訓練成本大約為300美元。
Vicuna還有一個更大的版本Vicuna-33B,MT-bench得分7.12,MMLU得分59.2。
6.Giraffe:最佳尺度上下文長度模型
資源:https://abacus.ai/

2023年9月,Abacus.AI發布了 Giraffe的70B版本,Giraffe是基于Llama 2進行微調的模型,將模型的上下文長度從4096擴展到32000。Abacus.AI為Giraffe提供了一個長上下文的窗口,以幫助提高下游任務處理性能。
擴展的上下文長度使LLM能夠從下游數據集檢索更多信息,同時減少錯誤,也有助于與用戶保持更長的對話。
Abacus.AI 聲稱Giraffe在提取、編碼和數學方面是所有開源模型中最好的性能。在MT-Bench評估基準下,70B版本獲得了7.01分。
Abacus AI首席執行官Bindu Reddy表示:“我們根據一組基準對70B模型進行了評估,調查了LLM在長“上下文”下的性能。”。“與13B模型相比,70B模型在文檔QA任務的最長上下文窗口(32k)下有顯著改進,在我們的AltQA數據集上,準確率為61%,而13B的準確率為18%。我們還發現,它在所有上下文長度上都優于可比的LongChat-32k模型,在最長上下文長度下性能也有所提高(在32k上下文長度下,準確率分別為61%和35%)。”
值得注意的是,Abacus AI還說,Giraffe 16k 在16k上下文長度的現實任務中能夠有良好的表現,甚至在20-24k上下文長度下依然可以表現良好。
7.ChatGLM:最佳開源中英雙語對話模型
資源:https://github.com/THUDM/ChatGLM3

ChatGLM是智譜AI和清華大學 KEG 實驗室聯合發布的新一代對話預訓練模型。2023年的10月27日發布了ChatGLM3系列,ChatGLM3-6B是ChatGLM3 系列中的開源模型,在保留了前兩代模型對話流暢、部署門檻低等眾多優秀特性的基礎上,增加了一些特性。
新特性如下:
- 更強大的基礎模型:ChatGLM3-6B 的基礎模型 ChatGLM3-6B-Base 采用了更多樣的訓練數據、更充分的訓練步數和更合理的訓練策略。在語義、數學、推理、代碼、知識等不同角度的數據集上測評顯示,ChatGLM3-6B-Base 具有在 10B 以下的基礎模型中最強的性能。
- 更完整的功能支持:ChatGLM3-6B 采用了全新設計的 Prompt 格式,除正常的多輪對話外。同時原生支持工具調用(Function Call)、代碼執行(Code Interpreter)和 Agent 任務等復雜場景。
- 更全面的開源序列: 除了對話模型 ChatGLM3-6B 外,還開源了基礎模型 ChatGLM3-6B-Base、長文本對話模型 ChatGLM3-6B-32K。以上所有權重對學術研究完全開放,在填寫問卷進行登記后允許免費商業使用。
模型列表如下:

ChatGLM3-6B-Base 具有在 10B 以下的基礎模型中的性能最強。其得分如下:
模型版本 | 評測任務 | 評測方向 | 得分 | 相比第二代提升 |
ChatGLM2-6B-Base | MMLU | 自然語言理解等 | 47.9 | - |
ChatGLM2-6B-Base | GSM8K | 數學能力 | 32.4 | - |
ChatGLM2-6B-Base | C-Eval | 中文能力 | 51.7 | - |
ChatGLM3-6B-Base | MMLU | 自然語言理解等 | 61.4 | 36% |
ChatGLM3-6B-Base | GSM8K | 數學能力 | 72.3 | 179% |
ChatGLM3-6B-Base | C-Eval | 中文能力 | 69 | 33.5% |
另外,chatglm3部署占用顯存13G左右,官方給出了模型量化版本,采用INT4精度占用不到5G。INT4精度模型仍然可以流暢生成文字,但5G的效果要比13G的差些。
最后
本文只是介紹了一部分在開源LLM,但隨著AI的發展,開源AI解決方案也在不斷增長。