作者 | 崔皓
審校 | 重樓
摘要
文章探討了如何確保不同用戶數(shù)據(jù)的隔離,并提供靈活的配置選項以適應(yīng)各種檢索需求。

文章首先介紹了多用戶數(shù)據(jù)檢索的背景和挑戰(zhàn),包括數(shù)據(jù)權(quán)限管理、檢索系統(tǒng)靈活性和用戶體驗問題。接著進(jìn)行了技術(shù)分析,特別強(qiáng)調(diào)了使用Pinecone作為向量數(shù)據(jù)庫來處理高維向量數(shù)據(jù)的優(yōu)勢。文中詳細(xì)討論了數(shù)據(jù)存儲和檢索的關(guān)鍵步驟,如多用戶支持的檢索器確認(rèn)、鏈條配置字段的添加和運(yùn)用可配置字段來調(diào)用鏈條。最后,通過實際代碼演示了如何在LangChain中實現(xiàn)多用戶檢索,包括環(huán)境設(shè)置、文本嵌入、配置索引器與Chain的構(gòu)建,以及通過特定命名空間對文檔庫進(jìn)行隔離的測試結(jié)果。
背景
多用戶環(huán)境下的數(shù)據(jù)檢索,要求系統(tǒng)能夠區(qū)分并管理不同用戶的數(shù)據(jù)。這不僅涉及到數(shù)據(jù)安全性和隱私保護(hù),還要求檢索系統(tǒng)能夠靈活應(yīng)對不同用戶的數(shù)據(jù)檢索需求。假設(shè)有一家大型企業(yè),擁有龐大的知識庫系統(tǒng),該系統(tǒng)存儲了從市場分析到技術(shù)文檔的各類信息。企業(yè)內(nèi)部有多個部門,如研發(fā)、市場、人力資源等,每個部門對知識庫的數(shù)據(jù)訪問需求不同。為了保證信息安全,企業(yè)需要實現(xiàn)對數(shù)據(jù)的權(quán)限控制,確保每個部門只能訪問對應(yīng)的相關(guān)數(shù)據(jù)。
在這個業(yè)務(wù)場景中,最大的挑戰(zhàn)是如何在保證數(shù)據(jù)安全的同時,還能滿足不同用戶的數(shù)據(jù)檢索需求。具體問題包括:
數(shù)據(jù)權(quán)限管理:如何確保每個用戶只能訪問授權(quán)的數(shù)據(jù)?
檢索系統(tǒng)的靈活性:如何設(shè)計一個既能保護(hù)數(shù)據(jù)安全,又能靈活響應(yīng)不同用戶檢索需求的系統(tǒng)?
用戶體驗:如何在不泄露其他部門數(shù)據(jù)的前提下,提供快速準(zhǔn)確的檢索結(jié)果?
技術(shù)分析
LangChain是大模型應(yīng)用框架,特別擅長處理檢索任務(wù),即從大量數(shù)據(jù)中找到與給定查詢最相關(guān)的信息。在這篇文章中,我們將重點介紹如何在LangChain框架中實現(xiàn)多用戶檢索。那么,為了實現(xiàn)多用戶檢索不同數(shù)據(jù),就需要解決數(shù)據(jù)存儲和數(shù)據(jù)檢索兩個問題。
數(shù)據(jù)存儲方面
在AI應(yīng)用中,如推薦系統(tǒng)或語義搜索,需要處理和檢索大量的高維向量數(shù)據(jù)。因此在處理大規(guī)模向量數(shù)據(jù)時會面臨如下問題:
- 實時數(shù)據(jù)更新和查詢延遲問題:AI應(yīng)用需要快速反映數(shù)據(jù)的最新變更(如實時更新用戶偏好)。許多系統(tǒng)難以在保證準(zhǔn)確性的同時實現(xiàn)低延遲的數(shù)據(jù)更新和查詢。
- 復(fù)雜的基礎(chǔ)設(shè)施管理和成本:構(gòu)建和維護(hù)用于存儲和檢索向量數(shù)據(jù)的基礎(chǔ)設(shè)施通常復(fù)雜且成本高昂,尤其是在云環(huán)境下。
- 高維數(shù)據(jù)的存儲和索引優(yōu)化問題:存儲密集或稀疏的向量嵌入,需要優(yōu)化的存儲結(jié)構(gòu)和索引策略,以保持高效檢索和存儲性能。
- 多語言和多平臺接入難題:AI應(yīng)用開發(fā)者可能需要在不同的編程環(huán)境(如Python,Node.js)中處理向量數(shù)據(jù),需要一個跨平臺、易于使用的API。
為了解決上述問題,本例我們選用Pinecone。Pinecone是一個為AI應(yīng)用設(shè)計的云原生向量數(shù)據(jù)庫,提供簡易API和自管理的基礎(chǔ)設(shè)施。它專門處理高維向量數(shù)據(jù),能夠以低延遲處理數(shù)十億向量的檢索請求。向量嵌入作為其核心,代表語義信息,賦予AI應(yīng)用長期記憶功能,使其能在執(zhí)行復(fù)雜任務(wù)時利用以往經(jīng)驗。
與傳統(tǒng)標(biāo)量數(shù)據(jù)庫相比,Pinecone提供了針對向量數(shù)據(jù)的優(yōu)化存儲和查詢,解決了處理復(fù)雜向量數(shù)據(jù)的難題。它的索引包含獨特ID和密集向量嵌入的浮點數(shù)數(shù)組,也支持稀疏向量嵌入和元數(shù)據(jù)鍵值對,用于混合搜索和過濾查詢。Pinecone保證高性能、實時性,每個pod副本每秒可處理200個查詢,反映最新數(shù)據(jù)更新。用戶可通過HTTP、Python或Node.js進(jìn)行增刪改查操作,靈活處理向量數(shù)據(jù)。
數(shù)據(jù)檢索方面
為了實現(xiàn)多用戶檢索需要執(zhí)行如下關(guān)鍵步驟:
1. 多用戶支持的檢索器確認(rèn):檢查使用的檢索器是否支持多用戶功能。目前LangChain沒有統(tǒng)一的標(biāo)識或過濾器來實現(xiàn)這一點,每個向量存儲和檢索器可能有自己的實現(xiàn)方式(如命名空間、多租戶等)。通常,這通過在`similarity_search`時傳遞的關(guān)鍵字參數(shù)來暴露。因此,需要通過閱讀文檔或源代碼來確定所用檢索器是否支持多用戶功能,以及如何使用它。
2. 為鏈條添加配置字段:在運(yùn)行時調(diào)用鏈條并配置任何相關(guān)標(biāo)志。查閱相關(guān)文檔了解更多關(guān)于配置的信息。需要說明的是, “鏈條”(Chains)是LangChain的一個關(guān)鍵概念,它們是一系列處理步驟的集合,用于執(zhí)行特定的任務(wù)。為了支持多用戶檢索,用戶需要在鏈條中添加配置字段。這些字段允許在運(yùn)行時動態(tài)調(diào)整鏈條的行為,以適應(yīng)不同用戶的需求。
3. 使用可配置字段調(diào)用鏈條:運(yùn)行時,通過前面設(shè)置的可配置字段,可以實現(xiàn)對鏈條的個性化調(diào)用。這意味著用戶可以根據(jù)不同的情境或用戶需求,調(diào)整鏈條的行為。這一步是實現(xiàn)多用戶檢索的關(guān)鍵,它確保了檢索結(jié)果能夠根據(jù)不同用戶的獨特需求進(jìn)行優(yōu)化和調(diào)整。
上面三點需要索引支持多用戶查詢,用戶查詢數(shù)據(jù)的參數(shù)可以通過配置字段的方式傳遞給Chains,同時Chains 可以接受配置字段并且執(zhí)行,完成數(shù)據(jù)檢索的操作。
根據(jù)前面對Pinecone向量存儲的描述,我們通過查閱LangChain 官方文檔了解。
既然數(shù)據(jù)存儲和數(shù)據(jù)檢索的問題都得到了解決,下面就開始代碼實踐的環(huán)節(jié)。包langchain_community.vectorstores.pinecone.Pinecone 下面包含了as_retriever方法,該方法創(chuàng)建并返回一個VectorStoreRetriever對象,該對象從VectorStore初始化。這個檢索器提供了多種搜索類型,使得用戶可以根據(jù)不同需求進(jìn)行定制化的向量數(shù)據(jù)檢索。
該方法的關(guān)鍵參數(shù)如下:
search_type(可選字符串)
定義:指定檢索器執(zhí)行的搜索類型。
選項:
"similarity":標(biāo)準(zhǔn)的相似度搜索,默認(rèn)選項。
"mmr":最大邊緣相關(guān)性(Maximum Marginal Relevance),用于生成多樣化的搜索結(jié)果。
"similarity_score_threshold":設(shè)置相似度分?jǐn)?shù)閾值,僅返回超過此閾值的文檔。
search_kwargs(可選字典)
功能:提供給搜索函數(shù)的關(guān)鍵字參數(shù)。
包含內(nèi)容:
k:返回的文檔數(shù)量,默認(rèn)為4。
score_threshold:用于similarity_score_threshold的最小相關(guān)性閾值。
fetch_k:傳遞給MMR算法的文檔數(shù)量,默認(rèn)為20。
lambda_mult:MMR結(jié)果的多樣性程度,從1(最小多樣性)到0(最大多樣性),默認(rèn)為0.5。
filter:基于文檔元數(shù)據(jù)的過濾條件。
返回值
類型:VectorStoreRetriever
功能:一個檢索類,用于在VectorStore上執(zhí)行數(shù)據(jù)檢索操作。代碼實踐
技術(shù)分析之后就需要分幾個步驟進(jìn)行代碼實踐,具體步驟如下:
Pinecone信息獲取
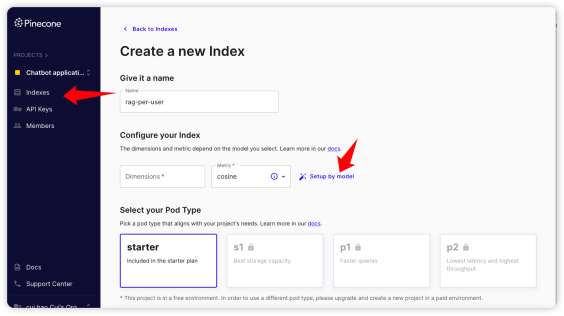
首先需要注冊Pinecone的賬號,然后獲取對應(yīng)API Keys,在調(diào)用Pinecone服務(wù)的時候會用到它。注冊Pinecone的過程比較簡單,填寫基本信息就可以完成,這里不再贅述。如下圖所示,在用戶控制臺的“API Keys” 菜單中選擇key對應(yīng)的“復(fù)制”圖標(biāo),從而復(fù)制“API Keys”留作備用。

接著到“Indexes”頁面去創(chuàng)建index,如下圖所示,選擇“Setup by model”。
在彈出的對話框中,我們選擇OpenAI 的embedding 作為index 的配置項。

最終,如下圖所示,點擊“Create indexes” 按鈕創(chuàng)建index。

創(chuàng)建index 完成之后,可以通過下圖看到對應(yīng)的信息,其中“rag-per-user”是index的名字,gcp-starter作為環(huán)境的名字。這兩個信息在初始化Pinecone的時候是需要的。

環(huán)境安裝與參數(shù)配置
需要將代碼需要的組件包安裝好,通過如下命令實現(xiàn)安裝:
!pip install openai langchain pinecone-client pypdf tiktoken -q -UOpenai:這是OpenAI提供的官方Python庫,用于與OpenAI的API(如GPT和DALL-E等)進(jìn)行交互。
Langchain:這個庫可能是用于處理語言相關(guān)任務(wù)的。它可能包含了一些用于自然語言處理、機(jī)器翻譯或其他語言技術(shù)的工具和模型。
pinecone-client:Pinecone是一個向量數(shù)據(jù)庫,用于構(gòu)建和部署大規(guī)模相似性搜索應(yīng)用。pinecone-client 是其客戶端庫,用于與Pinecone服務(wù)進(jìn)行交互。
Pypdf:這是一個Python庫,用于處理PDF文件。它可能允許用戶讀取、寫入、分割、合并和轉(zhuǎn)換PDF文檔。
Tiktoken:用來對文本進(jìn)行分詞。
接著再對一些參數(shù)進(jìn)行賦值如下:
import os
import getpass
os.environ["PINECONE_API_KEY"] = getpass.getpass("輸入Pinecone key")
os.environ["OPENAI_API_KEY"] = getpass.getpass("輸入OpenAI Key")
PINECONE_API_KEY=os.environ.get("PINECONE_API_KEY")
PINECONE_ENVIRONMENT="gcp-starter"
PINECONE_INDEX="rag-per-user"(1) 導(dǎo)入模塊
import os: 導(dǎo)入 Python 的 os 模塊,它提供了許多與操作系統(tǒng)交互的功能,包括管理環(huán)境變量。
import getpass:導(dǎo)入 getpass 模塊,它用于安全地獲取用戶輸入,而不在屏幕上顯示輸入(如密碼或密鑰)。
(2) 獲取并設(shè)置環(huán)境變量
os.environ["PINECONE_API_KEY"] = getpass.getpass("輸入Pinecone key"): 這行代碼首先顯示提示“輸入Pinecone key”,然后等待用戶輸入 Pinecone 的 API 密鑰。輸入的內(nèi)容不會在屏幕上顯示。輸入完成后,該密鑰被設(shè)置為環(huán)境變量 PINECONE_API_KEY。
os.environ["OPENAI_API_KEY"] = getpass.getpass("輸入OpenAI Key"): 同樣,這行代碼用于獲取并設(shè)置 OpenAI 的 API 密鑰作為環(huán)境變量 OPENAI_API_KEY。
(3) 讀取環(huán)境變量
PINECONE_API_KEY = os.environ.get("PINECONE_API_KEY"):從環(huán)境變量中讀取 PINECONE_API_KEY 的值,并將其賦給變量 PINECONE_API_KEY。如果該環(huán)境變量不存在,它將返回 None。
(4) 設(shè)置其他Pinecone相關(guān)的變量
PINECONE_ENVIRONMENT="gcp-starter":設(shè)置了一個字符串變量 PINECONE_ENVIRONMENT,其值為 "gcp-starter"。這通常用于指定 Pinecone 服務(wù)的運(yùn)行環(huán)境。
PINECONE_INDEX="rag-per-user": 設(shè)置 PINECONE_INDEX 變量為 "rag-per-user",這個值通常用于指定在 Pinecone 中使用的特定索引。
整體上,這段代碼的目的是安全地獲取和存儲與 Pinecone 和 OpenAI 服務(wù)相關(guān)的敏感信息(如 API 密鑰),同時還設(shè)定了一些與 Pinecone 服務(wù)相關(guān)的配置變量。這樣做可以在代碼的其他部分安全地使用這些密鑰和配置,而不必硬編碼在代碼中,從而增強(qiáng)了安全性和靈活性。
文本嵌入
接下來,使用 Pinecone 作為向量存儲(Vector Store)和 OpenAI 作為嵌入生成器,用于搭建一個語言處理系統(tǒng)。
import pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain_community.chat_models import ChatOpenAI
from langchain.vectorstores import Pinecone
pinecone.init(api_key=PINECONE_API_KEY, environment=PINECONE_ENVIRONMENT)
index = pinecone.Index(PINECONE_INDEX)
embeddings = OpenAIEmbeddings()
vectorstore = Pinecone(index, embeddings, "text")
vectorstore.add_texts(["我的工作職責(zé)是為用戶提供產(chǎn)品方面的介紹。"], namespace="product-service")
vectorstore.add_texts(["我的工作職責(zé)是為用戶提供技術(shù)方面的支持。"], namespace="tech-service")
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
ConfigurableField,
RunnableBinding,
RunnableLambda,
RunnablePassthrough,
)
template = """基于如下信息回答問題:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
retriever = vectorstore.as_retriever()代碼解釋如下:
(1) 導(dǎo)入所需模塊和類
import pinecone: 導(dǎo)入 pinecone 模塊,用于與 Pinecone 服務(wù)交互。
from langchain.embeddings.openai import OpenAIEmbeddings: 從 langchain 庫中導(dǎo)入 OpenAIEmbeddings 類,用于生成文本嵌入(embeddings)。
from langchain_community.chat_models import ChatOpenAI: 導(dǎo)入 ChatOpenAI,這可能是用于處理聊天或問答類型任務(wù)的模型。
from langchain.vectorstores import Pinecone: 導(dǎo)入 Pinecone 類,用于在 Pinecone 服務(wù)上操作向量存儲。
(2) 初始化 Pinecone 服務(wù)并創(chuàng)建索引
pinecone.init(api_key=PINECONE_API_KEY, envirnotallow=PINECONE_ENVIRONMENT): 使用提供的 API 密鑰和環(huán)境變量初始化 Pinecone 服務(wù)。
index = pinecone.Index(PINECONE_INDEX): 創(chuàng)建或訪問一個名為 PINECONE_INDEX 的 Pinecone 索引。
(3) 設(shè)置嵌入生成器和向量存儲
embeddings = OpenAIEmbeddings(): 實例化 OpenAIEmbeddings 以生成文本嵌入。
vectorstore = Pinecone(index, embeddings, "text"): 創(chuàng)建一個 Pinecone 實例,用于存儲和檢索文本嵌入。這里使用了之前創(chuàng)建的 index 和 embeddings。
(4) 向量存儲中添加文本
vectorstore.add_texts(["我的工作職責(zé)是為用戶提供產(chǎn)品方面的介紹。"], namespace="product-service"): 將一段文本添加到向量存儲中,用于表示“產(chǎn)品服務(wù)”相關(guān)的信息。
vectorstore.add_texts(["我的工作職責(zé)是為用戶提供技術(shù)方面的支持。"], namespace="tech-service"): 將另一段文本添加到向量存儲中,用于表示“技術(shù)服務(wù)”相關(guān)的信息。
(5) 設(shè)置輸出解析器、提示模板和模型
導(dǎo)入了多個 langchain_core 中的類和函數(shù),這些可能用于處理和解析語言模型的輸出。
template = "..." 和 prompt = ChatPromptTemplate.from_template(template): 定義一個聊天提示模板,用于指導(dǎo)語言模型如何回答問題。
model = ChatOpenAI(): 實例化一個 ChatOpenAI 模型,可能用于處理聊天或問答任務(wù)。
retriever = vectorstore.as_retriever(): 將 vectorstore 轉(zhuǎn)換為一個檢索器(Retriever),用于從存儲的嵌入中檢索相關(guān)信息。
這段代碼設(shè)置了一個基于 Pinecone 和 OpenAI 的語言處理系統(tǒng),它能夠存儲和檢索文本信息,并且使用特定的模型和模板處理聊天或問答類型的任務(wù)。
配置索引器與Chain
緊跟著,需要建立一個處理鏈(chain),使用配置的檢索器(configurable_retriever),提示模板(Prompt),模型(Model),和輸出解析器(StrOutputParser)。這個Chain 就是用來執(zhí)行按照namespace 進(jìn)行索引的。代碼如下:
(1) 配置檢索器
configurable_retriever = retriever.configurable_fields(...): 這行代碼創(chuàng)建了一個可配置的檢索器 configurable_retriever。它通過 ConfigurableField 定義一個可配置的字段 search_kwargs,該字段用于定義檢索器的搜索參數(shù)(例如,如何從向量存儲中檢索數(shù)據(jù))。
(2) 構(gòu)建處理鏈
處理鏈由幾個部分組成,通過 | 符號連接,表示數(shù)據(jù)將按順序通過這些組件。
{"context": configurable_retriever, "question": RunnablePassthrough()}: 這是鏈的第一部分,包含兩個輸入:context 和 question。context 通過 configurable_retriever 獲取,而 question 直接通過 RunnablePassthrough 傳遞,后者意味著問題(question)不進(jìn)行任何處理就傳遞到鏈的下一個部分。
- prompt: 然后,輸入數(shù)據(jù)傳遞到 prompt。這個ChatPromptTemplate 對象負(fù)責(zé)根據(jù)上下文和問題格式化提示,準(zhǔn)備好交給語言模型處理。
- model: 接下來,格式化好的提示傳遞給 model,這里的 model 是 ChatOpenAI 實例,它會根據(jù)提供的提示生成回答。
- StrOutputParser(): 最后,模型的輸出傳遞給StrOutputParser,這個解析器將模型的輸出轉(zhuǎn)換成字符串形式。
整體來看,這個處理鏈的作用是:根據(jù)檢索到的上下文和未處理的問題生成一個格式化的提示,然后使用 ChatOpenAI 模型來生成回答,并將這個回答轉(zhuǎn)換為字符串。這種方式非常適合于問答系統(tǒng),其中上下文信息是根據(jù)需要動態(tài)檢索的,而問題直接傳遞給模型以生成答案。
測試結(jié)果
創(chuàng)建好Chain之后,我們來嘗試對其提出問題,由于我們之前定義了不同namespace對應(yīng)的工作職責(zé)。這里我們就直接詢問工作職責(zé)的問題,首先測試product-service 這個namespace,看看它返回什么答案。
chain.invoke(
"你的工作職責(zé)是什么?",
config={"configurable": {"search_kwargs": {"namespace": "product-service"}}},
)結(jié)果如下:
我的工作職責(zé)是為用戶提供產(chǎn)品方面的介紹。結(jié)果和我們預(yù)期一致,product-service 這個namespace 確實是用來處理產(chǎn)品方面的問題的。
接著再測試tech-service 這個namespace的回答。
chain.invoke(
"你的工作職責(zé)是什么?",
config={"configurable": {"search_kwargs": {"namespace": "tech-service"}}},
)結(jié)果如下:
我的工作職責(zé)是為用戶提供技術(shù)方面的支持。看來返回結(jié)果也是正確的。
文檔庫隔離
上面通過在不同的namespace 中加入不同的text文本信息,讓不同用戶通過訪問不同的namespace 來做到“知識”內(nèi)容的隔離。但是,真實的應(yīng)用場景是針對不同的namespace上傳不同的文檔,當(dāng)我們提問的時候需要制定namespace,來確定由哪個文檔來回應(yīng)消息。
于是,我們針對product-service 和tech-service 兩個不同的namespace 上傳兩個不同的文檔,分別是product-service.pdf 和 tech-service.pdf。兩個文檔的內(nèi)容如下:
product-service.pdf 是一個產(chǎn)品服務(wù)知識庫,采用問答形式。它提供了關(guān)于客戶服務(wù)的具體指導(dǎo),特別是關(guān)于退貨政策的細(xì)節(jié)。
產(chǎn)品服務(wù)知識庫(問答形式)
問:如果客戶詢問關(guān)于退貨政策的具體細(xì)節(jié),我們應(yīng)該如何回答?
答:?先,禮貌地感謝客戶對產(chǎn)品的購買。然后, 詳細(xì)解釋我們的退貨政策:客戶可以在購買后的30 天內(nèi)?條件退貨,產(chǎn)品必須保持原始狀態(tài)且包裝完整。提醒客戶保留收據(jù),因為這是退貨的必要憑證。 最后,告知客戶退貨流程,并提供相關(guān)表格和聯(lián)系信息。tech-service.pdf 是一個技術(shù)服務(wù)知識庫,同樣采用問答形式。它主要提供了關(guān)于技術(shù)問題解決方案的指導(dǎo),特別是針對智能鎖失靈的問題。
技術(shù)服務(wù)知識庫(問答形式)
問:客戶如何解決智能鎖頻繁失靈的問題?
答:?先,指導(dǎo)客戶檢查智能鎖的電源和電池狀態(tài),確認(rèn)電量是否充?。如果電量正常,請引導(dǎo)客戶重置智能鎖,具體?法是?按重置鍵 5 秒鐘。如果問題仍然存在,請建議客戶檢查智能鎖的軟件版本是否最新,并引導(dǎo)進(jìn)?系統(tǒng)更新。若以上步驟?法解決問題,建議客戶聯(lián)系技術(shù)?持以獲取進(jìn)?步的幫助。有了文檔之后,我們就需要將其上傳并且嵌入到向量庫Pinecone中, 代碼如下:
from langchain.document_loaders import PyPDFLoader
from google.colab import drive
drive.mount('/content/drive')
file_path = '/content/drive/My Drive/files/product-service.pdf'
loader = PyPDFLoader(file_path)
documents = loader.load_and_split()
vectorstore.add_documents(documents, namespace="product-service")
file_path = '/content/drive/My Drive/files/tech-service.pdf'
loader = PyPDFLoader(file_path)
documents = loader.load_and_split()
vectorstore.add_documents(documents, namespace="tech-service")由于我使用的是colab 環(huán)境,所以這段代碼是關(guān)于如何在 Google Colab 環(huán)境中加載 PDF 文件并將它們的內(nèi)容添加到一個向量存儲(vector store)中。下面是對代碼的詳細(xì)解釋:
(1) **導(dǎo)入所需模塊和類**
- `from langchain.document_loaders import PyPDFLoader`: 導(dǎo)入 `PyPDFLoader` 類,這個類用于加載 PDF 文件并將其內(nèi)容轉(zhuǎn)換為可處理的文檔格式。
- `from google.colab import drive`: 導(dǎo)入用于在 Google Colab 環(huán)境中掛載 Google Drive 的模塊。
(2) **掛載 Google Drive**
- `drive.mount('/content/drive')`: 這行代碼將 Google Drive 掛載到 Colab 的文件系統(tǒng)中。這使得在 Colab 中可以直接訪問存儲在 Google Drive 中的文件。
(3) **加載并處理第一個 PDF 文件**
- `file_path = '/content/drive/My Drive/files/product-service.pdf'`: 設(shè)置第一個 PDF 文件的路徑。
- `loader = PyPDFLoader(file_path)`: 創(chuàng)建 `PyPDFLoader` 實例并傳入文件路徑,準(zhǔn)備加載文件。
- `documents = loader.load_and_split()`: 使用 `load_and_split` 方法加載 PDF 文件并將其內(nèi)容分割成單獨的文檔。這些文檔通常是 PDF 的每一頁或者每個段落。
(4) **將文檔添加到向量存儲**
- `vectorstore.add_documents(documents, namespace="product-service")`: 將從 PDF 文件中加載的文檔添加到向量存儲中,指定命名空間為 "product-service"。
(5) **重復(fù)以上步驟加載第二個 PDF 文件**
- 設(shè)置第二個 PDF 文件 `tech-service.pdf` 的路徑。
- 再次創(chuàng)建 `PyPDFLoader` 實例,加載第二個文件。
- 將從第二個文件中加載的文檔添加到向量存儲中,這次指定命名空間為 "tech-service"。
整體來看,這段代碼的目的是將兩個 PDF 文件(分別關(guān)于產(chǎn)品服務(wù)和技術(shù)服務(wù)的知識庫)的內(nèi)容加載到一個向量存儲系統(tǒng)中,可能用于后續(xù)的搜索或檢索任務(wù)。通過將文件內(nèi)容分割成單獨的文檔,并使用命名空間區(qū)分不同的文件內(nèi)容,代碼有效地組織了信息,便于后續(xù)處理。
既然PDF文檔已經(jīng)嵌入了,接下來就是重頭戲了。我們定義了一個名為ask_question 的函數(shù),它使用一系列處理步驟(即一個處理鏈)來根據(jù)給定的問題和命名空間從一個向量存儲中檢索并回答問題。代碼如下:
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
def ask_question(question, namespace):
retriever = vectorstore.as_retriever()
template = """基于如下的上下文內(nèi)容進(jìn)行回答[CONTEXT][/CONTEXT]:
[CONTEXT]{context}[/CONTEXT]
如果你不知道答案,你就回答:我不知道。
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
configurable_retriever = retriever.configurable_fields(
search_kwargs=ConfigurableField(
id="search_kwargs",
name="Search Kwargs",
description="The search kwargs to use",
)
)
chain = (
{"context": configurable_retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
response = chain.invoke(
question,
config={"configurable": {"search_kwargs": {"namespace": namespace}}},
)
print(response)代碼解釋如下:
(1) 導(dǎo)入所需模塊和類
導(dǎo)入 ChatPromptTemplate,StrOutputParser,RunnablePassthrough 等類,這些類用于處理和解析語言模型的輸出。
(2) 定義 ask_question 函數(shù)
def ask_question(question, namespace): 定義一個函數(shù),接受兩個參數(shù):question(要問的問題)和 namespace(用于指定搜索的命名空間,可能代表不同類型的知識庫)。
(3) 設(shè)置檢索器和提示模板
retriever = vectorstore.as_retriever(): 獲取向量存儲的檢索器。
template = """...""": 定義一個聊天提示模板,該模板指定如何格式化問題和上下文。需要特別注意的是,這里設(shè)計的prompt template 為“如果你不知道答案,你就回答:我不知道。”這是在告訴大模型,如果不能從知識庫中獲取答案,就如實回答“不知道”,不要試圖去編造答案。
prompt = ChatPromptTemplate.from_template(template): 使用上述模板創(chuàng)建一個 ChatPromptTemplate 實例。
(4) 配置檢索器
configurable_retriever = retriever.configurable_fields(...): 創(chuàng)建一個可配置的檢索器,它允許調(diào)整搜索參數(shù)(如命名空間)。
(5) 構(gòu)建處理鏈
chain = (...): 創(chuàng)建一個處理鏈,它包括以下部分:
將 configurable_retriever 和 RunnablePassthrough 作為輸入,前者用于獲取上下文,后者直接傳遞問題。
使用 prompt 來格式化輸入。
model(這里是 ChatOpenAI 實例)用于生成回答。
StrOutputParser 將模型的輸出轉(zhuǎn)換為字符串。
(6) 調(diào)用處理鏈并打印響應(yīng)
response = chain.invoke(...): 使用 invoke 方法調(diào)用處理鏈,并傳入問題和配置(包括指定的命名空間)。
print(response): 打印出生成的響應(yīng)。
該函數(shù)利用一個配置好的處理鏈來自動回答問題。它從指定命名空間的向量存儲中檢索相關(guān)上下文,然后使用這些上下文和提供的問題生成一個合適的回答。這對于基于特定知識庫自動回答用戶問題的場景非常有用。
最后,我們來看運(yùn)行結(jié)果。
執(zhí)行如下語句:
ask_question("退貨政策", "product-service")傳入提出的問題,以及對應(yīng)的namespace。由于之前PDF文件中就對退貨政策進(jìn)行了描述,現(xiàn)在就通過product-service 這個namespace 搜索與之相關(guān)的內(nèi)容。得到如下結(jié)果:
答:客戶可以在購買后的30天內(nèi)無條件退貨,產(chǎn)品必須保持原始狀態(tài)且包裝完整。請?zhí)嵝芽蛻舯A羰論?jù),因為這是退貨的必要憑證。退貨流程和相關(guān)表格以及聯(lián)系信息可以提供給客戶。從結(jié)果上看與PDF文檔中的內(nèi)容保持一致。
接著,我們再提問“智能鎖失靈”的問題,這里我們不向“tech-service”提問,而向“product-service”提問。顯然,product-service的namespace 存放的文檔是關(guān)于產(chǎn)品服務(wù)相關(guān)的,并不知道“智能鎖失靈”這樣的技術(shù)支持問題。所以,先執(zhí)行代碼再看結(jié)果,代碼如下:
我不知道。很顯然結(jié)果是“我不知道”,通過上面prompt template 的定義,我們讓大模型在沒有搜索到文檔內(nèi)容的時候,不要編造任何信息,而是如實回答:“我不知道”。這也證明了在product-service的namespace中不存在與技術(shù)支持相關(guān)的信息。
最后,我們通過如下代碼詢問 tech-service,
ask_question("智能鎖失靈", "tech-service")看結(jié)果如下:
回答:首先,指導(dǎo)客戶檢查智能鎖的電源和電池狀態(tài),確認(rèn)電量是否充足。如果電量正常,請引導(dǎo)客戶重置智能鎖,具體方法是長按重置鍵5秒鐘。如果問題仍然存在,請建議客戶檢查智能鎖的軟件版本是否最新,并引導(dǎo)進(jìn)行系統(tǒng)更新。若以上步驟無法解決問題,建議客戶聯(lián)系技術(shù)支持以獲取進(jìn)一步的幫助。從結(jié)果上看,與我們的設(shè)想相同,和技術(shù)支持相關(guān)的問題從tech-service 的namespace中獲取。
總結(jié)
文章提供了一種有效的方法可以在LangChain框架下實現(xiàn)多用戶數(shù)據(jù)檢索,確保了數(shù)據(jù)安全性和隱私保護(hù)的同時,也保證了檢索系統(tǒng)的靈活性和用戶體驗。通過使用Pinecone作為向量數(shù)據(jù)庫,它克服了傳統(tǒng)標(biāo)量數(shù)據(jù)庫在處理高維向量數(shù)據(jù)時遇到的難題。文章詳細(xì)介紹了多用戶檢索的實現(xiàn)步驟,從檢索器的配置到鏈條的構(gòu)建,再到實際的代碼演示,全面覆蓋了從理論到實踐的各個方面。通過提供具體的示例和代碼,文檔使讀者能夠更容易地理解和應(yīng)用這些概念到實際的多用戶檢索任務(wù)中。
作者介紹
崔皓,51CTO社區(qū)編輯,資深架構(gòu)師,擁有18年的軟件開發(fā)和架構(gòu)經(jīng)驗,10年分布式架構(gòu)經(jīng)驗。