RadOcc:通過渲染輔助蒸餾學習跨模態Occupancy知識
原標題:Radocc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
論文鏈接:https://arxiv.org/pdf/2312.11829.pdf
作者單位:FNii, CUHK-Shenzhen SSE, CUHK-Shenzhen 華為諾亞方舟實驗室
會議:AAAI 2024

論文思路:
3D 占用預測是一項新興任務,旨在使用多視圖圖像估計 3D 場景的占用狀態和語義。然而,由于缺乏幾何先驗,基于圖像的場景感知在實現準確預測方面遇到了重大挑戰。本文通過探索該任務中的跨模態知識蒸餾來解決這個問題,即,本文在訓練過程中利用更強大的多模態模型來指導視覺模型。在實踐中,本文觀察到直接應用,在鳥瞰(BEV)感知中提出并廣泛使用的特征或 logits 對齊,并不能產生令人滿意的結果。為了克服這個問題,本文引入了 RadOcc,一種用于 3D 占用預測的渲染輔助蒸餾范式。通過采用可微體渲染(differentiable volume rendering),本文在透視圖中生成深度和語義圖,并提出了教師和學生模型的渲染輸出之間的兩個新穎的一致性標準(consistency criteria)。具體來說,深度一致性損失對齊渲染光線的終止分布(termination distributions),而語義一致性損失則模仿視覺基礎模型(VLM)引導的 intra-segment 相似性。nuScenes 數據集上的實驗結果證明了本文提出的方法在改進各種 3D 占用預測方法方面的有效性,例如,本文提出的方法在 mIoU 指標中將本文的基線提高了 2.2%,在 Occ3D 基準中達到了 50%。
主要貢獻:
本文提出了一種用于 3D 占用預測的渲染輔助蒸餾范式,名為 RadOcc。本文是第一篇探索 3D-OP 中跨模態知識蒸餾的論文,并為現有 BEV 蒸餾技術在該任務中的應用提供了寶貴的見解。
提出了兩種新穎的蒸餾約束,即渲染深度和語義一致性(RDC 和 RSC),它們通過對齊由視覺基礎模型引導的 ray distribution 和 affinity matrices,有效地增強了知識遷移過程。
配備所提出的方法,RadOcc 在 Occ3D 和 nuScenes 基準上實現了密集和稀疏占用預測的最先進性能。此外,本文驗證了本文提出的蒸餾方法可以有效提高幾個基線模型的性能。
網絡設計:
本文首次研究了針對 3D 占用預測任務的跨模態知識蒸餾。基于 BEV 感知領域現有的利用 BEV 或 logits 一致性進行知識遷移的方法,本文將這些蒸餾技術擴展到在 3D 占用預測任務中對齊體素特征和體素 logits,如圖 1(a) 所示。然而,本文的初步實驗表明,這些對齊技術在 3D-OP 任務中獲得令人滿意的結果面臨著重大挑戰,特別是前一種方法引入了負遷移(negative transfer)。這一挑戰可能源于 3D 目標檢測和占用預測之間的根本差異,后者是一項更細粒度的感知任務,需要捕獲幾何細節以及背景目標。
為了解決上述挑戰,本文提出了 RadOcc,這是一種利用可微體渲染進行跨模態知識蒸餾的新穎方法。RadOcc的核心思想是對教師模型和學生模型生成的渲染結果進行對齊,如圖1(b)所示。具體來說,本文使用相機的內參和外參對體素特征進行體渲染(Mildenhall et al. 2021),這使本文能夠從不同的視點獲得相應的深度圖和語義圖。為了實現渲染輸出之間更好的對齊,本文引入了新穎的渲染深度一致性(RDC)和渲染語義一致性(RSC)損失。一方面,RDC 損失強制光線分布(ray distribution)的一致性,這使得學生模型能夠捕獲數據的底層結構。另一方面,RSC 損失利用了視覺基礎模型的優勢(Kirillov et al. 2023),并利用預先提取的 segment 進行 affinity 蒸餾。該標準允許模型學習和比較不同圖像區域的語義表示,從而增強其捕獲細粒度細節的能力。通過結合上述約束,本文提出的方法有效地利用了跨模態知識蒸餾,從而提高了性能并更好地優化了學生模型。本文展示了本文的方法在密集和稀疏占用預測方面的有效性,并在這兩項任務上取得了最先進的結果。
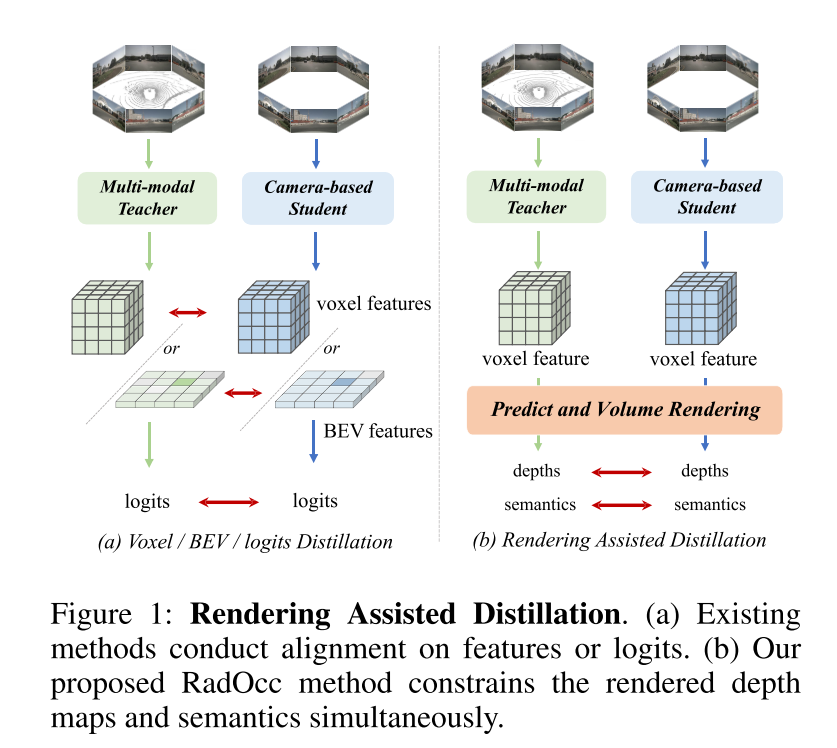
圖 1:渲染輔助蒸餾。(a) 現有方法對特征或 logits 進行對齊。(b) 本文提出的 RadOcc 方法同時約束渲染的深度圖和語義。 圖2:RadOcc的總體框架。它采用師生架構,其中教師網絡是多模態模型,而學生網絡僅接受相機輸入。兩個網絡的預測將用于通過可微分體渲染(differentiable volume rendering)生成渲染深度和語義。渲染結果之間采用了新提出的渲染深度和語義一致性損失。
圖2:RadOcc的總體框架。它采用師生架構,其中教師網絡是多模態模型,而學生網絡僅接受相機輸入。兩個網絡的預測將用于通過可微分體渲染(differentiable volume rendering)生成渲染深度和語義。渲染結果之間采用了新提出的渲染深度和語義一致性損失。
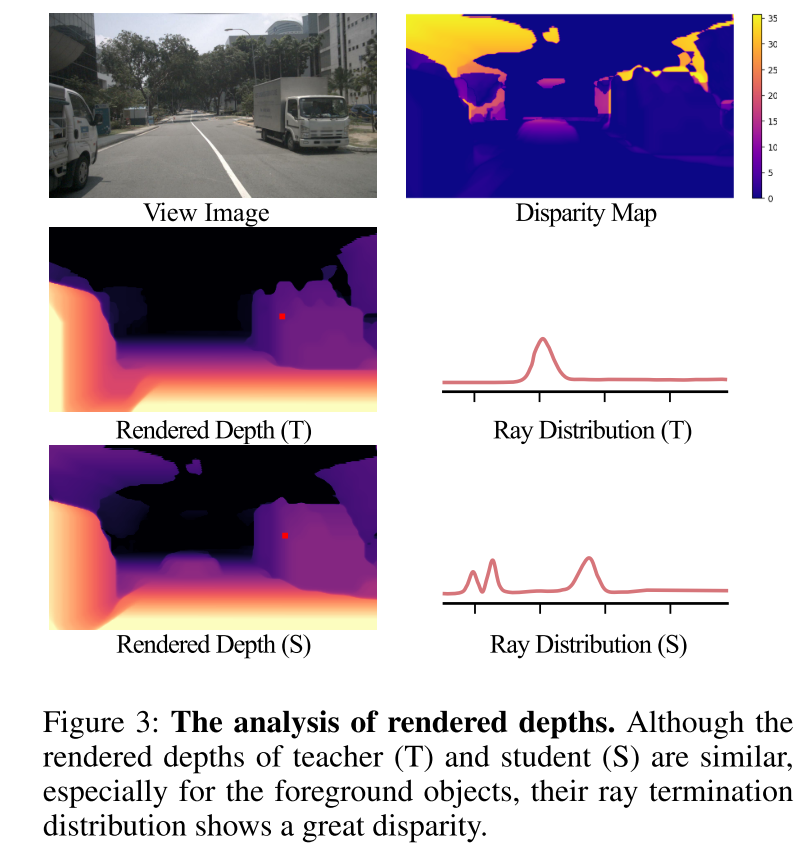
圖 3:渲染深度分析。盡管教師(T)和學生(S)的渲染深度相似,特別是對于前景物體,但它們的光線終止分布顯示出很大的差異。
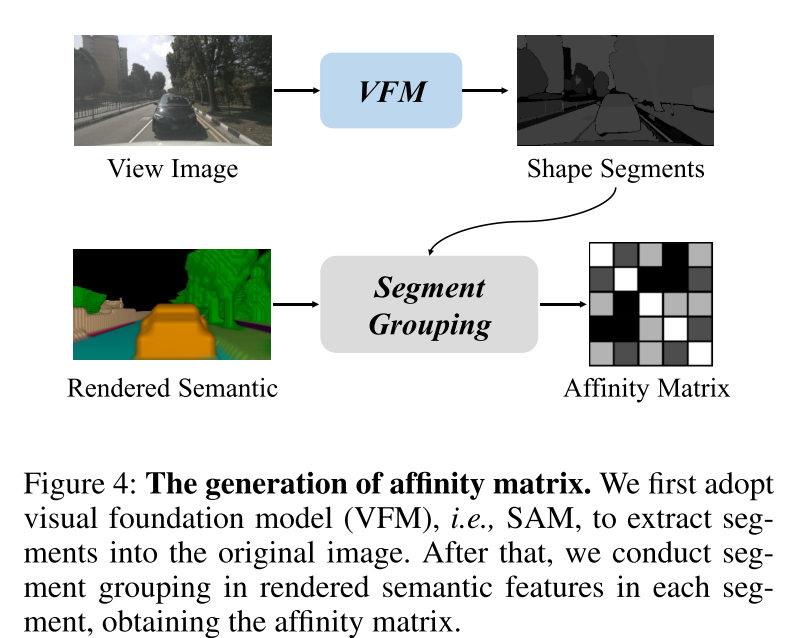
圖 4:affinity matrix 的生成。本文首先采用視覺基礎模型(VFM),即 SAM,將 segments 提取到原始圖像中。之后,本文對每個 segment 中渲染的語義特征進行 segment 聚合,獲得 affinity matrix 。
實驗結果:
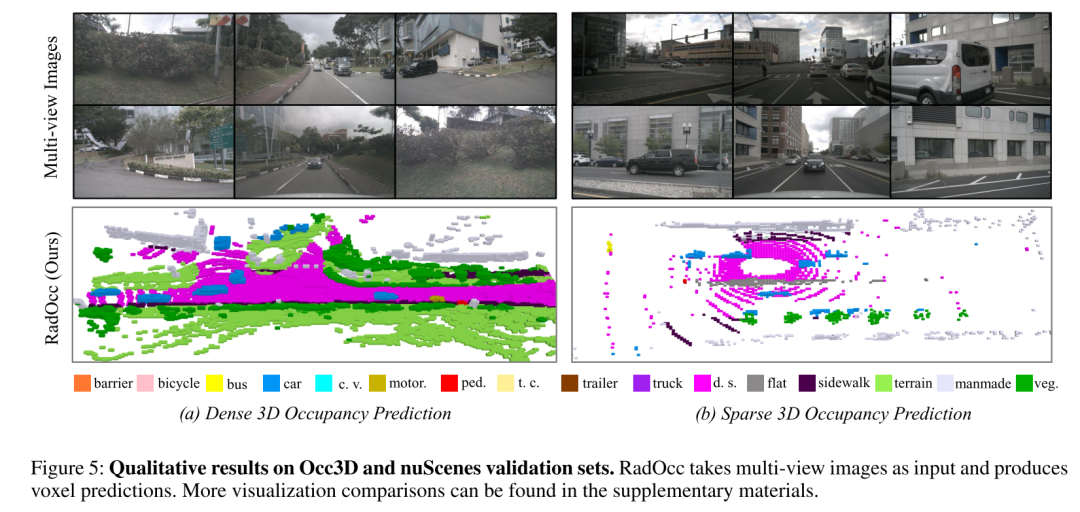


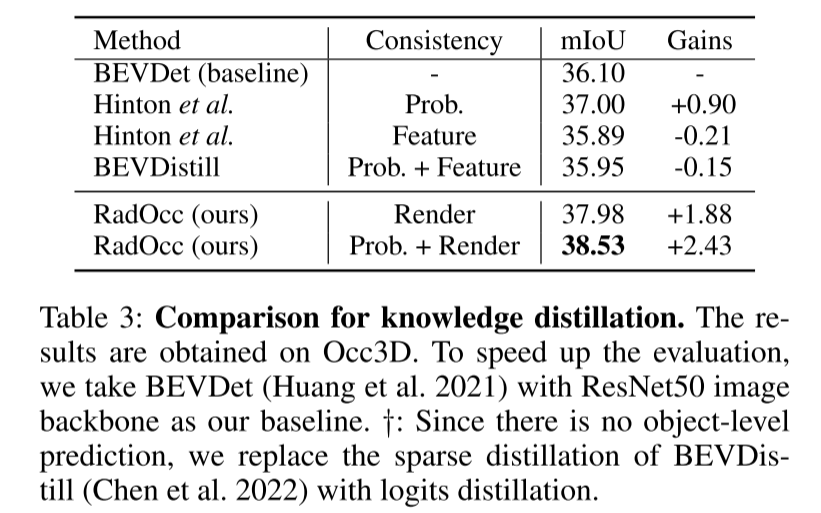
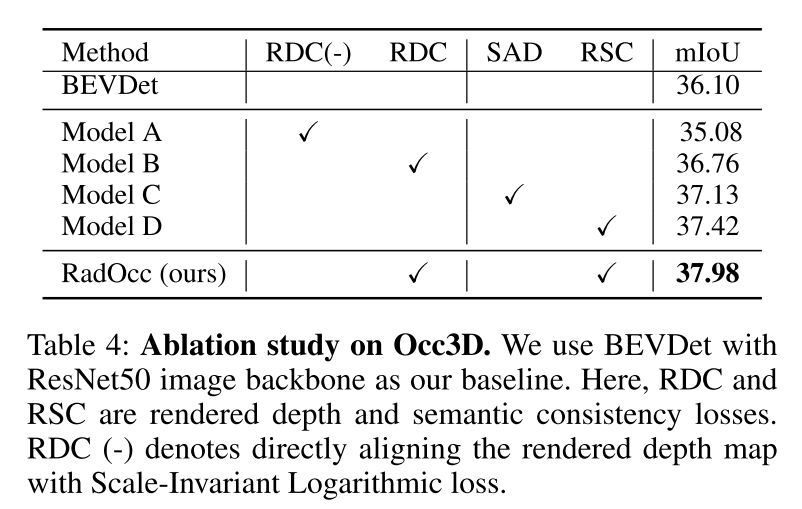
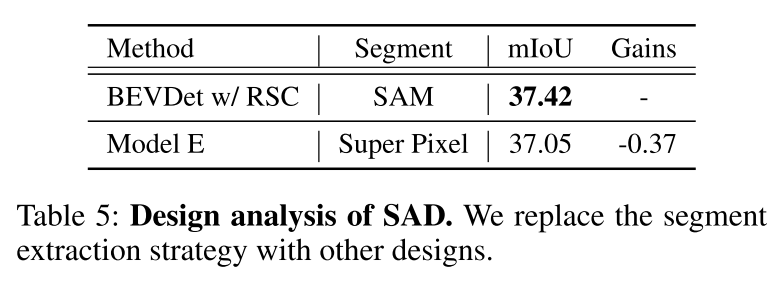
總結:
本文提出了 RadOcc,一種用于 3D 占用預測的新型跨模態知識蒸餾范式。它利用多模態教師模型通過可微分體渲染(differentiable volume rendering)為視覺學生模型提供幾何和語義指導。此外,本文提出了兩個新的一致性標準,深度一致性損失和語義一致性損失,以對齊教師和學生模型之間的 ray distribution 和 affinity matrix 。對 Occ3D 和 nuScenes 數據集的大量實驗表明,RadOcc 可以顯著提高各種 3D 占用預測方法的性能。本文的方法在 Occ3D 挑戰基準上取得了最先進的結果,并且大大優于現有已發布的方法。本文相信本文的工作為場景理解中的跨模態學習開辟了新的可能性。