拳打Gen-2腳踢Pika,谷歌爆肝7個月祭出AI視頻大模型!首提時空架構,時長史詩級延長
AI視頻賽道上,谷歌又再次放出王炸級更新!
這個名為Google Lumiere的模型,是個大規模視頻擴散模型,徹底改變了AI視頻的游戲規則。
跟其他模型不同,Lumiere憑借最先進的時空U-Net架構,在一次一致的通道中生成整個視頻。
具體來說,現有AI生成視頻的模型,大多是在生成的簡短視頻的基礎上并對其進行時間采樣而完成任務。
而谷歌推出的新模型Google Lumiere是通過是聯合空間和「時間」下采樣(downsampling)來實現生成,這樣能顯著增加生成視頻的長度和生成的質量。

論文地址:https://arxiv.org/abs/2401.12945
值得一提的是,這是谷歌團隊歷時7個月做出的最新成果。
對于這驚人的「谷歌速度」,網友們紛紛表示驚嘆——
谷歌從來不睡覺啊?
開發者回答:不睡
居然做出了走路、跳舞這樣的人體力學視頻,我的天,我以為這需要6到12個月才能做出來,AI真的是在以閃電般的速度發展。(我的工作流中需要這個模型)
全新STUNet架構:時間更長更連貫
為了解決AI視頻長度不足,運動連貫性和一致性很低,偽影重重等一系列問題,研究人員提出了一個名為Space-Time U-Net(STUNet)的架構。

傳統視頻模型生成的視頻往往會出現奇怪的動作和偽影
能夠學習將視頻信號在空間和時間上同時進行下采樣和上采樣,并在網絡的壓縮空間時間表征上執行主要計算。
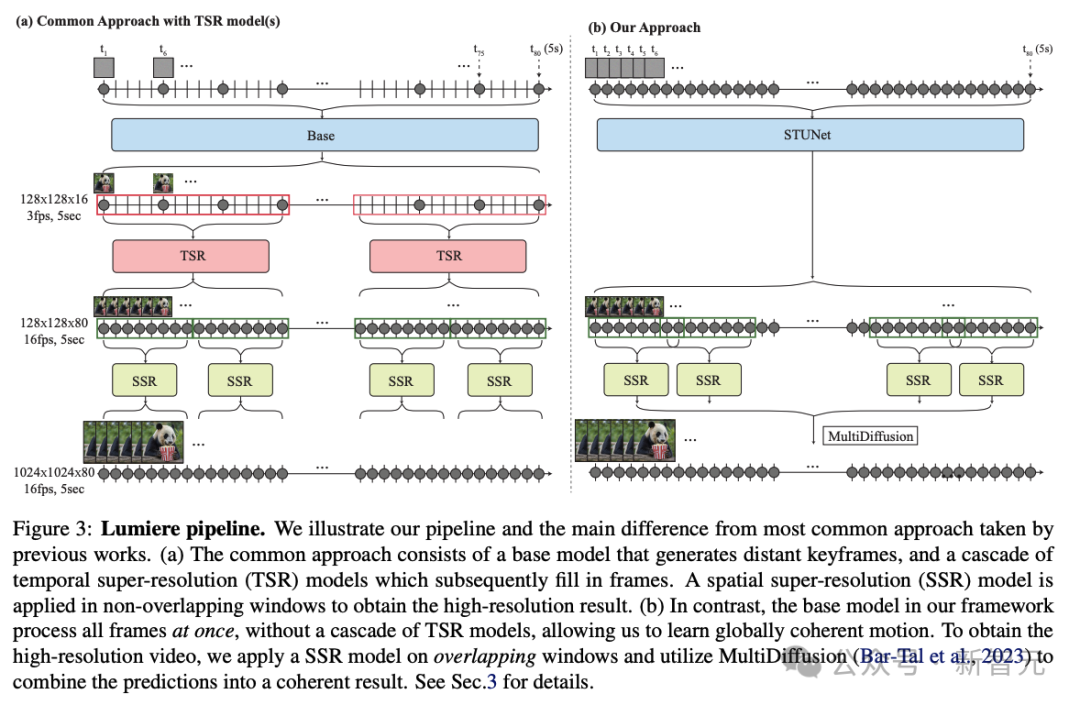
相比之前的文本到視頻模型采用級聯設計的方式,先由基模型生成關鍵幀,然后使用一系列時序超分辨率模型在非重疊段內進行插值幀的生成。
STUNet可以學習直接生成全幀率的低分辨率視頻。這種設計避免了時序級聯結構在生成全局連貫運動時固有的限制。

STUNet架構可以直接生成5秒長的80幀視頻,時間長度超過大多數媒體中的平均鏡頭長度,這可以產生比之前模型更連貫一致的運動。



功能豐富,效果拔群
視頻編輯/修復
這項功能可以讓我們編輯視頻,或者在視頻中插入對象。
比如這個穿綠底白花裙的女孩,只要選中衣服區域,輸入文字修改要求,就能瞬間把她的裙子改成紅白條紋裙、金色抹胸裙。

正在跑步的女孩,只要用文字編輯,就可以讓她長滿鮮花,或者變成木磚風、折紙風、樂高風。

也可以專門針對視頻中某一部分的內容進行修改和編輯。

圖生視頻
Lumiere另外一個非常好用的功能,就是將靜止圖像轉換為動態視頻。
輸入文字提示,就能讓戴珍珠耳環的少女從名畫中走出,張嘴笑了起來。

梵高畫的《星空》,夜空中的星星和云層真的開始流動了起來。

風格化生成
Lumiere能生成各種指定藝術風格的視頻。
只要給出一個指定的風格,再通過文字提示,就能按照類似風格生成非常多的視頻。

可以看到,對比參考靜圖的風格來看,生成視頻的風格復現得非常精準。

動作筆刷
通過這個名為Cinemagraphs(又名 Motion Brush)的風格,我們可以選中靜圖中的特定部分,讓它動起來。
選中圖中的這團火焰,它就開始熊熊燃燒起來。

選中圖中的煙,火車就開始冒出汩汩濃煙來。

文生視頻
當然,Lumiere也可以直接從文本生成詳細的視頻。
無論是一個在火星基地周圍漫步的宇航員。

還是一只戴著太陽鏡開著車的狗。

或者飛過一座廢棄的廟宇,在遺跡中穿行。

還可以針對視頻中缺失的部分進行補充。

STUNet架構帶來的全新突破
這次,谷歌的研究者采用了跟以往不同的方法,引入了新的T2V擴散框架,該框架可以立即生成視頻的完整持續時間。
為了實現這一目標,他們使用了STUNet架構,這個架構可以學習在空間和時間上對信號進行下采樣,并且以壓縮的時空表征形式,執行大部分計算。

Lumiere生成的示例結果,包括文本到視頻生成(第一行)、圖像到視頻(第二行)、風格引用生成和視頻修復(第三行邊界框表示修復掩碼區域)
采用這種方法,就能夠以16fps(或5秒)生成80幀,這比大多數使用單一基礎模型的媒體要好。
跟之前的工作相比,產生了更多的全局連貫運動。
令人驚訝的是,這種設計選擇被以前的T2V模型忽視了,這些模型遵循慣例,在架構中僅包含空間下采樣和上采樣操作,并在整個網絡中保持固定的時間分辨率。

使用Lumiere和ImagenVideo進行周期性運動生成視頻的代表性示例。研究者應用 Lumiere圖像到視頻生成,以ImagenVideo生成的視頻的第一幀為條件,可視化相應的X-T切片。由于其級聯設計和時間超分辨率模塊,Imagenvideo難以生成全局連貫的重復運動,而這些模塊無法跨時間窗口,一致地解決混疊模糊問題
研究人員的框架由基本模型和空間超分辨率(SSR)模型組成。

如上圖3b所示,研究人員的基礎模型以粗略的空間分辨率生成完整的剪輯。
他們的基礎模型的輸出使用時間感知的SSR模型進行空間上采樣,從而產生高分辨率視頻。

研究人員的架構如上圖所示。
他們在T2I架構中交織時間塊,并在每個預訓練的空間調整大小模塊之后插入時間下采樣和上采樣模塊(圖4a)。時間塊包括時間卷積(圖4b)和時間注意力(圖4c)。
具體來說,在除了最粗糙的級別之外的所有級別中,他們插入因式分解的時空卷積(圖4b),與全3D卷積相比,它允許增加網絡中的非線性,同時降低計算成本,并與一維卷積。
由于時間注意力的計算要求與幀數呈二次方關系,因此他們僅在最粗分辨率下合并時間注意力,其中包含視頻的時空壓縮表示。
在低維特征圖上進行操作允許他們以有限的計算開銷堆疊多個時間注意力塊。
研究人員訓練新添加的參數,并保持預訓練T2I的權重固定。值得注意的是,常見的膨脹方法確保在初始化時,T2V模型相當于預訓練的T2I模型,即生成視頻作為獨立圖像樣本的集合。
然而,在研究人員的例子中,由于時間下采樣和上采樣模塊,不可能滿足這個屬性。
他們憑經驗發現,初始化這些模塊以使它們執行最近鄰下采樣和上采樣操作會產生一個良好的起點(就損失函數而言)。
應用展示
以下是文生視頻和圖像生視頻的示例。
從圖像到視頻的示例中,最左邊的幀是作為條件提供給模型的。




以下是風格化生成的示例。
給定起始風格圖像及其相應的一組微調文本到圖像權重,就可以在模型空間層的微調權重和預訓練權重之間執行線性插值。
研究者展示了(A)矢量藝術風格和(B)寫實風格的結果。
這證明了,Lumiere能夠為每種空間風格創造性地匹配不同的運動(幀從左到右顯示)。




以下是使用Lumiere進行視頻修復的示例。
對于每個輸入視頻(每個幀的左上角),研究者都使用了Lumiere對視頻的掩碼區域進行了動畫處理。


以下為動態圖像的示例。
僅給定輸入圖像和掩碼(左),研究者的方法會生成一個視頻,其中標記區域是動態的,其余部分保持靜態(右)。

以下是通過SDEdit進行視頻生視頻的示例。
Lumiere基本模型可以生成全幀率視頻,無需TSR級聯,從而為下游應用程序提供更直觀的界面。
研究者通過使用SDEdit來演示此屬性,從而實現一致的視頻風格化。
在第一行顯示給定輸入視頻的幾個幀,下面幾行顯示相應的編輯幀。


與Gen-2和Pika等模型的對比和評估
定性評估
研究人員在下圖中展示了他們的模型和基線之間的定性比較。

研究人員觀察到Gen-2和Pika表現出較高的每幀視覺質量,然而,它們的輸出的特點是運動量非常有限,通常會產生接近靜態的視頻。
ImagenVideo產生合理的運動量,但整體視覺質量較低。AnimateDiff和ZeroScope表現出明顯的運動,但也容易出現視覺偽影。
此外,它們生成的視頻持續時間較短,分別為2秒和3.6秒。
相比之下,研究人員的方法生成的5秒視頻具有更高的運動幅度,同時保持時間一致性和整體質量。
定量評估
研究人員在UCF101上定量評估了他們的零樣本文本到視頻生成方法。

上表1展示了他們的方法和之前工作的區別(FVD)和初始分數(IS)。
研究人員的系統取得了具有競爭力的FVD和IS分數。然而,正如之前的工作中所討論的,這些指標并不能準確地反映人類的感知,并且可能會受到低級細節以及參考UCF101數據和T2V訓練數據之間的分布變化。
此外,該協議僅使用生成視頻中的16幀,因此無法捕獲長期運動。
用戶研究
研究人員采用了之前的工作中使用的兩種選擇強制選擇(2AFC)協議。
在該協議中,向參與者展示了一對隨機選擇的視頻:一個由研究人員的模型生成,另一個由一種基線方法生成。然后,參與者被要求選擇他們認為在視覺質量和動作方面更好的視頻。
此外,他們還被要求選擇與目標文本提示更準確匹配的視頻。研究人員利用 Amazon Mechanical Turk(AMT)平臺收集了約400個用戶對每個基線和問題的判斷。

如上圖所示,研究人員的方法比所有基線都更受用戶青睞,并且與文本提示聯系更加緊密。
請注意,ZeroScope和AnimateDiff分別僅生成3.6秒和2秒的視頻,因此在與它們進行比較時,研究人員會修剪視頻以匹配其持續時間。
研究人員進一步進行了一項用戶研究,將他們的圖像到視頻模型與Pika、Stable Video Diffusion(SVD)和Gen-2進行比較。
請注意,SVD圖像到視頻模型不以文本為條件,因此研究人員將調查重點放在視頻質量上。如上圖所示,與基線相比,研究人員的方法更受用戶青睞。