













谷歌最新開源的 Gemma 模型,秒殺 Llma-2!

Gemma 是什么
Gemma 是一個輕量級、最先進的開放式模型系列,采用了與創建 Gemini 模型相同的研究和技術。Gemma 由 Google DeepMind 和 Google 的其他團隊共同開發,其靈感來源于雙子座,名字反映了拉丁語 gemma,意為 "寶石"。在發布模型權重的同時,谷歌還將發布相關工具,以支持開發人員創新、促進協作,并指導負責任地使用 Gemma 模型。
以下是需要了解的關鍵細節:
- 兩種尺寸的模型權重:Gemma 2B 和 Gemma 7B。每種尺寸都發布了預訓練和指令調整變體。
- 新的 “Responsible Generative AI Toolkit” 為使用 Gemma 創建更安全的人工智能應用提供了指導和基本工具。
- 為所有主要框架的推理和監督微調(SFT)提供了工具鏈:JAX、PyTorch 和 TensorFlow,以及本地 Keras 3.0。
- 現成可用的 Colab 和 Kaggle 筆記本,以及與 Hugging Face、MaxText、NVIDIA NeMo 和 TensorRT-LLM 等流行工具的集成,使 Gemma 的上手非常容易。
- 經過預訓練和指令調整的 Gemma 模型可在你的筆記本電腦、工作站或谷歌云上運行,并可在 Vertex AI 和谷歌 Kubernetes Engine (GKE) 上輕松部署。
- 跨多個人工智能硬件平臺的優化確保了行業領先的性能,包括英偉達?(NVIDIA?)GPU 和谷歌云 TPU。
- 使用條款允許負責任的商業使用和傳播。
Gemma 模型與 Gemini 共享技術和基礎設施組件,而 Gemini 是目前市場上最大、功能最強的人工智能模型。這使得 Gemma 2B 和 7B 與其他開放模型相比,在其規模上實現了同類最佳的性能。而且,Gemma 模型能夠直接在開發人員的筆記本電腦或臺式電腦上運行。值得注意的是,Gemma 在關鍵基準上超過了更大的模型,同時還符合嚴格的安全和負責任的輸出標準。
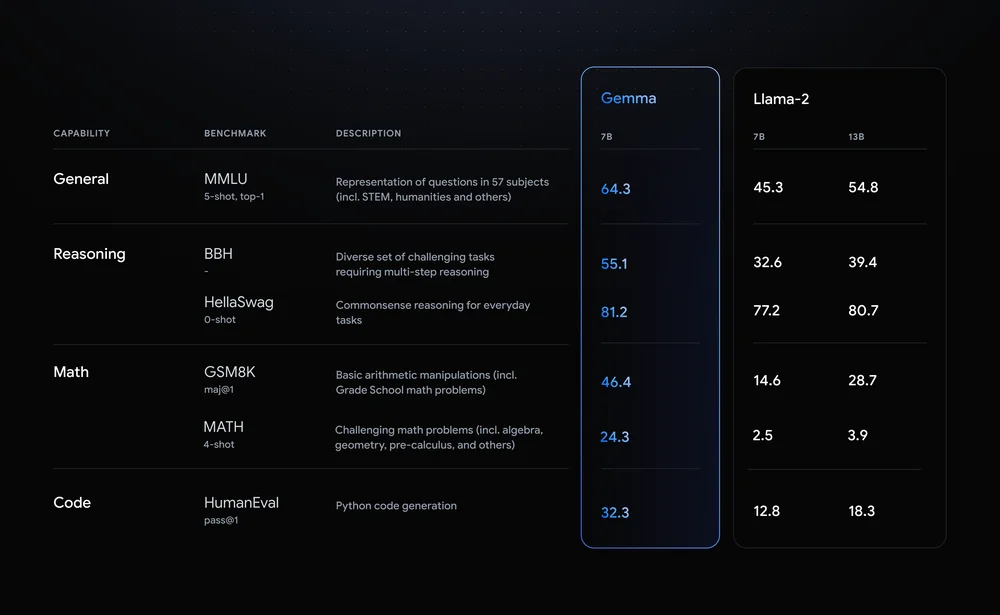
由上圖的測評數據來看,Gemma 7B 模型的能力,已經秒殺同級的 Llma-2 7B,而且還完全超越 Llama-2 13B。接下來,本文將介紹如何快速體驗最新的 Gemma 模型。
Ollama 運行 Gemma
首先,先確保你電腦已經安裝 ollama[1],如果還沒安裝的話,可以參考 “部署本地的大語言模型,只需幾分鐘!” 這篇文章。
成功安裝 ollama 之后,可以在命令行輸入以下命令來運行 Gemma 2b 或 Gemma 7b 模型:
ollama run gemma:2b
# Or
ollama run gemma:7b運行該命令后,會自動下載 Gemma 2B 或 Gemma 7B 模型。如果你的電腦擁有足夠的內存,可以使用以下命令安裝非量化的版本,即使用精度更高的版本,以體驗更好效果:
ollama run gemma:2b-instruct-fp16
# Or
ollama run gemma:7b-instruct-fp16除了 ollama 之外,你也可以通過 llama.cpp[2] 或 gemma.cpp[3] 來體驗 gemma。
llama.cpp 運行 Gemma
來源:https://github.com/ggerganov/llama.cpp/pull/5631
gemma.cpp 運行 Gemma

來源:https://github.com/google/gemma.cpp
本文介紹了 3 種方式來體驗谷歌最新的 Gemma 開源模型,感興趣的小伙伴,可以體驗一下該模型的效果。
參考資料
[1]ollama: https://ollama.com/
[2]llama.cpp: https://github.com/ggerganov/llama.cpp
[3]gemma.cpp: https://github.com/google/gemma.cpp



























