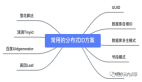
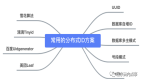
面試官:你知道哪些分布式ID生成方案?
近兩年的技術面試,分布式系列是面試官經常會問到的一個高頻方向,比如:分布式事務、分布式鎖、分布式調度、分布式存儲、分布式ID等。
今天我們就來聊聊,這里面相對簡單的分布式ID,首先說下,我們為什么需要分布式ID?
當系統數據量過大,已經進行分庫分表后,我們需要對分散在各個庫表中的數據記錄進行唯一標識,而分布式ID恰好用來解決這個問題。
接下來,我們看看八大分布式ID的生成方案,以及各自的優缺點是什么。
 圖片
圖片
1、UUID
UUID是 Universally Unique Identifier 的縮寫,翻譯成中文為“通用唯一識別碼”,由32個16進制數字 + 4個“-”構成,整體長度為36,其可以保證唯一性,發生碰撞的概率極低。
UUID目前有5個版本,每個版本都有不同的生成方式。目前最常用的是版本4,通過隨機數的方式生成。
UUID的生成實現方式非常簡單,可以通過java.util包,一行代碼即可實現。
import java.util.UUID;
public class Test {
public static void main(String[] args) {
System.out.println(“本次生成的UUID為” + UUID.randomUUID());
}
}
//打印結果
//本次生成的UUID為:05cb2d06-1aca-4121-acb0-dfafce04dc46優點:
(1)技術實現簡單,一行代碼即可。(2)本地即可生成,出錯率低。(3)ID生成性能高。
缺點:
(1)無序,影響數據庫的數據寫入性能。(2)存儲成本高,就算去掉4個“-”,長度也是32。(3)可讀性差。
2、數據庫自增ID
選擇一個數據庫作為中央數據庫,利用該庫中某表的自增主鍵機制生成分布式ID。
 圖片
圖片
對應SQL語句如下:
REPLACE INTO id_table (stub) values (’a‘) ;
SELECT LAST_INSERT_ID();該SQL語句可以使 id_table 表中在保持一條數據記錄的情況下,主鍵ID持續遞增。
優點:
(1)單調遞增,不會影響數據庫的數據寫入性能。(2)可讀性高。
缺點:
(1)ID生成涉及到數據庫操作,性能不高。(2)需要額外引入中央數據庫,鏈路變長導致出錯概率增加。(3)開發成本相對較高。(4)數據庫壓力大。
3、Redis自增命令
通過Redis的INCR自增命令來生成分布式ID。
 圖片
圖片
如下所示:
127.0.0.1:6379> set distributed_id 1 // 將分布式ID初始化為1
OK
127.0.0.1:6379> incr distributed_id // +1,并返回結果
(integer) 2優點:
(1)單調遞增,不會影響數據庫的數據寫入性能。(2)ID生成性能高。(3)可讀性高。
缺點:
(1)需要額外引入Redis,鏈路變長導致出錯概率增加。(2)Redis宕機后,RDB + AOF數據恢復較慢,需要Plan B提升恢復速度。(3)開發成本相對較高。
4、雪花算法
雪花算法(SnowFlake),是Twitter公司開源的分布式ID生成算法,在本地引入hutool jar包即可實現。
雪花算法生成的分布式ID共64位,由4個部分組成。
 圖片
圖片
- 第一部分:1位。固定為0,表示為正整數。二進制中最高位是符號位,ID為正整數,所以固定為0。
- 第二部分:41位。表示精確到毫秒的時間戳,時間戳帶有自增屬性,可以使用69年。
- 第三部分:10位。表示10位的機器標識,最多支持1024個節點。
- 第四部分:12 位。表示自增序列,可以支持同一節點同一毫秒生成最多4096個ID。
優點:
(1)技術實現簡單,開發成本低。(2)趨勢遞增,不會影響數據庫的數據寫入性能。(3)本地即可生成,出錯率低。(4)ID生成性能高。
缺點:
(1)強依賴機器時鐘,如果機器上時鐘回撥,會導致ID重復。(2)可讀性差。
5、數據庫號段
數據庫號段,是在“數據庫自增ID”方案上做的優化,實現方式如下:
(1)從中央數據庫中獲取出一批分布式ID,并緩存到分布式ID服務本地,業務系統獲取分布式ID的時候,可直接在這個批次內遞增取值。(2)若該批次分布式ID的號段用完,則需要更新數據庫中的初始值,再次獲取新批次的分布式ID,并重新緩存到分布式ID服務本地,以供使用。
 圖片
圖片
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '當前最大id',
step int(10) NOT NULL COMMENT '號段的長度',
biz_type int(10) NOT NULL COMMENT '業務類型',
version int(10) NOT NULL COMMENT '版本號,是一個樂觀鎖,每次都更新version,保證并發時數據的正確性',
PRIMARY KEY (`id`)
)優點:
(1)趨勢遞增,不會影響數據庫的數據寫入性能。(2)ID生成性能高。(3)數據庫壓力小。(4)可讀性高。
缺點:
(1)開發成本很高。(2)需要額外引入分布式ID服務和中央數據庫,鏈路變長導致出錯概率增加。
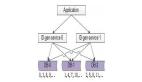
6、美團 Leaf
Leaf,是美團技術團隊實現的分布式ID生成方案,實現了數據庫號段模式(Leaf-segment)和雪花算法模式(Leaf-snowflake),我們這里著重說Leaf-snowflake。
Leaf-snowflake方案完全沿用snowflake算法方案的bit位設計,即:以“1+41+10+12”的方式組裝ID號,改動點為:將SnowFlake從本地jar包變成了獨立服務,并引入了Zookeeper來解決時鐘回撥問題。
 圖片
圖片
優點:
(1)趨勢遞增,不會影響數據庫的數據寫入性能。(2)解決了原有的機器上時鐘回撥,會出現的ID重復問題。(3)ID生成性能高。
缺點:
(1)第三方開源軟件,有一定的熟悉和試錯成本。(2)需要額外引入分布式ID服務和Zookeeper,鏈路變長導致出錯概率增加。(3)可讀性差。
7、滴滴 Tinyid
Tinyid,是滴滴技術團隊實現的分布式ID生成算法,基于上文介紹的號段模式實現,在此基礎上支持數據庫多主節點模式,還提供了tinyid-client客戶端的接入方式。
除此之外,Tinyid做的另一個優化點是號段預加載。
舉個例子:當前可用號段(1——1000)被加載到內存,獲取id時會從1開始遞增獲取,當使用到20%(默認)時,會異步加載下一可用號段(4001——5000)到內存,此時內存中可用號段為(201——1000)和(4001——5000)。
當id遞增到1000時,當前號段使用完畢,下一號段會替換為當前號段,以此類推。
 圖片
圖片
優點:
(1)趨勢遞增,不會影響數據庫的數據寫入性能。(2)ID生成性能高。(3)數據庫壓力小。(4)可讀性高。
缺點:
(1)第三方開源軟件,有一定的熟悉和試錯成本。(2)需要額外引入分布式ID服務和中央數據庫,鏈路變長導致出錯概率增加。
8、百度 UidGenerator
UidGenerator是Java實現的,基于Snowflake算法的唯一ID生成器。
UidGenerator以組件形式工作在應用項目中, 支持自定義workerId位數和初始化策略。
在實現上,UidGenerator通過借用未來時間,來解決sequence天然存在的并發限制,采用RingBuffer來緩存已生成的UID,并行化UID的生產和消費,同時對CacheLine補齊,避免了由RingBuffer帶來的硬件級“偽共享”問題,最終單機QPS可達600萬。
 圖片
圖片
- 第一部分:1位,符號標識,即生成的UID為正數。
- 第二部分:28位,當前時間,相對于時間基點"2016-05-20"的增量值,單位為秒,最多可支持約8.7年。
- 第三部分:22位,機器ID,最多可支持約420w次機器啟動。
- 第四部分:13位,每秒下的并發序列,最多可支持每秒8192個并發。
我們從這里可以看到,相比較于SnowFlake,UidGenerator的時間bit變少了,而機器ID的bit變多了。
優點:
(1)趨勢遞增,不會影響數據庫的數據寫入性能。(2)本地即可生成,出錯率低。(3)ID生成性能極高。
缺點:
(1)第三方開源軟件,有一定的熟悉和試錯成本。(2)強依賴機器時鐘,如果機器上時鐘回撥,會導致ID重復。(3)可讀性差。
結語
這八大分布式ID生成方案,目前最常用的方案為雪花算法和數據庫號段方式。
當然,最常用的未必是最適合你所負責的系統的,大家還是需要根據各自的特性來進行選擇。