分布式系統中的唯一ID有哪些生成方式
在后端系統中,每條記錄都需要一個唯一的ID來進行標識。
雖然一開始聽起來可能很瑣碎,但在高度分布式的環境中生成全局唯一標識符實際上是一個具有挑戰性的任務。

在本文中,讓我們來看一下一些常見的已知ID生成算法。
Ticket 服務 - 集中式數據庫
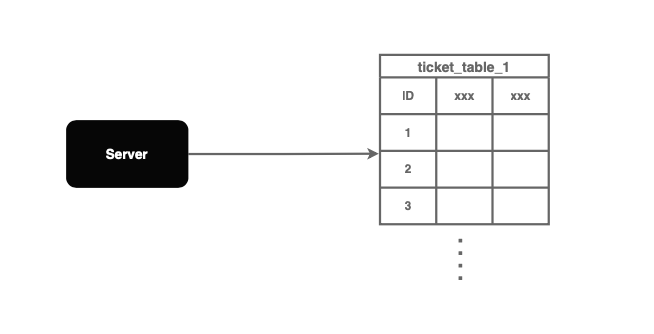
使用自增功能生成ID
Ticket 服務解決方案利用 SQL 數據庫中的自增功能來生成唯一的ID。
使用集中式數據庫服務器,Web 服務器插入一個新記錄到數據庫中以生成一個自增的ID。
CREATE TABLE `ID` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY (stub)
);
REPLACE INTO ID (stub) VALUES ('a');
SELECT LAST_INSERT_ID();與使用 INSERT INTO 命令不同,我們可以使用 REPLACE INTO 命令來減少數據庫中的記錄數量。
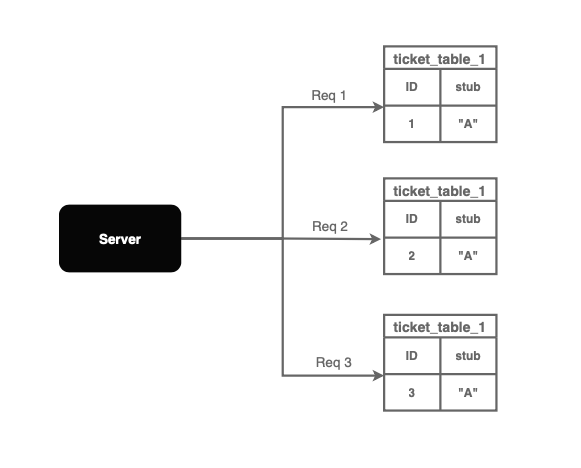
REPLACE INTO 命令以原子方式原地更新單行,并獲取自增的主 ID,而無需創建新記錄。
優點:
- 實現簡單
- 生成的ID是64位的
- ID是順序且可排序的
缺點:
- 只能使用1個表。多個表或數據庫將導致ID沖突
- 由于只使用了1個表,數據庫成為了單點故障
- 如果每秒的寫入數量巨大,將會有寫入瓶頸
Ticket 服務 - 集群式數據庫
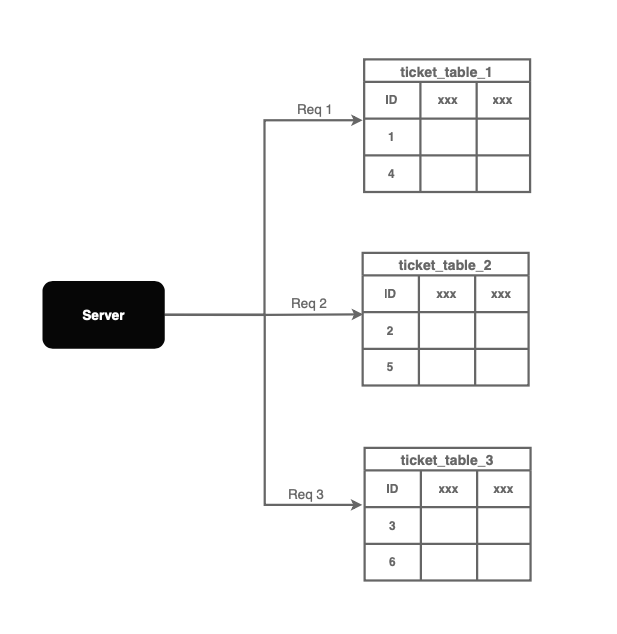
使用輪詢路由請求
與使用一個數據庫不同,我們可以使用多個具有偏移量的數據庫,以避免單點故障和寫入瓶頸。
偏移量 用于防止ID沖突。每個數據庫通過 k,k 是正在使用的數據庫服務器數量,增加其ID。
如上所示,如果使用了三個數據庫,每次生成ID時,自增的ID增加3。
優點:
- 相對容易實現
- 生成的ID是64位的
- 能夠在沒有單點故障的情況下處理高吞吐量
缺點:
- 由于使用了多個數據庫,生成的ID不能保證是可排序的
- 難以水平擴展。添加新數據庫很棘手,因為它會影響偏移量。
Twitter Snowflake
Snowflake方法在不依賴數據庫的情況下生成 64位的ID。
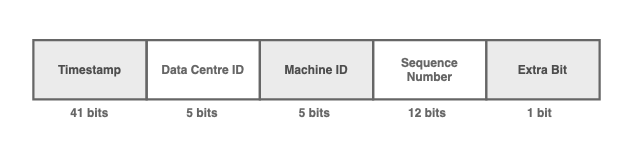
64位的ID被分成5個主要部分
ID分為5個主要部分:
- 時間戳(41位)
- 數據中心ID(5位)
- 機器ID(5位)
- 序列號(12位)
- 符號位(1位)
時間戳。自紀元以來的毫秒數。41位大約會在70年內溢出,對于大多數項目的壽命來說是安全的。
數據中心ID。服務器所在的數據中心。如果兩個服務器在相同的時間收到相同的請求,則可以防止ID沖突。
機器ID。機器的ID。如果兩臺服務器在相似的數據中心中的相同時間收到相同的請求,則可以防止沖突。
序列號。對于在同一服務器上生成的每個ID,序列號會遞增1,并在每毫秒重置為0。這可以防止在同一服務器上的ID沖突。
優點:
- ID大致是有序的
- 能夠在沒有單點故障的情況下處理高吞吐量
- 能夠在機器之間無需協調地生成ID
- 能夠水平擴展。
缺點:
- ID不是完全有序的
- 未來的ID是可預測的。對于安全要求較高的應用程序可能不理想
- 需要一個Zookeeper來跟蹤機器ID。
MongoDB ObjectID
MongoDB為每個新文檔創建一個唯一的對象ID。
對象ID由 MongoDB驅動程序生成而不是數據庫。這意味著可以在服務器上生成對象ID,而不依賴于MongoDB數據庫。
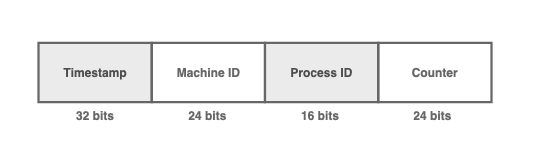
MongoDB對象ID是一個96位的ID
與Snowflake方法類似,MongoDB對象ID分為4個部分。對象ID是一個96位的ID。
- 時間戳(32位)
- 機器ID(24位)
- 進程ID(16位)
- 計數器(24位)
大部分字段與Snowflake方法中提到的字段相似。
由于同一臺機器上可能運行多個線程或進程,因此進程ID可以區分在不同進程中由同一臺機器生成的對象ID。
優點:
- 能夠在沒有單點故障的情況下處理高吞吐量
- 能夠在機器之間無需協調地生成ID
- 能夠水平擴展。
缺點:
- 依賴第三方數據庫解決方案
- ID的長度為96位,而不是64位,需要更多的存儲空間。
UUID(通用唯一標識符)

128位UUID的示例
通用唯一標識符是一個128位的數字,包括多個部分,例如時間、節點的MAC地址或MD5哈希的命名空間。
有一組標準化的算法用于生成UUID,多年來已經發布了5個不同版本的UUID,以適應不同的需求。
這些算法相當冗長,因此我們不會詳細介紹它們。我們將更多地關注它的優缺點。
優點:
- 它是一個128位的ID,保證是唯一的
- 可以獨立生成,無需依賴任何第三方服務
- 它是隨機的和安全的。下一個ID是不可預測的。
缺點:
- 它很大,在MySQL中索引不佳
- 它不是有序的
結論

在分布式環境中實現高度可擴展和可用的ID生成器并不是微不足道的。