













復旦等發布AnyGPT:任意模態輸入輸出,圖像、音樂、文本、語音都支持
最近,OpenAI 的視頻生成模型 Sora 爆火,生成式 AI 模型在多模態方面的能力再次引起廣泛關注。
現實世界本質上是多模態的,生物體通過不同的渠道感知和交換信息,包括視覺、語言、聲音和觸覺。開發多模態系統的一個有望方向是增強 LLM 的多模態感知能力,主要涉及多模態編碼器與語言模型的集成,從而使其能夠跨各種模態處理信息,并利用 LLM 的文本處理能力來產生連貫的響應。
然而,該策略僅限于文本生成,不包含多模態輸出。一些開創性工作通過在語言模型中實現多模態理解和生成取得了重大進展,但這些模型僅包含單一的非文本模態,例如圖像或音頻。
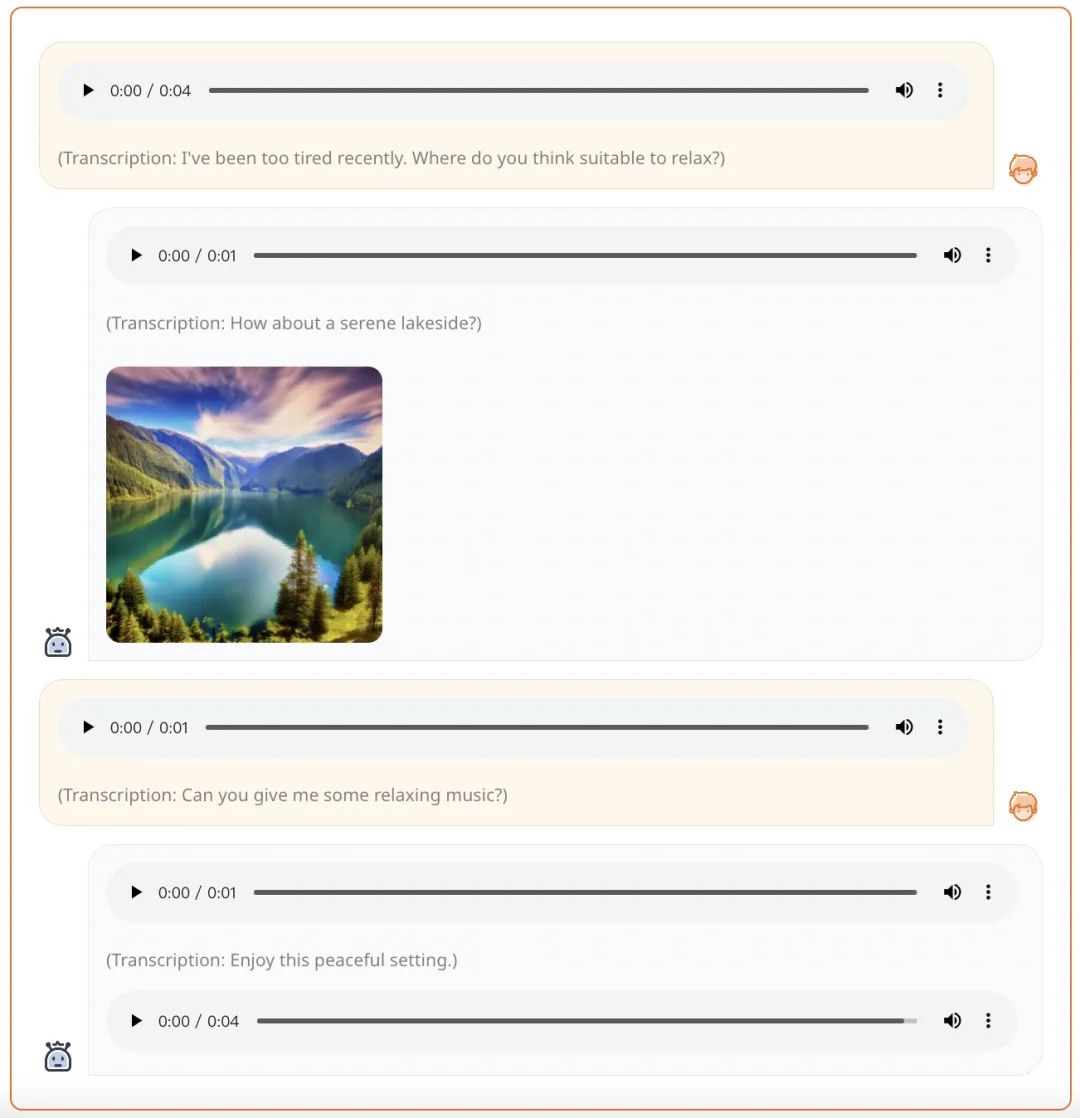
為了解決上述問題,復旦大學邱錫鵬團隊聯合 Multimodal Art Projection(MAP)、上海人工智能實驗室的研究者提出了一種名為 AnyGPT 的多模態語言模型,該模型能夠以任意的模態組合來理解和推理各種模態的內容。具體來說,AnyGPT 可以理解文本、語音、圖像、音樂等多種模態交織的指令,并能熟練地選擇合適的多模態組合進行響應。
例如給出一段語音 prompt,AnyGPT 能夠生成語音、圖像、音樂形式的綜合響應:
給出文本 + 圖像形式的 prompt,AnyGPT 能夠按照 prompt 要求生成音樂:


- 論文地址:https://arxiv.org/pdf/2402.12226.pdf
- 項目主頁:https://junzhan2000.github.io/AnyGPT.github.io/
方法簡介
AnyGPT 利用離散表征來統一處理各種模態,包括語音、文本、圖像和音樂。
為了完成任意模態到任意模態的生成任務,該研究提出了一個可以統一訓練的綜合框架。如下圖 1 所示,該框架由三個主要組件組成,包括:
- 多模態 tokenizer
- 作為主干網絡的多模態語言模型
- 多模態 de-tokenizer

其中,tokenizer 將連續的非文本模態轉換為離散的 token,隨后將其排列成多模態交錯序列。然后,語言模型使用下一個 token 預測訓練目標進行訓練。在推理過程中,多模態 token 被相關的 de-tokenizer 解碼回其原始表征。為了豐富生成的質量,可以部署多模態增強模塊來對生成的結果進行后處理,包括語音克隆或圖像超分辨率等應用。
AnyGPT 可以穩定地訓練,無需對當前的大型語言模型(LLM)架構或訓練范式進行任何改變。相反,它完全依賴于數據級預處理,使得新模態無縫集成到 LLM 中,類似于添加新語言。
這項研究的一個關鍵挑戰是缺乏多模態交錯指令跟蹤數據。為了完成多模態對齊預訓練,研究團隊利用生成模型合成了第一個大規模「任意對任意」多模態指令數據集 ——AnyInstruct-108k。它由 108k 多輪對話樣本組成,這些對話錯綜復雜地交織著各種模態,從而使模型能夠處理多模態輸入和輸出的任意組合。


這些數據通常需要大量比特才能準確表征,從而導致序列較長,這對語言模型的要求特別高,因為計算復雜度隨著序列長度呈指數級增加。為了解決這個問題,該研究采用了兩階段的高保真生成框架,包括語義信息建模和感知信息建模。首先,語言模型的任務是生成在語義層面經過融合和對齊的內容。然后,非自回歸模型在感知層面將多模態語義 token 轉換為高保真多模態內容,在性能和效率之間取得平衡。


實驗
實驗結果表明,AnyGPT 能夠完成任意模態對任意模態的對話任務,同時在所有模態中實現與專用模型相當的性能,證明離散表征可以有效且方便地統一語言模型中的多種模態。
該研究評估了預訓練基礎 AnyGPT 的基本功能,涵蓋所有模態的多模態理解和生成任務。該評估旨在測試預訓練過程中不同模態之間的一致性,具體來說是測試了每種模態的 text-to-X 和 X-to-text 任務,其中 X 分別是圖像、音樂和語音。
為了模擬真實場景,所有評估均以零樣本模式進行。這意味著 AnyGPT 在評估過程中不會對下游訓練樣本進行微調或預訓練。這種具有挑戰性的評估設置要求模型泛化到未知的測試分布。
評估結果表明,AnyGPT 作為一種通用的多模態語言模型,在各種多模態理解和生成任務上取得了令人稱贊的性能。
圖像
該研究評估了 AnyGPT 在圖像描述任務上的圖像理解能力,結果如表 2 所示。

文本到圖像生成任務的結果如表 3 所示。
 語音
語音
該研究通過計算 LibriSpeech 數據集的測試子集上的詞錯誤率 (WER) 來評估 AnyGPT 在自動語音識別 (ASR) 任務上的性能,并使用 Wav2vec 2.0 和 Whisper Large V2 作為基線,評估結果如表 5 所示。


音樂
該研究在 MusicCaps 基準上評估了 AnyGPT 在音樂理解和生成任務方面的表現,采用 CLAP_score 分數作為客觀指標,衡量生成的音樂和文本描述之間的相似度,評估結果如表 6 所示。

感興趣的讀者可以閱讀論文原文,了解更多研究內容。





















