最新綜述!擴(kuò)散模型與圖像編輯的愛(ài)恨情仇
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
針對(duì)圖像編輯中的擴(kuò)散模型,中科院聯(lián)合Adobe和蘋(píng)果公司的研究人員發(fā)布了一篇重磅綜述。
全文長(zhǎng)達(dá)26頁(yè),共1.5萬(wàn)余詞,涵蓋297篇文獻(xiàn),全面研究了圖像編輯的各種前沿方法。
同時(shí),作者還提出了全新的benchmark,為研究者提供了便捷的學(xué)習(xí)參考工具。

在這份綜述中,作者從理論和實(shí)踐層面,詳盡總結(jié)了使用擴(kuò)散模型進(jìn)行圖像編輯的現(xiàn)有方法。
作者從學(xué)習(xí)策略、輸入條件等多個(gè)角度對(duì)相關(guān)成果進(jìn)行分類(lèi),并展開(kāi)了深入分析。
為了進(jìn)一步評(píng)估模型性能,作者還提出了一個(gè)測(cè)評(píng)基準(zhǔn),并展望了未來(lái)研究的一些潛在方向。

△基于擴(kuò)散模型的圖像編輯成果速覽
下面,作者將從任務(wù)分類(lèi)、實(shí)現(xiàn)方式、測(cè)試基準(zhǔn)和未來(lái)展望四個(gè)方面介紹基于擴(kuò)散模型的圖像編輯成果。
圖像編輯的分類(lèi)
除了在圖像生成、恢復(fù)和增強(qiáng)方面取得的重大進(jìn)步外,擴(kuò)散模型在圖像編輯方面也實(shí)現(xiàn)了顯著突破,相比之前占主導(dǎo)地位的生成對(duì)抗網(wǎng)絡(luò)(GANs),前者具有更強(qiáng)的可控性。
不同于“從零開(kāi)始”的圖像生成,以及旨在修復(fù)模糊圖像、提高質(zhì)量的圖像恢復(fù)和增強(qiáng),圖像編輯涉及對(duì)現(xiàn)有圖像外觀、結(jié)構(gòu)或內(nèi)容的修改,包括添加對(duì)象、替換背景和改變紋理等任務(wù)。
在這項(xiàng)調(diào)查中,作者根據(jù)學(xué)習(xí)策略將圖像編輯論文分為三個(gè)主要組別:基于訓(xùn)練的方法、測(cè)試時(shí)微調(diào)方法和無(wú)需訓(xùn)練和微調(diào)的方法。
此外,作者還探討了控制編輯過(guò)程使用的10種輸入條件,包括文本、掩碼、參考圖像、類(lèi)別、布局、姿勢(shì)、草圖、分割圖、音頻和拖動(dòng)點(diǎn)。
進(jìn)一步地,作者調(diào)查了這些方法可以完成的12種最常見(jiàn)的編輯類(lèi)型,它們被組織成以下三個(gè)廣泛的類(lèi)別:
- 語(yǔ)義編輯:此類(lèi)別包括對(duì)圖像內(nèi)容和敘述的更改,影響所描繪場(chǎng)景的故事、背景或主題元素。這一類(lèi)別內(nèi)的任務(wù)包括對(duì)象添加、對(duì)象移除、對(duì)象替換、背景更改和情感表達(dá)修改。
- 風(fēng)格編輯:此類(lèi)別側(cè)重于增強(qiáng)或轉(zhuǎn)換圖像的視覺(jué)風(fēng)格和審美元素,而不改變其敘述內(nèi)容。這一類(lèi)別內(nèi)的任務(wù)包括顏色更改、紋理更改和整體風(fēng)格更改,涵蓋藝術(shù)性和現(xiàn)實(shí)性風(fēng)格。
- 結(jié)構(gòu)編輯:此類(lèi)別涉及圖像內(nèi)元素的空間布局、定位、視角和特征的變化,強(qiáng)調(diào)場(chǎng)景內(nèi)對(duì)象的組織和展示。這一類(lèi)別內(nèi)的任務(wù)包括對(duì)象移動(dòng)、對(duì)象大小和形狀更改、對(duì)象動(dòng)作和姿勢(shì)更改以及視角/視點(diǎn)更改。
圖像編輯的實(shí)現(xiàn)方式
基于訓(xùn)練的方法
在基于擴(kuò)散模型的圖像編輯領(lǐng)域,基于訓(xùn)練的方法已經(jīng)獲得了顯著的突出地位。
這些方法不僅因其穩(wěn)定的擴(kuò)散模型訓(xùn)練和有效的數(shù)據(jù)分布建模而著名,而且在各種編輯任務(wù)中表現(xiàn)可靠。
為了徹底分析這些方法,作者根據(jù)它們的應(yīng)用范圍、訓(xùn)練所需條件和監(jiān)督類(lèi)型將它們分類(lèi)為四個(gè)主要組別。
根據(jù)核心編輯方法,這些主要組別中的方法又可以細(xì)分為不同的類(lèi)型。

下圖展示了兩種有代表性的CLIP指導(dǎo)方法——DiffusionCLIP和Asyrp的框架圖。

△樣本圖像來(lái)自CelebA數(shù)據(jù)集上的Asyrp
下面的圖片,展示的是指令圖像編輯方法的通用框架。

△示例圖像來(lái)自InstructPix2Pix、InstructAny2Pix和MagicBrush。
測(cè)試時(shí)微調(diào)的方法
在圖像生成和編輯中,還會(huì)采用微調(diào)策略來(lái)增強(qiáng)圖像編輯能力,測(cè)試時(shí)微調(diào)帶來(lái)了精確性和可控制性的重要提升。
如下圖所示,微調(diào)方法的既包括微調(diào)整個(gè)去噪模型,也包括專(zhuān)注于特定層或嵌入。
此外,作者還討論了超網(wǎng)絡(luò)的集成和直接圖像表示優(yōu)化

下圖展示了使用不同微調(diào)組件的微調(diào)框架。

△樣本圖像來(lái)自Custom-Edit
免訓(xùn)練和微調(diào)方法
在圖像編輯領(lǐng)域,無(wú)需訓(xùn)練和微調(diào)的方法起點(diǎn)是它們快速且成本低,因?yàn)樵谡麄€(gè)編輯過(guò)程中不需要任何形式的訓(xùn)練(在數(shù)據(jù)集上)或微調(diào)(在源圖像上)。
根據(jù)它們修改的內(nèi)容,可以分為五個(gè)類(lèi)別,這些方法巧妙地利用擴(kuò)散模型內(nèi)在的原則來(lái)實(shí)現(xiàn)編輯目標(biāo)。

下圖是免訓(xùn)練方法的通用框架。

△樣本圖片來(lái)自LEDITS++
圖像inpainting(補(bǔ)全)和outpainting(外擴(kuò))
圖像補(bǔ)全和外擴(kuò)通常被視為圖像編輯的子任務(wù),可以分為兩大類(lèi)型——上下文驅(qū)動(dòng)的補(bǔ)全(上排)與多模態(tài)條件補(bǔ)全(下排)。

△樣本分別來(lái)自于Palette和Imagen Editor
全新測(cè)試基準(zhǔn)
除了分析各種方法的實(shí)現(xiàn)原理,評(píng)估這些方法在不同編輯任務(wù)中的能力也至關(guān)重要,但現(xiàn)有的圖像編輯測(cè)試標(biāo)準(zhǔn)存在局限。
例如,EditBench主要針對(duì)文本和掩碼引導(dǎo)的補(bǔ)全,但忽略了涉及全局編輯的任務(wù)(如風(fēng)格轉(zhuǎn)換);TedBench雖然擴(kuò)展了任務(wù)范圍,但缺乏詳細(xì)指導(dǎo);EditVal試圖提供更全面的任務(wù)和方法覆蓋范圍,但圖像通常分辨率低且模糊……
為了解決這些問(wèn)題,作者提出了EditEval基準(zhǔn),包括一個(gè)50張高質(zhì)量圖像的數(shù)據(jù)集,且每張圖像都附有文本提示,可以評(píng)估模型在7個(gè)常見(jiàn)編輯任務(wù)的性能。
這7種任務(wù)包括物體添加/移除/替換,以及背景、風(fēng)格和姿勢(shì)、動(dòng)作的改變。

此外,作者還提出了LMM分?jǐn)?shù),利用多模態(tài)大模型(LMMs)評(píng)估不同任務(wù)上的編輯性能,并進(jìn)行了真人用戶研究以納入主觀評(píng)估。
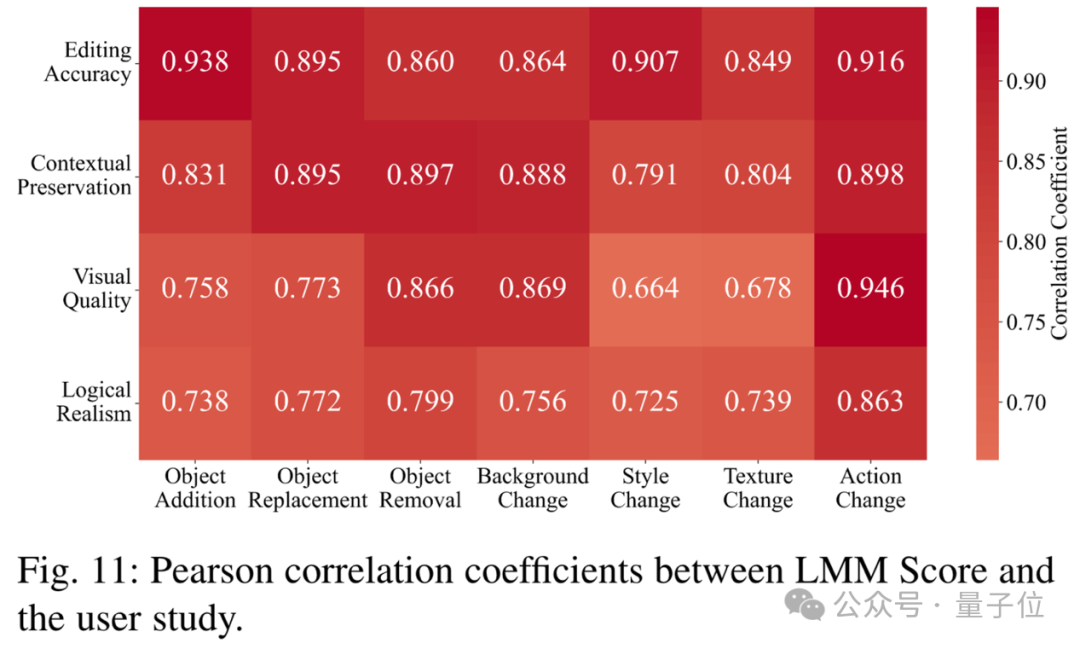
△LMM Score與用戶研究的皮爾遜相關(guān)系數(shù)
下圖比較了LMM Score/CLIPScore與用戶研究的皮爾遜相關(guān)系數(shù)。

挑戰(zhàn)和未來(lái)方向
作者認(rèn)為,盡管在使用擴(kuò)散模型進(jìn)行圖像編輯方面取得了成功,但仍有一些不足需要在未來(lái)的工作中加以解決。
減少模型推理步驟
大多數(shù)基于擴(kuò)散的模型在推理過(guò)程中需要大量的步驟來(lái)獲取最終圖像,這既耗時(shí)又耗費(fèi)計(jì)算資源,給模型部署和用戶體驗(yàn)帶來(lái)挑戰(zhàn)。
為了提高推理效率,已經(jīng)由團(tuán)隊(duì)研究了少步驟或一步生成的擴(kuò)散模型。
近期的方法通過(guò)從預(yù)訓(xùn)練的強(qiáng)擴(kuò)散模型中提取知識(shí)來(lái)減少步驟數(shù),以便少步驟模型能夠模仿強(qiáng)模型的行為。
一個(gè)更具挑戰(zhàn)性的方向是直接開(kāi)發(fā)少步驟模型,而不依賴(lài)于預(yù)訓(xùn)練的模型(例如一致性模型)。
提高模型效率
訓(xùn)練一個(gè)能夠生成逼真結(jié)果的擴(kuò)散模型在計(jì)算上是密集的,需要大量的高質(zhì)量數(shù)據(jù)。
這種復(fù)雜性使得開(kāi)發(fā)用于圖像編輯的擴(kuò)散模型非常具有挑戰(zhàn)性。
為了降低訓(xùn)練成本,近期的工作設(shè)計(jì)了更高效的網(wǎng)絡(luò)架構(gòu)作為擴(kuò)散模型的骨干。
此外,另一個(gè)重要方向是只訓(xùn)練部分參數(shù),或者凍結(jié)原始參數(shù)并在預(yù)訓(xùn)練的擴(kuò)散模型之上添加一些新層。
復(fù)雜對(duì)象結(jié)構(gòu)編輯
現(xiàn)有的工作可以在編輯圖像時(shí)合成逼真的顏色、風(fēng)格或紋理,但處理復(fù)雜結(jié)構(gòu)時(shí)仍然會(huì)產(chǎn)生明顯的修改痕跡,例如手指、標(biāo)志和文字。
研究者已經(jīng)在嘗試解決這些問(wèn)題,常用的策略是把“六個(gè)手指”等常見(jiàn)問(wèn)題作為負(fù)面提示,以使模型避免生成此類(lèi)圖像,這在某些情況下是有效的,但不夠穩(wěn)健。
近期的工作中,已有團(tuán)隊(duì)開(kāi)始使用布局、邊緣或密集標(biāo)簽作為指導(dǎo),編輯圖像的全局或局部結(jié)構(gòu)。
復(fù)雜的光照和陰影編輯
編輯對(duì)象的光照或陰影仍然是一個(gè)挑戰(zhàn),因?yàn)檫@需要準(zhǔn)確估計(jì)場(chǎng)景中的光照條件。
以前的工作(如Total Relighting)使用網(wǎng)絡(luò)組合來(lái)估計(jì)前景對(duì)象的法線、反照率和陰影,以獲得逼真的重新照明效果。
最近,也由有團(tuán)隊(duì)提出將擴(kuò)散模型用于編輯面部的光照,ShadowDiffusion也探索了基于擴(kuò)散模型的陰影合成,可以生成合理的對(duì)象陰影。
然而,使用擴(kuò)散模型在不同背景條件下準(zhǔn)確編輯對(duì)象的陰影仍然是一個(gè)未解決的問(wèn)題。
圖像編輯模型的泛化性
現(xiàn)有基于擴(kuò)散的圖像編輯模型能夠?yàn)榻o定的一部分條件合成逼真的視覺(jué)內(nèi)容,但在許多現(xiàn)實(shí)世界場(chǎng)景中仍然會(huì)失敗。
這個(gè)問(wèn)題的根本原因在于,模型無(wú)法準(zhǔn)確地對(duì)所有可能的樣本在條件分布空間中進(jìn)行建模。
如何改進(jìn)模型以始終生成無(wú)瑕疵的內(nèi)容仍然是一個(gè)挑戰(zhàn),解決這個(gè)問(wèn)題有以下幾種思路:
首先是擴(kuò)大訓(xùn)練數(shù)據(jù)規(guī)模,以覆蓋具有挑戰(zhàn)性的場(chǎng)景,這種方式效果顯著,但成本較高,如在醫(yī)學(xué)圖像、視覺(jué)檢測(cè)等領(lǐng)域數(shù)據(jù)難以收集。
第二種方法是調(diào)整模型以接受更多條件,如結(jié)構(gòu)引導(dǎo)、3D感知引導(dǎo)和文本引導(dǎo),以實(shí)現(xiàn)更可控和確定性的內(nèi)容創(chuàng)作。
此外,還可以采用迭代細(xì)化或多階段訓(xùn)練的方式,以逐步改進(jìn)模型的初始結(jié)果。
可靠的評(píng)估指標(biāo)
對(duì)圖像編輯進(jìn)行準(zhǔn)確評(píng)估,對(duì)于確保編輯內(nèi)容與給定條件的對(duì)齊至關(guān)重要。
盡管有如FID、KID、LPIPS、CLIP得分、PSNR和SSIM等定量指標(biāo),但大多數(shù)現(xiàn)有評(píng)估工作仍然嚴(yán)重依賴(lài)于用戶研究,這既不高效也不可擴(kuò)展。
可靠的定量評(píng)估指標(biāo)仍然是一個(gè)待解決的問(wèn)題。最近,已經(jīng)有團(tuán)隊(duì)提出了更準(zhǔn)確的指標(biāo)來(lái)量化對(duì)象的感知相似性。
DreamSim測(cè)量了兩幅圖像的中等級(jí)別相似性,考慮了布局、姿態(tài)和語(yǔ)義內(nèi)容,并且優(yōu)于LPIPS。
類(lèi)似的,前景特征平均(FFA)也是一種簡(jiǎn)單而有效的方法,可被用于測(cè)量對(duì)象的相似性。
另外,作者在本文中提出了的LMM score,也是一種有效的圖像編輯度量。
更多有關(guān)用于圖像編輯的擴(kuò)散模型的詳細(xì)信息,可以閱讀原作,同時(shí)作者也在GitHub上發(fā)布了附帶資源庫(kù)。
論文鏈接:https://arxiv.org/abs/2402.17525
Github:https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods