













大模型的DenseNet時(shí)刻!DenseMamba:精度顯著提升
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
隨著 ChatGPT 的突破性進(jìn)展,大型語言模型(LLMs)迎來了一個(gè)嶄新的里程碑。這些模型在語言理解、對(duì)話交互和邏輯推理方面展現(xiàn)了卓越的性能。過去一年,人們目睹了 LLaMA、ChatGLM 等模型的誕生,它們基于 Transformer 架構(gòu),采用多頭自注意力(MHSA)機(jī)制來捕捉詞匯間的復(fù)雜關(guān)系,盡管 MHSA 模塊在模型中扮演著核心角色,但其在推理過程中對(duì)計(jì)算和內(nèi)存資源的需求卻極為龐大。具體來說,對(duì)于長度為 N 的輸入句子,自注意力的計(jì)算復(fù)雜度高達(dá) O (N^2),而內(nèi)存占用則達(dá)到了 O (N^2D),其中 D 是模型的維度。
為了應(yīng)對(duì)這一挑戰(zhàn),最新的研究致力于簡化 Transformer 架構(gòu),以降低其在計(jì)算和空間上的復(fù)雜度。研究者們探索了多種創(chuàng)新方法,包括卷積語言模型、循環(huán)單元、長上下文模型,以及狀態(tài)空間模型(SSMs)。這些新興技術(shù)為構(gòu)建高效能的 LLMs 提供了強(qiáng)有力的替代方案。SSMs 通過引入高效的隱藏狀態(tài)機(jī)制,有效處理長距離依賴問題,同時(shí)保持了訓(xùn)練的并行性和推理的高效率。隱藏狀態(tài)能夠在時(shí)間維度上傳遞信息,減少了在每一步中訪問歷史詞匯的計(jì)算負(fù)擔(dān)。通過狀態(tài)轉(zhuǎn)移參數(shù) A,隱藏狀態(tài)能夠?qū)⑶耙粫r(shí)間步的信息傳遞至當(dāng)前時(shí)間步,實(shí)現(xiàn)對(duì)下一個(gè)詞匯的自回歸預(yù)測。
盡管隱藏狀態(tài)在 SSMs 中起著至關(guān)重要的作用,但其在以往的研究中并未得到充分研究。不同層的權(quán)重和隱藏特征包含了從細(xì)粒度到粗粒度的多層次信息。然而,在早期的 SSMs 版本中,隱藏狀態(tài)僅在當(dāng)前層內(nèi)流動(dòng),限制了其傳遞更深層信息的能力,從而影響了模型捕獲豐富層次信息的能力。
為了解決這個(gè)挑戰(zhàn),華為諾亞方舟實(shí)驗(yàn)室的科研團(tuán)隊(duì)發(fā)表了新工作《DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models》, 提出一個(gè)適用于各類 SSM 模型例如 Mamba 和 RetNet 的 DenseSSM 方法,該方法有選擇地將淺層隱藏狀態(tài)整合到深層,保留了對(duì)最終輸出至關(guān)重要的淺層細(xì)粒度信息,以增強(qiáng)深層感知原始文本信息的能力。

論文鏈接:https://arxiv.org/abs/2403.00818
項(xiàng)目主頁:https://github.com/WailordHe/DenseSSM
文章首先分析了狀態(tài)空間模型(SSMs)中的隱藏狀態(tài)退化問題,
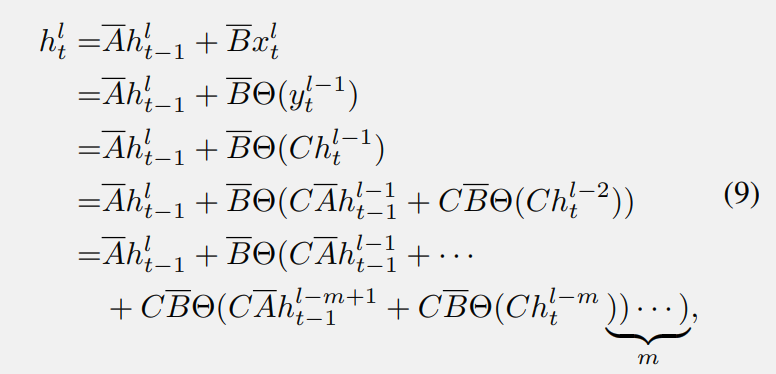
上標(biāo) “l(fā)” 表示第 l 個(gè)塊。其中,Θ(·) 是從 SSM 模塊的最后一個(gè)輸出到輸入的轉(zhuǎn)換,例如卷積和前饋網(wǎng)絡(luò)(FFN)。從公式 (7) 可以看出,從第 (l-m) 層到第 l 層的隱藏信息傳遞需要經(jīng)過 m 個(gè)變換塊和 m 次 BC 矩陣乘法。這樣復(fù)雜的計(jì)算過程可能導(dǎo)致顯著的信息丟失,這意味著在第 l 層嘗試檢索淺層的某些信息變得非常困難和不清晰。
方法
密集(Dense)隱藏層連接
在上述分析中發(fā)現(xiàn)隨著層深度的增加,SSM 中重要隱藏狀態(tài)的衰減。因此,DenseSSM 提出了一種密集連接的隱藏狀態(tài)方法,以更好地保留來自淺層的細(xì)粒度信息,增強(qiáng)深層感知原始文本信息的能力。對(duì)于第 l 個(gè)塊,DenseSSM 在其前 m 個(gè)塊中密集連接隱藏狀態(tài)。
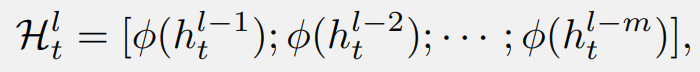
首先,收集淺層隱藏狀態(tài),并引入一個(gè)選擇性轉(zhuǎn)換模塊 φ,同時(shí)將它們投影到目標(biāo)層的子空間并選擇有用的部分:
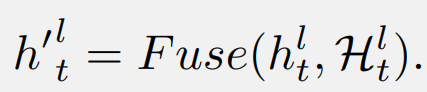
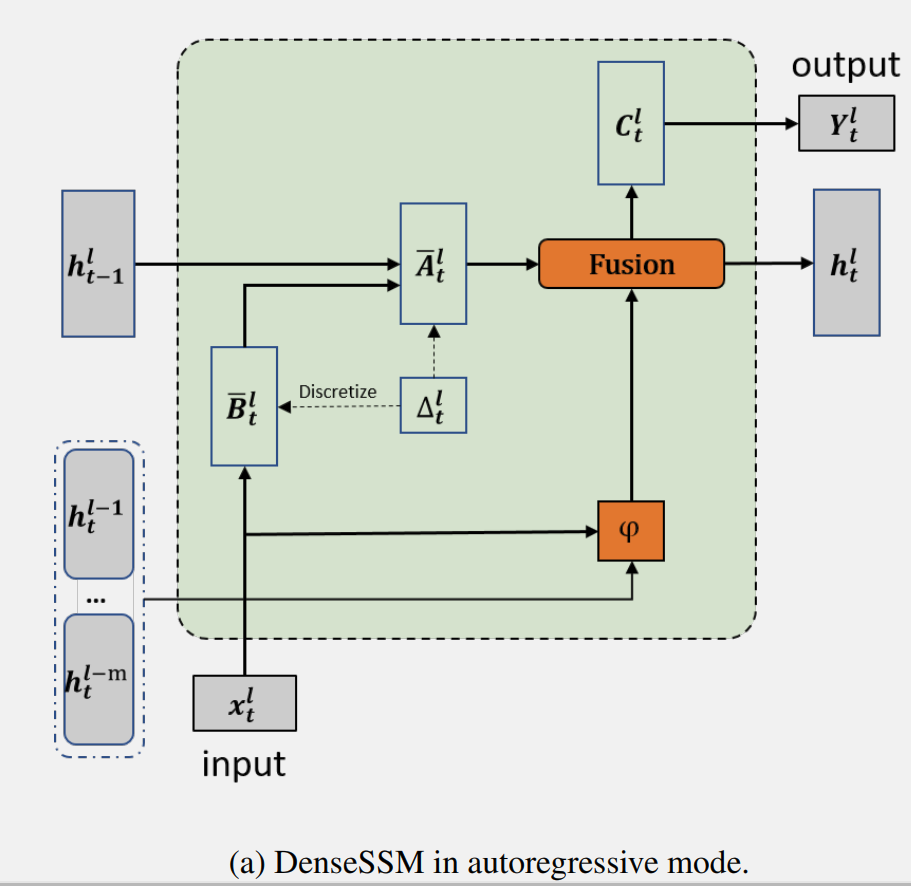
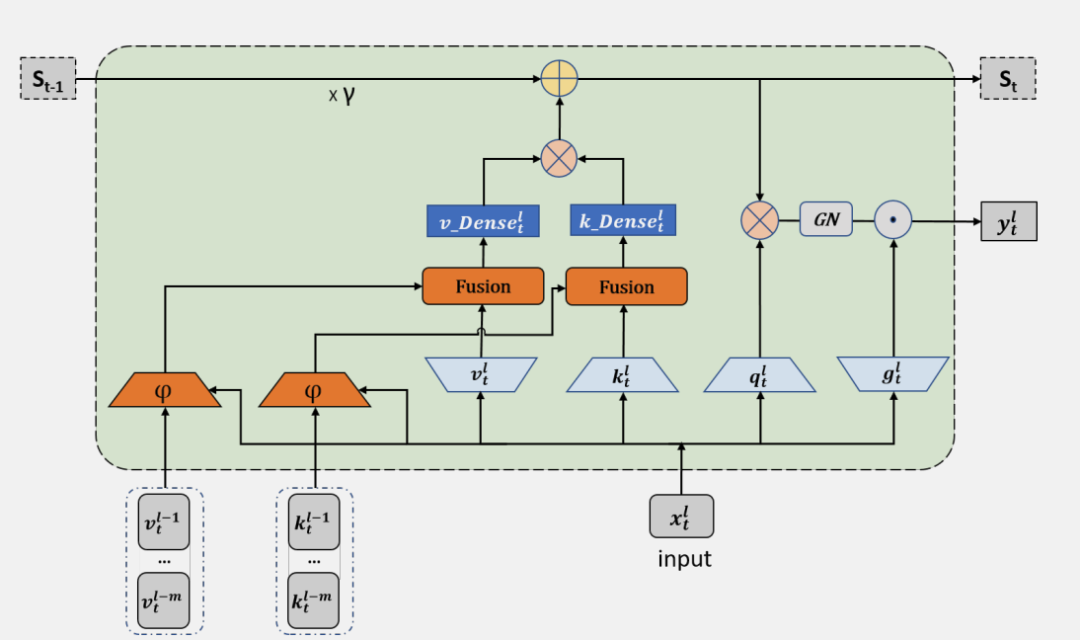
操作 Fuse ( 是融合中間隱藏向量和當(dāng)前隱藏狀態(tài)的函數(shù)。具有所提出的密集隱藏層連接的 SSM 被稱為 DenseSSM,下圖為遞歸模式的 DenseSSM 示例。
DenseSSM 也可以基于卷積模式以實(shí)現(xiàn)高效訓(xùn)練。根據(jù)狀態(tài)空間模型(SSM)的公式 可以得到:
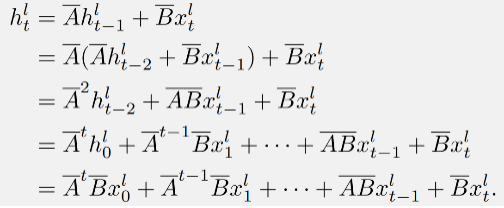
這個(gè)過程可以通過對(duì)輸入序列 進(jìn)行卷積來實(shí)現(xiàn):
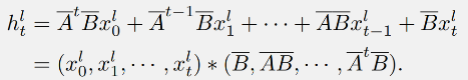
在文章所提出的 DenseSSM 中,可以獲得隱藏狀態(tài)加強(qiáng)的 SSM 的輸出:
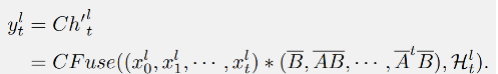
DenseSSM 方法的并行實(shí)現(xiàn)示例圖:
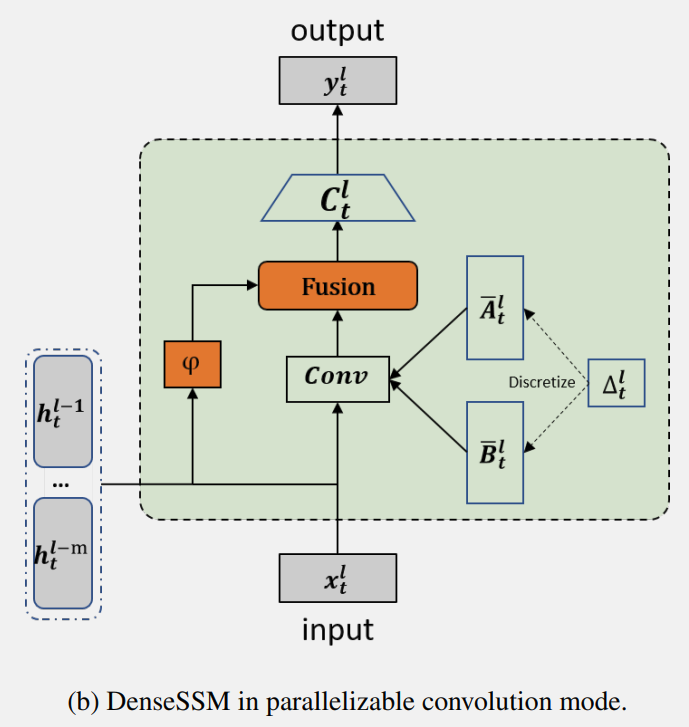
Selective Transition Module (選擇性轉(zhuǎn)換模塊)
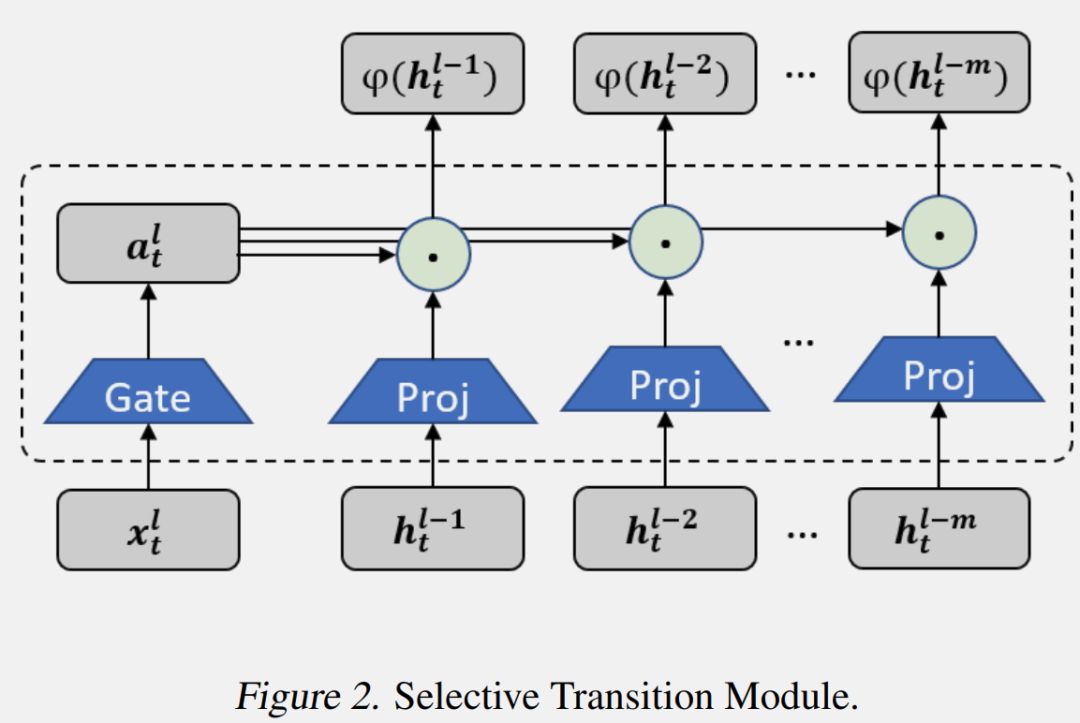
選擇性轉(zhuǎn)換模塊 φ(·) 的目的是將輸入投影到目標(biāo)子空間,并同時(shí)選擇隱藏信息的有用部分。通過投影層和門控選擇機(jī)制實(shí)現(xiàn)了選擇性轉(zhuǎn)換模塊,如上圖所示。首先,前 m 個(gè) SSM 塊中的隱藏狀態(tài)會(huì)被投影到相同的空間:

然后,根據(jù)輸入 生成門控權(quán)重,并使用它們來選擇有用的隱藏狀態(tài):
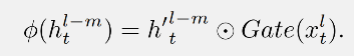
在實(shí)踐中作者保持了簡單且高效的實(shí)現(xiàn)。投影層使用線性變換實(shí)現(xiàn),而門控模塊則使用參數(shù)高效的帶有激活函數(shù)的兩層 MLP。
Hidden Fusion Module (隱藏層融合模塊)
選擇性轉(zhuǎn)換模塊后從淺層獲得了選擇的隱藏狀態(tài),即 后, DenseSSM 方法利用一個(gè)隱藏融合模塊將這些精選的淺層隱藏狀態(tài)與當(dāng)前層的隱藏狀態(tài)結(jié)合起來。由于這些精選狀態(tài)已經(jīng)被投影到相同的空間,因此可以簡單地將它們累加到當(dāng)前層的隱藏狀態(tài)上:
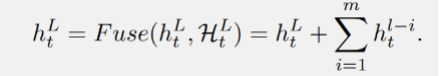
為了保持模型的高效性,其他可能的實(shí)現(xiàn)方式,例如拼接和交叉注意力機(jī)制沒有被使用。
擴(kuò)展到 RetNet
RetNet 可以被視為一種狀態(tài)空間模型,它利用線性注意力來簡化自注意力的計(jì)算復(fù)雜度。與標(biāo)準(zhǔn) Transformer 相比具有快速推理和并行化訓(xùn)練兼得的優(yōu)勢。
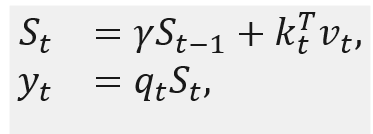
其中, 是循環(huán)狀態(tài), RetNet 的密集 連接執(zhí)行方式如下。首先,淺層的 和 被連接起來:
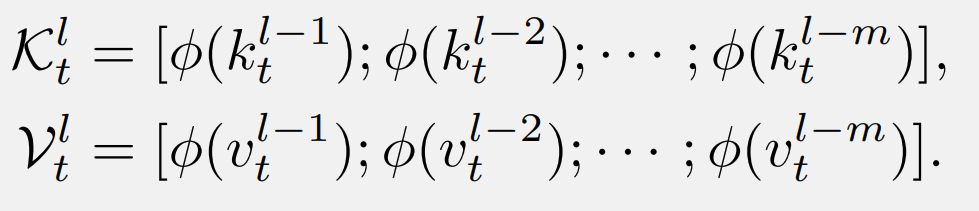
然后,這些 K 和 V 被注入到當(dāng)前層的原始鍵(或值)中:
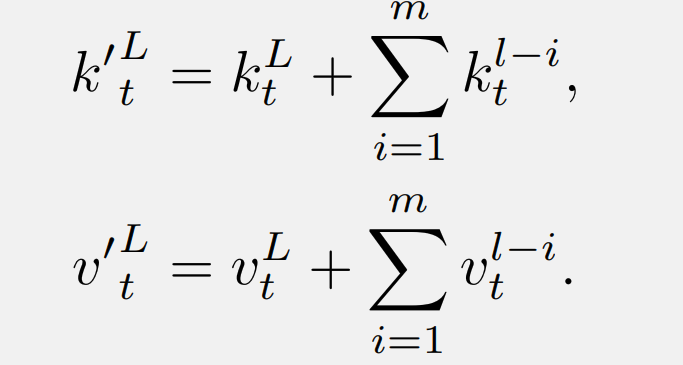
配備了使用所提出 DenseSSM 方法的密集鍵值(KV)連接的 RetNet 被稱為 DenseRetNet,如下圖所示。
此外,DenseRetNet 也可以在并行模式下實(shí)現(xiàn),也就是說,可以在 GPU 或 NPU 上并行訓(xùn)練。DenseRetNet 的并行模式公式如下:
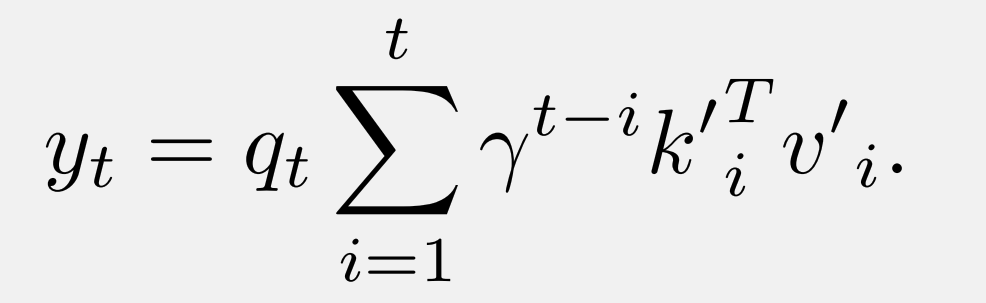
實(shí)驗(yàn)
文章進(jìn)行了全面的實(shí)驗(yàn),以驗(yàn)證所提出的 DenseSSM 的有效性。這些實(shí)驗(yàn)在不同的架構(gòu)上進(jìn)行,包括 RetNet 和 Mamba。
預(yù)訓(xùn)練數(shù)據(jù)
在實(shí)驗(yàn)中,選擇了 The Pile 數(shù)據(jù)集的一個(gè)子集,并從頭開始訓(xùn)練所有模型。為了確保訓(xùn)練集包含 150 億(15B)個(gè) tokens,對(duì)數(shù)據(jù)集進(jìn)行了隨機(jī)抽樣。在所有實(shí)驗(yàn)中,統(tǒng)一使用了 LLaMA 分詞器來處理這些數(shù)據(jù)。
評(píng)估數(shù)據(jù)集
在評(píng)估模型性能時(shí),特別關(guān)注了模型在多種下游任務(wù)上的零樣本和少樣本學(xué)習(xí)能力。這些任務(wù)包括了一系列測試常識(shí)推理和問答的數(shù)據(jù)集,例如 HellaSwag、BoolQ、COPA、PIQA、Winograd、Winogrande、StoryCloze、OpenBookQA、SciQ、ARC-easy 和 ARC-challenge。此外,文章還報(bào)告了 WikiText 和 LAMBADA 的詞困惑度指標(biāo)。所有評(píng)估都通過使用 LM evaluation harness 標(biāo)準(zhǔn)化的評(píng)估工具進(jìn)行,以確保評(píng)估模型能力的一致性。
實(shí)驗(yàn)設(shè)置
為了驗(yàn)證提出的 DenseSSM 機(jī)制的有效性,選擇了 350M 和 1.3B 兩種模型規(guī)格進(jìn)行實(shí)驗(yàn)。所有模型都是從頭開始訓(xùn)練的,并進(jìn)行了一個(gè) Epoch 的訓(xùn)練,共使用了 1.5B tokens。訓(xùn)練時(shí),設(shè)置訓(xùn)練的 batch size 為 0.5M,序列長度為 2048 個(gè) token。訓(xùn)練過程中使用了 AdamW 優(yōu)化器,并采用了多項(xiàng)式學(xué)習(xí)率衰減,warm-up 比例設(shè)置為總訓(xùn)練步數(shù)的 1.5%。權(quán)重衰減設(shè)置為 0.01,梯度裁剪設(shè)置為 1。
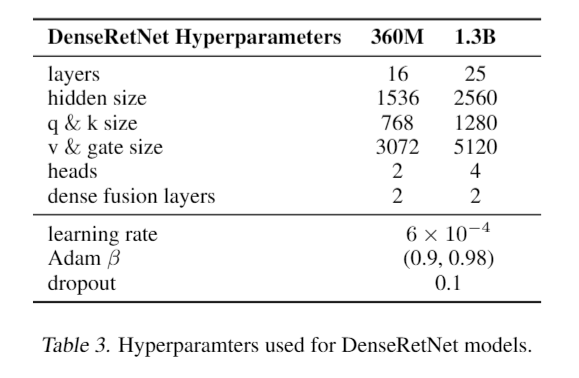
DenseRetNet 的實(shí)驗(yàn)
DenseRetNet 模型的大小和超參數(shù)設(shè)置詳細(xì)列出如下。此外,DenseRetNet 模型中還進(jìn)一步集成了全局注意力單元(GAU)。GAU 將注意力機(jī)制與前饋網(wǎng)絡(luò)(FFN)塊結(jié)合為一個(gè)單元,這使得模型能夠同時(shí)進(jìn)行通道混合和 token 混合。與原始的 GAU 不同,多頭機(jī)制仍然被采用以實(shí)現(xiàn)多尺度的指數(shù)衰減,這種設(shè)計(jì)旨在提高模型對(duì)不同尺度特征的捕捉能力,從而提升性能。
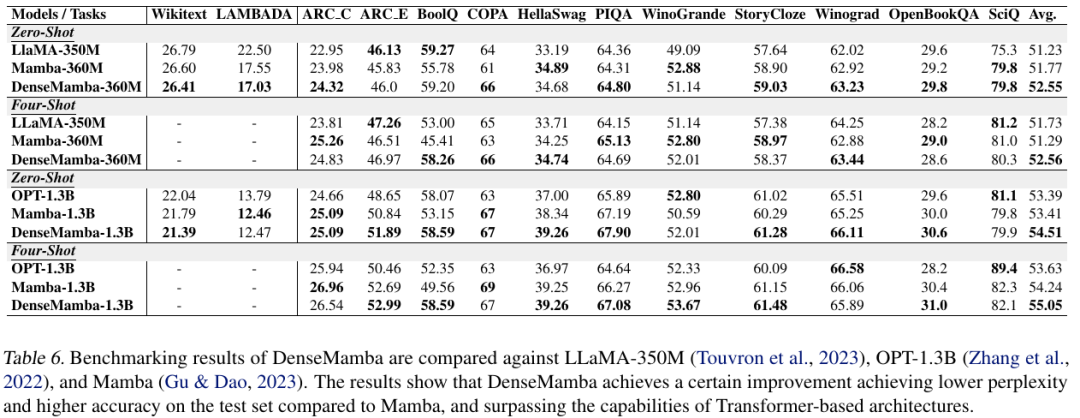
在通用語料庫以及包括常識(shí)推理和問答在內(nèi)的多種下游任務(wù)上,對(duì) DenseRetNet 模型進(jìn)行了評(píng)估。實(shí)驗(yàn)結(jié)果的比較表格顯示,DenseRetNet 模型在 Wikitext 和 LAMBADA 語料庫上取得了更低的困惑度。此外,在零樣本和少樣本設(shè)置的下游任務(wù)中,DenseRetNet 表現(xiàn)出了顯著的優(yōu)勢。與 RetNet 相比,DenseRetNet 顯著提升了性能,并且在與基于 Transformer 的語言模型的比較中,實(shí)現(xiàn)了更優(yōu)越的性能表現(xiàn)。這些結(jié)果表明,DenseRetNet 在處理自然語言處理任務(wù)時(shí),具有強(qiáng)大的能力和潛力。
DenseMamba 的實(shí)驗(yàn)
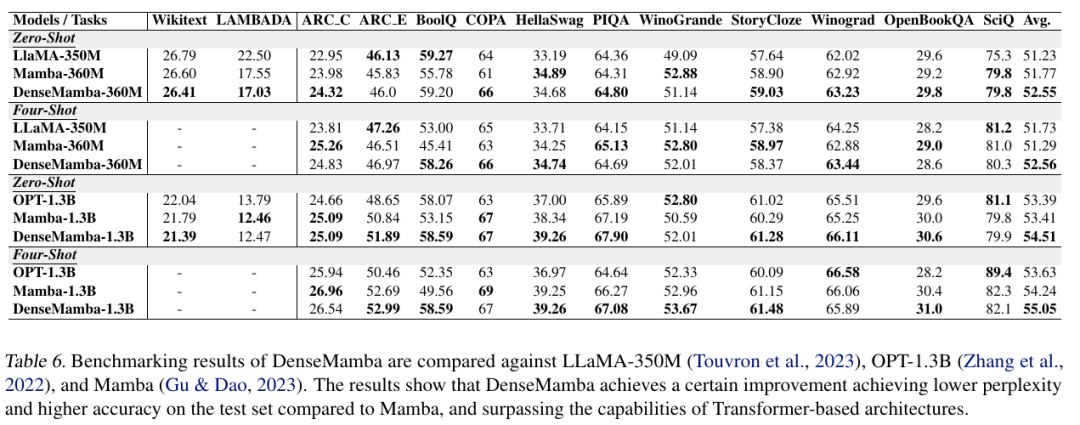
下表詳細(xì)列出了 DenseMamba 模型的參數(shù)設(shè)置。由于 DenseMamba 使用的分詞器相比于 Mamba 模型中使用的 GPT-NeoX 分詞器規(guī)模較小,為了使參數(shù)數(shù)量相匹配,作者在模型中增加了兩層。除此之外,模型結(jié)構(gòu)和其他訓(xùn)練設(shè)置均遵循了 Mamba 論文中的描述。具體而言,對(duì)于 360M 參數(shù)的模型,學(xué)習(xí)率被設(shè)定為 3e-4;對(duì)于 1.3B 參數(shù)的模型,學(xué)習(xí)率被設(shè)定為 2e-4。在這兩種情況下,均沒有采用 dropout 技術(shù)。

下表比較了 DenseMamba 與相對(duì)應(yīng)模型的性能。DenseMamba 在測試集上表現(xiàn)出卓越的困惑度和準(zhǔn)確性,優(yōu)于 Mamba 和其他基于 Transformer 的模型。
總結(jié)
文章提出了一個(gè)新的框架 ——DenseSSM(密集狀態(tài)空間模型),旨在通過增強(qiáng)隱藏信息在不同層之間的流動(dòng)來提升狀態(tài)空間模型(SSM)的性能。在 SSM 中,隱藏狀態(tài)是存儲(chǔ)關(guān)鍵信息的核心單元,更有效地利用這些狀態(tài)對(duì)于模型的基本功能至關(guān)重要。為了實(shí)現(xiàn)這一目標(biāo),作者提出了一種方法,即從淺層收集隱藏狀態(tài),并將它們有選擇性地融合到深層的隱藏狀態(tài)中,這樣可以增強(qiáng) SSM 對(duì)文本低層信息的感知能力。
DenseSSM 方法的設(shè)計(jì)考慮到了保持 SSM 原有的優(yōu)點(diǎn),如高效的自回歸推理能力和高效的并行訓(xùn)練特性。通過將 DenseSSM 方法應(yīng)用于流行的架構(gòu),例如 RetNet 和 Mamba,作者成功地創(chuàng)造了具有更強(qiáng)大的基礎(chǔ)語言處理能力的新架構(gòu)。這些新架構(gòu)在公共基準(zhǔn)測試中表現(xiàn)出了更高的準(zhǔn)確性,證明了 DenseSSM 方法的有效性。


























