













譯者 | 朱先忠
審校 | 重樓

在樹莓派上使用Ollama的本地LLM和VLM(作者本人提供照片)
前言
有沒有想過在自己的設備上運行自己的大型語言模型(LLM)或視覺語言模型(VLM)?你可能想過,但一想到從頭開始設置,必須管理有關環境,還要下載正確的模型權重,以及帶有對你的設備是否能夠處理模型的揮之不去的懷疑,你可能會停了下來。
讓我們更進一步想象一下:在一個不比信用卡大的設備上操作你自己的LLM或VLM——一個樹莓派。可能嗎?根本不可能。然而,畢竟我正在寫這篇文章,所以告訴你我的針對上述問題的回答應該是:絕對可能!
你為什么要這么做?
就現時段來看,在邊緣設備上部署與運行LLM似乎相當牽強。但隨著時間的推移,這種特定的場景應用肯定會越來越成熟,我們會看到一些很酷的邊緣解決方案將被部署到各類邊緣設備上,并以全本地化方式運行生成的人工智能解決方案。
我們這樣做的另一個理由是關于突破極限的設想,想看看什么是可能的。如果它可以在某個極端配置的計算規模下完成,那么它肯定可以在樹莓派和更強大的服務器GPU之間的任何級別配置的設置上完成。
從傳統技術上來看,邊緣人工智能與計算機視覺就存在密切的關系。因此,探索LLM和VLM在邊緣設備上的部署也為這個剛剛出現的領域增加了一個令人興奮的維度。
最重要的是,我只是想用我最近購買的樹莓派5做一些有趣的事情。
那么,我們如何在樹莓派上實現這一切呢?回答是:使用Ollama!
Ollama是什么?
Ollama(https://ollama.ai/)已成為在你自己的個人計算機上運行本地LLM的最佳解決方案之一,而無需處理從頭開始設置的麻煩。只需幾個命令,就可以毫無問題地設置所有內容。一切都是獨立的,根據我的經驗,在幾種設備和模型上都能很好地工作。它甚至公開了一個用于模型推理的REST API;因此,你可以讓它在Raspberry Pi上運行,如果你愿意,還可以從其他應用程序和設備上調用該API。
還有Ollama Web UI這一漂亮的AI UI/UX,對于那些擔心命令行界面的人來說,它能夠與Ollama以無縫結合方式運行。如果你愿意使用的話,它基本上就是一個本地ChatGPT接口。
這兩款開源軟件一起提供了我認為是目前最好的本地托管LLM體驗。
Ollama和Ollama Web UI都支持類似于LLaVA這樣的VLM,這些技術為邊緣生成AI使用場景打開了更多的大門。
技術要求
你只需要以下內容:
- Raspberry Pi 5(或4,設置速度較慢)-選擇8GB RAM或以上大小以適合7B模型。
- SD卡——最小16GB,尺寸越大,可以容納的模型越多。還應安裝合適的操作系統,如Raspbian Bookworm或Ubuntu。
- 連接互聯網。
正如我之前提到的,在Raspberry Pi上運行Ollama已經接近硬件領域的極限。從本質上講,任何比樹莓派更強大的設備,只要運行Linux發行版并具有類似的內存容量,理論上都應該能夠運行Ollama和本文討論的模型。
1.安裝Ollama
要在樹莓派上安裝Ollama,我們將避免使用Docker以便節省資源。
首先,在終端中,運行如下命令:
curl https://ollama.ai/install.sh | sh運行上面的命令后,你應該會看到與下圖類似的內容。
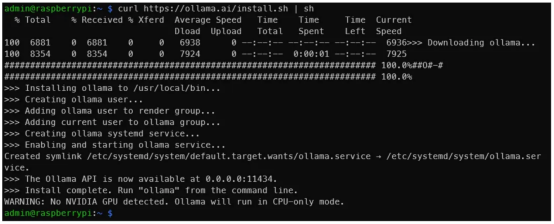 作者本人提供照片
作者本人提供照片
如輸出所示,導航到地址0.0.0.0:11434可以驗證Ollama是否正在運行。期間,看到“警告:未檢測到NVIDIA GPU(WARNING: No NVIDIA GPU detected)”是正常的。Ollama將在僅CPU模式下運行,因為我們使用的是樹莓派。但是,如果你在應該有NVIDIA GPU的機器上遵循上圖中的這些說明操作的話,你就會發現有些情況不對勁。
有關任何問題或更新,請參閱Ollama GitHub存儲庫。
2.通過命令行運行LLM
建議你查看一下官方Ollama模型庫,以便了解可以使用Ollama運行的模型列表。在8GB的樹莓派上,大于7B的模型不適合。讓我們使用Phi-2,這是一個來自微軟的2.7B LLM,現在已獲得麻省理工學院的許可。
我們將使用默認的Phi-2模型,但可以隨意使用鏈接https://ollama.ai/library/phi/tags處提供的任何其他標簽。請你看看Phi-2的模型頁面,看看如何與它交互。
現在,請在終端中,運行如下命令:
ollama run phi一旦你看到類似于下面的輸出,說明你已經在樹莓派上運行了LLM!就這么簡單。
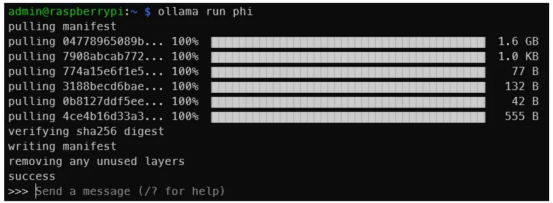 圖片來源:作者本人
圖片來源:作者本人

這是一個與Phi-2 2.7B的交互。顯然,你不會得到與此相同的輸出,但是你明白了其中的道理(作者本人圖片)
你還可以嘗試一下其他模型,如Mistral、Llama-2等,只需確保SD卡上有足夠的空間放置模型權值即可。
模型越大,輸出就越慢。在Phi-2 2.7B上,我每秒可以獲得大約4個標記。但使用Mistral 7B,生成速度會降至每秒2個標記左右。一個標記大致相當于一個單詞。
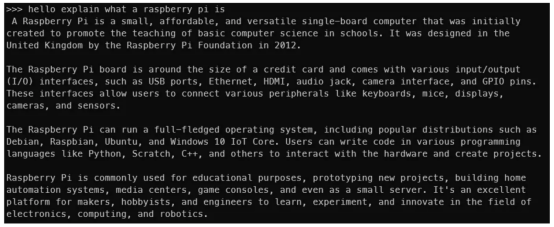 這是與Mistral 7B的互動結果(作者本人圖片)
這是與Mistral 7B的互動結果(作者本人圖片)
現在,我們已經讓LLM在樹莓派上運行起來了,但我們還沒有完成任務。這種終端方式并不是每個人都適合的。下面,讓我們讓Ollama Web UI也運行起來!
3.安裝和運行Ollama Web UI
我們將按照官方Ollama Web UI GitHub存儲庫上的說明在沒有Docker的情況下進行安裝。它建議Node.js版本的最小值為>=20.10,因此我們將遵循這一點。它還建議Python版本至少為3.11,但Raspbian操作系統已經為我們安裝好了。
我們必須先安裝Node.js。為此,在終端中,運行如下命令:
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - &&\
sudo apt-get install -y nodejs如果本文以后的讀者需要,請將20.x更改為更合適的版本。
然后,運行下面的代碼塊。
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui/
#復制所需的.env文件
cp -RPp example.env .env
#使用Node構建前端
npm i
npm run build
#用后端服務前端
cd ./backend
pip install -r requirements.txt --break-system-packages
sh start.sh上述命令行代碼是對GitHub上提供的內容的輕微修改。請注意,為了簡潔起見,我們沒有遵循最佳實踐,如使用虛擬環境,而是使用break-system-packages標志。如果遇到類似未找到uvicorn包的錯誤提示,請重新啟動終端會話。
如果一切正常,你應該能夠在Raspberry Pi上通過http://0.0.0.0:8080的端口8080訪問Ollama Web UI,或者如果你通過同一網絡上的另一個設備訪問,則可以通過地址http://<Raspberrry Pi的本機地址>:8080/進行訪問。
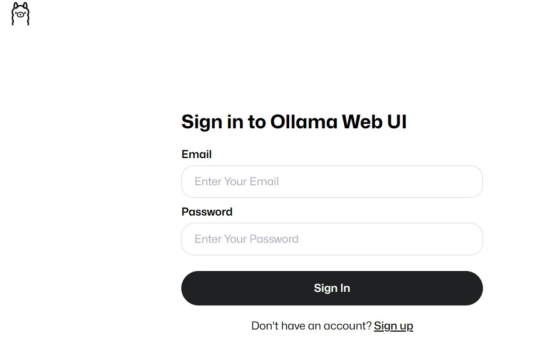 如果你看到了這一點,說明上面運行代碼成功(作者本人照片)
如果你看到了這一點,說明上面運行代碼成功(作者本人照片)
然后,在創建帳戶并登錄后,你應該會看到與下圖類似的內容。
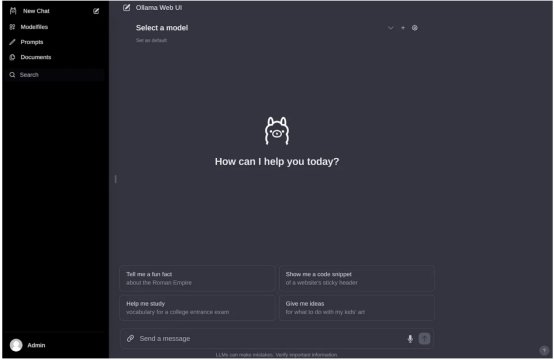 作者本人照片
作者本人照片
如果你之前下載了一些模型權重,你應該會在下拉菜單中看到它們,如下圖所示。如果沒有,可以轉到設置(Settings)頁面下載模型。
 可用模型將顯示在此處(作者本人照片)
可用模型將顯示在此處(作者本人照片)
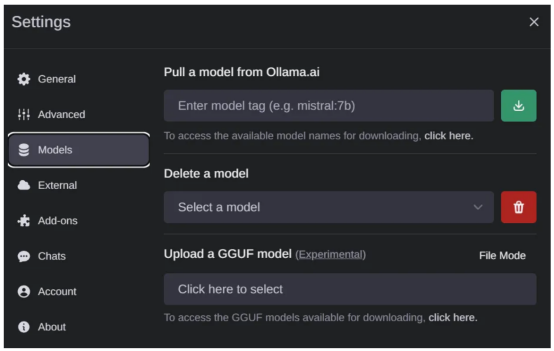
如果你想下載新的模型,請轉到“設置(Settings)”頁面的>“模型”(Models)選項中,以便從列表中通過網絡下載新的模型(作者本人照片)
整個操作界面非常干凈直觀,所以我就不多解釋了。這確實是一個做得很好的開源項目。
 此處是通過Ollama Web UI與Mistral 7B的互動(作者本人照片)
此處是通過Ollama Web UI與Mistral 7B的互動(作者本人照片)
4.通過Ollama Web UI運行VLM
正如我在本文開頭提到的,我們也可以運行VLM。讓我們運行LLaVA模型,這是一個流行的開源VLM,它恰好也得到了Ollama系統的支持。要做到這一點,請通過設置界面下載“llava”模型,以便下載對應的權重數據。
遺憾的是,與LLM不同,設置頁面需要相當長的時間才能解釋樹莓派上的圖像。下面的例子花了大約6分鐘的時間進行處理。大部分時間可能是因為事物的圖像方面還沒有得到適當的優化,但這在未來肯定會改變的。標記生成速度約為2個標記/秒。
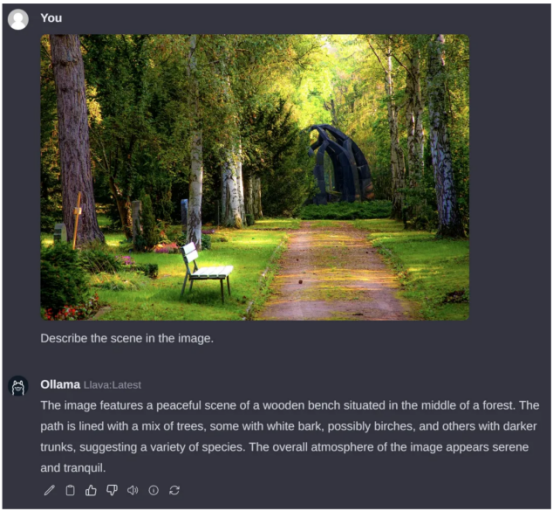 查詢圖片來源:Pexels素材網站
查詢圖片來源:Pexels素材網站
總結
至此,我們已經基本實現了本文的目標。現在來概括一下,我們已經成功地使用Ollama和Ollama Web UI在Raspberry Pi上運行起LLM和VLM模型,如Phi-2、Mistral和LLaVA等。
我可以肯定地想象,在Raspberry Pi(或其他小型邊緣設備)上運行的本地托管LLM還有很多使用場景,特別是因為如果我們選擇Phi-2大小的模型,那么對于某些場景來說,每秒4個標記似乎是可以接受的流媒體速度。
總之,“小微”LLM和VLM領域是當前一個活躍的研究領域,最近發布了相當多的模型。希望這一新興趨勢繼續下去,更高效、更緊湊的模型繼續發布!這絕對是未來幾個月需要大家關注的事情。
免責聲明:我與Ollama或Ollama Web UI沒有任何關系。所有觀點和意見都是我自己的,不代表任何組織。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Running Local LLMs and VLMs on the Raspberry Pi,作者:Pye Sone Kyaw
























