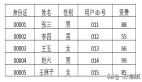
可伸縮架構案例:數據太多,如何無限擴展你的數據庫?
隨著我們業務的發展,每日的訂單量接近 100 萬。這個時候,訂單庫已有上億條記錄,訂單表有上百個字段,這些數據存儲在一個 Oracle 數據庫里。當時,我們已經實現了訂單的服務化改造,只有訂單服務才能訪問這個訂單數據庫,但隨著單量的增長以及在線促銷的常態化,單一數據庫的存儲容量和訪問性能都已經不能滿足業務需求了,訂單數據庫已成為系統的瓶頸。所以,對這個數據庫的拆分勢在必行。
數據庫拆分一般有兩種做法,一個是垂直分庫,還有一個是水平分庫。
垂直分庫簡單來說,垂直分庫就是數據庫里的表太多,我們把它們分散到多個數據庫,一般是根據業務進行劃分,把關系密切的表放在同一個數據庫里,這個改造相對比較簡單。
水平分庫某些表太大,單個數據庫存儲不下,或者數據庫的讀寫性能有壓力。通過水平分庫,我們把一張表拆成多張表,每張表存放部分記錄,分別保存在不同的數據庫里,水平分庫需要對應用做比較大的改造。
 圖片
圖片
通過水平分庫,你們將訂單的基本信息、商品明細和擴展信息分散到多個數據庫中,這樣做主要是為了解決兩個問題:一是減少了單個數據庫的數據量,從而提高了讀寫效率;二是分散了數據庫的負載,使系統能夠更好地擴展和維護。簡而言之,就是讓數據庫更快、系統運行更穩定。
水平分庫后,應用通過訂單服務來訪問多個訂單數據庫,具體的方式如下圖所示:
 圖片
圖片
原來的一個 Oracle 庫被現在的多個 MySQL 庫給取代了,每個 MySQL 數據庫包括了 1 主 1 備 2 從,都支持讀寫分離,主備之間通過自帶的同步機制來實現數據同步。所以,你可以發現,這個項目實際包含了水平分庫和去 Oracle 兩大改造目標。
分庫維度怎么定?
首先,我們需要考慮根據哪個字段來作為分庫的維度。這個字段選擇的標準是,盡量避免應用代碼和 SQL 性能受到影響。
具體地說,就是現有的 SQL 在分庫后,它的訪問盡量落在單個數據庫里,否則原來的單庫訪問就變成了多庫掃描,不但 SQL 的性能會受到影響,而且相應的代碼也需要進行改造。
具體到訂單數據庫的拆分,你可能首先會想到按照用戶 ID 來進行拆分。這個結論是沒錯,但我們最好還是要有量化的數據支持,不能拍腦袋。這里,最好的做法是,先收集所有 SQL,挑選出 WHERE 語句中最常出現的過濾字段,比如說這里有三個候選對象,分別是用戶 ID、訂單 ID 和商家 ID,每個字段在 SQL 中都會出現三種情況:
單 ID 過濾,比如說“用戶 ID=?”;
多 ID 過濾,比如“用戶 ID IN(?,?,?)”;
該 ID 不出現。
最后,我們分別統計這三個字段的使用情況,假設共有 500 個 SQL 訪問訂單庫,3 個候選字段出現的情況如下:
 圖片
圖片
從這張表格的分析來看,選擇按用戶 ID 進行分庫是顯而易見的最佳選擇。但這只是基于靜態數據的判斷。實際上,不同 SQL 的訪問頻次各不相同,因此,進一步分析每條 SQL 的實際訪問量變得至關重要。在我們的項目中,我們聚焦于執行頻率最高的前15條 SQL,它們占據了總執行次數的85%,具有很高的代表性。通過分析,如果采用用戶 ID 作為分庫的依據,發現這些 SQL 中有85% 的訪問會集中在某個特定的數據庫上,13% 的訪問分布在幾個數據庫中,僅有2% 的訪問需要查詢所有數據庫。因此,從動態的 SQL 執行頻次來看,使用用戶 ID 進行分庫顯然優于采用其他標識符。這樣的量化分析不僅證實了按用戶 ID 分庫是最優策略,而且還明確了分庫對現有系統的具體影響。例如,在本案例中,85% 的 SQL 都會被定向到同一個數據庫,這意味著相對于未分庫的狀態,這部分數據的訪問性能將得到提升,同時也消除了我們對分庫有效性的疑慮,增強了我們進行分庫的決心。
數據怎么分?
一般有兩種數據分法:根據 ID 范圍進行分庫,比如把用戶 ID 為 1 ~ 999 的記錄分到第一個庫,1000 ~ 1999 的分到第二個庫,以此類推。
根據 ID 取模進行分庫,比如把用戶 ID mod 10,余數為 0 的記錄放到第一個庫,余數為 1 的放到第二個庫,以此類推。
這兩種分法,各自存在優缺點,如下表所示:
 圖片
圖片
在實踐中,為了運維方便,選擇 ID 取模進行分庫的做法比較多。同時為了數據遷移方便,一般分庫的數量是按照倍數增加的,比如說,一開始是 4 個庫,二次分裂為 8 個,再分成 16 個。這樣對于某個庫的數據,在分裂的時候,一半數據會移到新庫,剩余的可以不用動。與此相反,如果我們每次只增加一個庫,所有記錄都要按照新的模數做調整。
分幾個庫?
確定了數據分片的方案后,接下來要解決的問題是分成多少個數據庫。數據庫能夠處理的記錄數量上限是決定因素之一。
通常情況下,當MySQL數據庫的記錄數超過5000萬,或Oracle數據庫的記錄數超過1億時,數據庫的負載會變得很高,這也取決于字段的數量、大小以及查詢的復雜性。
在保證不超過單個數據庫記錄處理上限的情況下,如果分庫太少,我們無法實現分散存儲的目的,也不能有效減輕數據庫的性能壓力;而分得太多雖然能提高單個數據庫的訪問性能,但對于需要跨多個數據庫進行的訪問操作,應用程序必須同時連接多個數據庫。并行訪問會消耗更多的線程資源,而串行訪問則會大幅增加處理時間。
此外,數據庫數量的增加也意味著更多的硬件成本。因此,確定分庫數量需要進行全面評估。通常建議初次進行數據庫分片時,可以選擇創建4到8個數據庫。例如,在我們的項目中,我們選擇創建了6個數據庫,這一數量能夠滿足訂單業務在未來一段時間內的需求。
分庫路由
在實施數據庫分庫時,雖然這一變化不涉及業務邏輯,但它必定會對應用程序產生影響。為最小化這種影響,關鍵在于確保分庫邏輯盡可能只在數據訪問層(DAL)處理,而對上層的訂單服務保持透明,這樣,服務層代碼就無需進行大幅修改。實現這一目標確實具有一定挑戰性。以下是一些建議,用以明確DAL和訂單服務各自的職責范圍:
當涉及到單一數據庫的訪問時,例如查詢操作明確指定了用戶ID,則此類SQL查詢應直接路由至特定的數據庫。這種情況下,DAL應負責自動完成路由,且當數據庫分裂時,僅需調整路由邏輯中的模數即可,而無需修改應用層代碼。
對于簡單的跨庫查詢,DAL應負責匯集來自各個分庫的結果,并對上層應用保持透明。
針對需要進行聚合操作的復雜查詢(如涉及groupby、orderby、min、max、avg等操作),建議讓DAL層先行匯總各分庫的查詢結果,隨后由訂單服務層完成進一步處理。這樣的安排既考慮到了DAL層實現所有聚合操作邏輯復雜度較高的問題,也顧及到根據實際經驗,這類需求在應用層處理會更加靈活和高效。
數據訪問層還可以細分為底層的JDBC驅動層和更上層的數據訪問層。若在JDBC層面實現分庫邏輯,會使系統開發復雜度增加,靈活性降低,且目前缺乏成功案例。在實踐中,更常見的做法是在持久層框架的基礎上進一步封裝,形成一個分布式數據訪問層(DDAL),以便實現分庫路由。
分頁處理
在實施水平分庫之后,確實,分頁查詢變得更加復雜,特別是當查詢需要遍歷所有分庫時。例如,假設要按時間順序展示某商家的所有訂單,每頁顯示100條記錄。因為是按商家查詢,需遍歷全部數據庫。若數據庫共有8個,分頁邏輯會相應變復雜:
對于第1頁數據,需從每個數據庫獲取前100條記錄,匯總后共得到800條記錄。接著,在應用層進行二次排序,最終僅保留前100條。
若獲取第10頁數據,每個庫需要提供前1000條記錄(100*10),合計8000條記錄。然后,再次在應用層進行排序,并選取第900到1000條記錄作為結果。
這一機制說明,分頁查詢在分庫環境下需要從每個數據庫中獲取更多數據,并且在應用層執行二次排序,導致內存和處理時間需求隨著分頁深度的增加而顯著增長。與此相對,單庫環境下的分頁查詢則簡單得多,直接從數據庫獲取所需頁的記錄,無需應用層排序。
解決分庫環境下分頁問題的策略包括:
前端應用分頁:可以限制用戶只能訪問前n頁數據。這種做法業務上通常是可接受的,因為用戶很少需要查看后續頁面。若用戶確實需要訪問更深的頁面,可以引導他們縮小查詢范圍再次進行查詢。
在采用用戶 ID 作為分庫依據的系統中,確實存在一個挑戰,即如何高效地處理基于非分庫字段(例如訂單 ID)的查詢。直接查詢所有分庫會導致大量不必要的資源消耗。為了解決這一問題,創建一個訂單 ID 與用戶 ID 之間的映射關系(Lookup 表)是一個有效的策略。這樣,每次基于訂單 ID 的查詢首先訪問 Lookup 表來確定對應的用戶 ID,進而實現對特定分庫的直接定位。
Lookup 表的設計是這樣的:
字段限定:該表僅包含兩個字段——訂單 ID 和用戶 ID,這使得它在存儲和查詢性能上都非常高效。
獨立存儲:Lookup 表存放在一個獨立的數據庫中,這樣做不僅避免了與業務數據的混淆,還能提高查詢效率。
緩存優化:為進一步提高查詢性能,可以利用分布式緩存來存儲這些映射關系。這樣,常見的查詢可以直接從緩存中獲取結果,大大減少數據庫訪問次數。
數據一致性:在新增訂單時,除了在訂單數據庫中添加記錄外,還需同步更新 Lookup 表。這確保了訂單 ID 到用戶 ID 的映射關系始終保持最新。
理任務:對于需要批量獲取數據的場景,可以增加每批次的數據量,例如,每次處理5000條記錄。這樣做可以有效減少分頁訪問次數,減輕數據庫壓力。
利用大數據平臺:在分庫設計中,通常會配備大數據平臺來匯總所有分庫的數據。對于某些分頁查詢,可以考慮通過大數據平臺來實現,特別是當需要全庫數據概覽時。
整體架構

在這種架構下,上層應用(如訂單服務)與數據庫之間的交云通過一系列中間層來實現分庫的邏輯,同時保持對上層服務的透明性。這種設計不僅優化了數據存取效率,還大大簡化了應用層的開發和維護。下面是這個系統架構的關鍵組成部分及其功能:
分庫代理:這是分庫邏輯的核心,它負責實現包括聚合運算和訂單 ID 到用戶 ID 的映射在內的所有分庫相關功能。通過分庫代理,訂單服務無需關心背后的分庫邏輯,可以像訪問單一數據庫一樣進行數據操作。
Lookup 表:專門用于存儲訂單 ID 和用戶 ID 之間的映射關系,這樣即使是基于非分庫字段(訂單 ID)的查詢也能快速定位到對應的數據庫。Lookup 表的存在是優化查詢性能的關鍵,尤其是在基于訂單 ID 查詢時,能夠直接指向單個庫,避免全庫掃描。
緩存(Cache):為了進一步提升查詢效率,Lookup 表的數據會被緩存在分布式緩存中。這種機制可以減少對數據庫的直接訪問,快速響應查詢請求,特別是對于高頻訪問的數據。
分布式數據訪問層(DDAL):提供數據庫路由功能,能夠根據用戶 ID 準確地定位到特定的分庫。對于需要跨多個數據庫進行的操作,DDAL 還支持多線程并發訪問模式以及簡單的結果匯總,優化了數據訪問的效率和響應時間。
數據初始化與同步:Lookup 表的初始數據來源于現有的分庫數據,確保了從一開始就能正確映射訂單 ID 和用戶 ID。當有新的訂單記錄產生時,分庫代理會負責異步將這些新記錄寫入Lookup 表,保持數據的一致性和最新性。
如何安全落地?
為了確保訂單水平分庫的平穩過渡,整個遷移和上線過程采用了分階段實施的策略。這種方法不僅能夠降低風險,還能確保在轉換期間系統的穩定性和數據的一致性。下面是實施過程的詳細步驟:
階段一:技術驗證和部分功能遷移
并行運行Oracle和MySQL數據庫:在初始階段,所有的數據讀寫操作仍然指向原有的Oracle數據庫。同時,通過數據同步程序,定期(例如,每3分鐘)將Oracle數據庫中的數據增量同步到多個MySQL庫中。這樣做的目的是確保MySQL數據庫能夠及時反映最新數據狀態,同時驗證數據同步的準確性和效率。
選擇非實時場景進行驗證:挑選一些對數據實時性要求不高的業務場景(如查詢歷史訂單)作為先行者,將這部分業務的數據訪問切換到MySQL數據庫。這一步驟旨在驗證整個方案的可行性,包括分庫代理、DDAL、Lookup表等基礎設施的功能和性能。
階段二:全面業務遷移
全面接入MySQL:在第一階段驗證無大的技術問題后,接下來將所有實時讀寫操作切換到MySQL數據庫。這一步驟要求徹底廢棄Oracle數據庫,意味著MySQL將成為系統的主要數據存儲方案。
業務功能驗證:在這一階段,重點是驗證遷移后的業務功能是否正常。所有依賴訂單服務的應用都需要接入新的MySQL數據庫。通過大量的測試來確保性能和功能符合預期。
實施這個分庫方案時,分兩個階段一次性成功地完成了上線,特別是在第二階段,超過100個依賴訂單服務的應用僅通過簡單重啟就順利完成了系統升級,期間未遇到較大的問題。這個案例充分證明了分階段實施策略的有效性,同時也展示了良好的前期準備和詳盡測試的重要性。通過這種方式,可以在最大程度上減少遷移帶來的風險,確保系統遷移的平穩執行。