比LoRA還快50%的微調方法來了!一張3090性能超越全參調優,UIUC聯合LMFlow團隊提出LISA
2022 年底,隨著 ChatGPT 的爆火,人類正式進入了大模型時代。然而,訓練大模型需要的時空消耗依然居高不下,給大模型的普及和發展帶來了巨大困難。面對這一挑戰,原先在計算機視覺領域流行的 LoRA 技術成功轉型大模型 [1][2],帶來了接近 2 倍的時間加速和理論最高 8 倍的空間壓縮,將微調技術帶進千家萬戶。
但 LoRA 技術仍存在一定的挑戰。一是 LoRA 技術在很多任務上還沒有超過正常的全參數微調 [2][3][4],二是 LoRA 的理論性質分析比較困難,給其進一步的研究帶來了阻礙。
UIUC 聯合 LMFlow 團隊成員對 LoRA 的實驗性質進行了分析,意外發現 LoRA 非常側重 LLM 的底層和頂層的權重。利用這一特性,LMFlow 團隊提出一個極其簡潔的算法:Layerwise Importance Sampled AdamW(LISA)。

- 論文鏈接:https://arxiv.org/abs/2403.17919
- 開源地址:https://github.com/OptimalScale/LMFlow
LISA 介紹
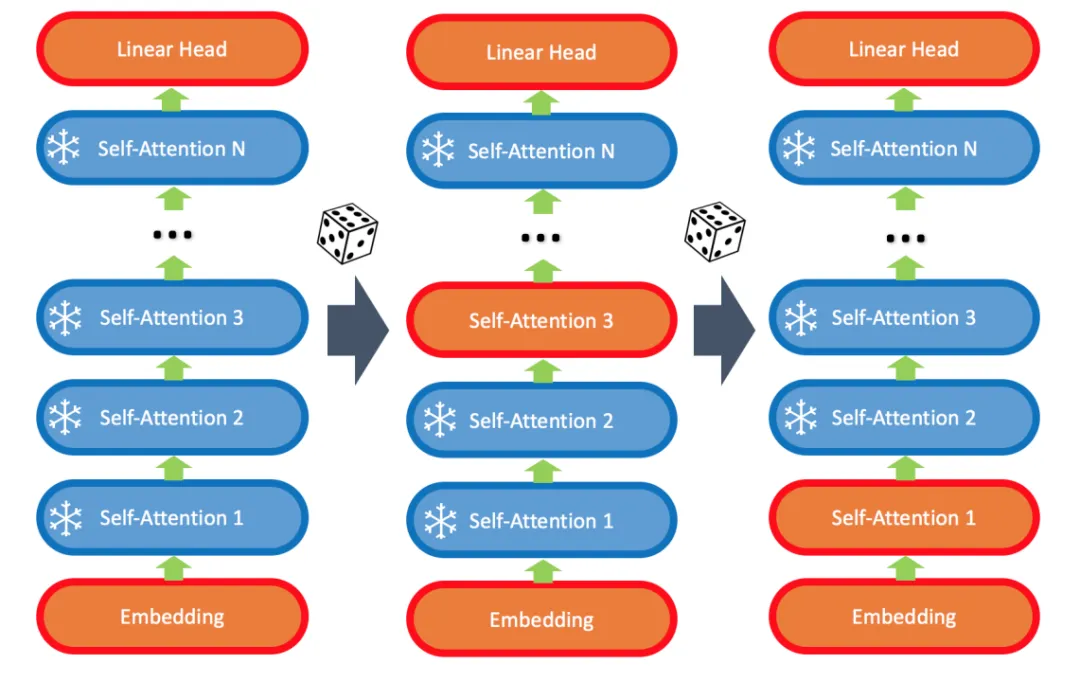
LISA 算法的核心在于:
- 始終更新底層 embedding 和頂層 linear head;
- 隨機更新少數中間的 self-attention 層,比如 2-4 層。

出乎意料的是,實驗發現該算法在指令微調任務上超過 LoRA 甚至全參數微調。


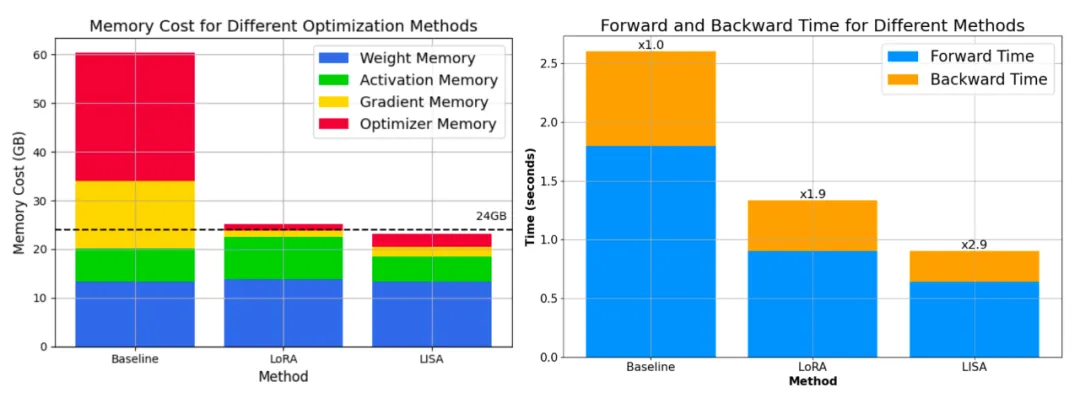
更重要的是,其空間消耗和 LoRA 相當甚至更低。70B 的總空間消耗降低到了 80G*4,而 7B 則直接降到了單卡 24G 以下!
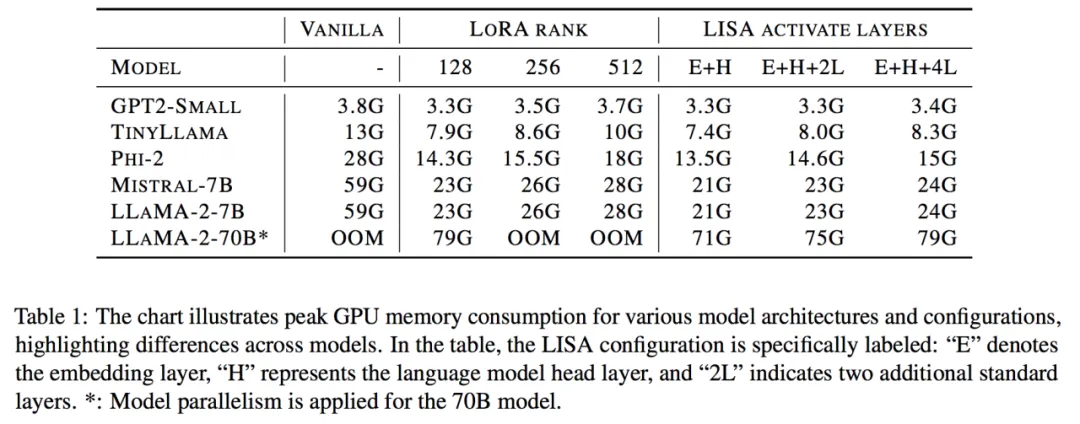
進一步的,因為 LISA 每次中間只會激活一小部分參數,算法對更深的網絡,以及梯度檢查點技術(Gradient Checkpointing)也很友好,能夠帶來更大的空間節省。
在指令微調任務上,LISA 的收斂性質比 LoRA 有很大提升,達到了全參數調節的水平。
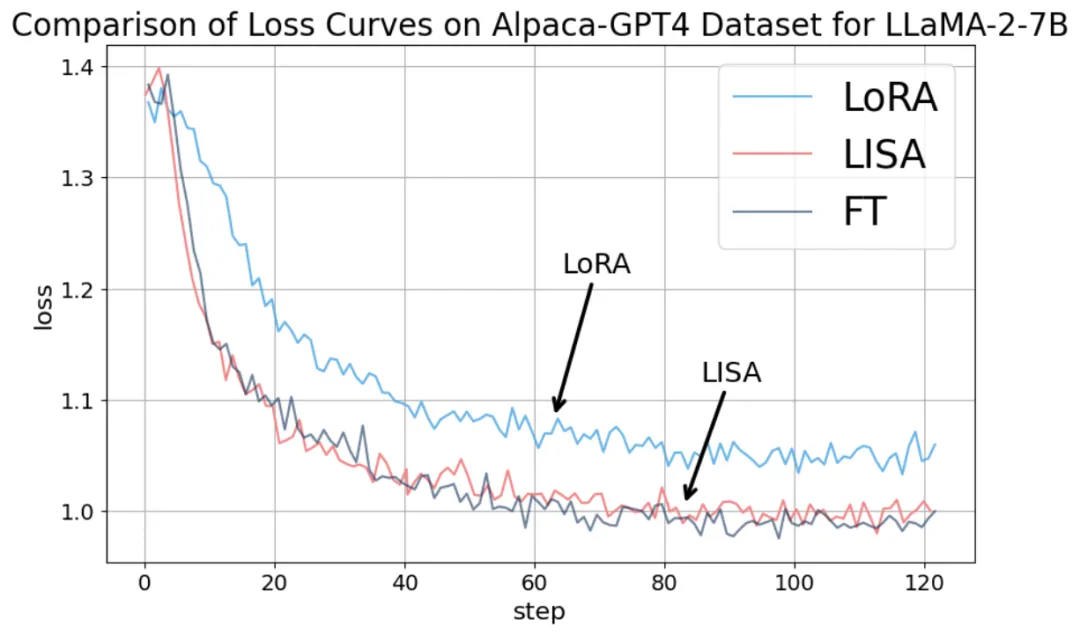
而且,由于不需要像 LoRA 一樣引入額外的 adapter 結構,LISA 的計算量小于 LoRA,速度比 LoRA 快將近 50%。
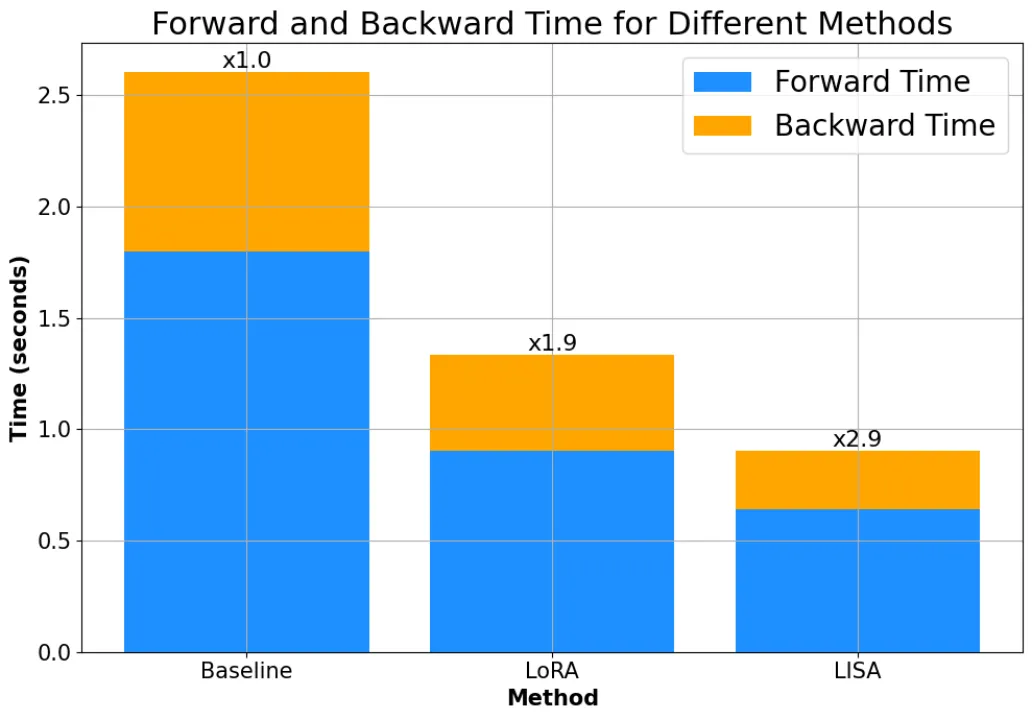
理論性質上,LISA 也比 LoRA 更容易分析,Gradient Sparsification、Importance Sampling、Randomized Block-Coordinate Descent 等現有優化領域的數學工具都可以用于分析 LISA 及其變種的收斂性質。
一鍵使用 LISA
為了貢獻大模型開源社區,LMFlow 現已集成 LISA,安裝完成后只需一條指令就可以使用 LISA 進行微調:

如果需要進一步減少大模型微調的空間消耗,LMFlow 也已經支持一系列最新技術:
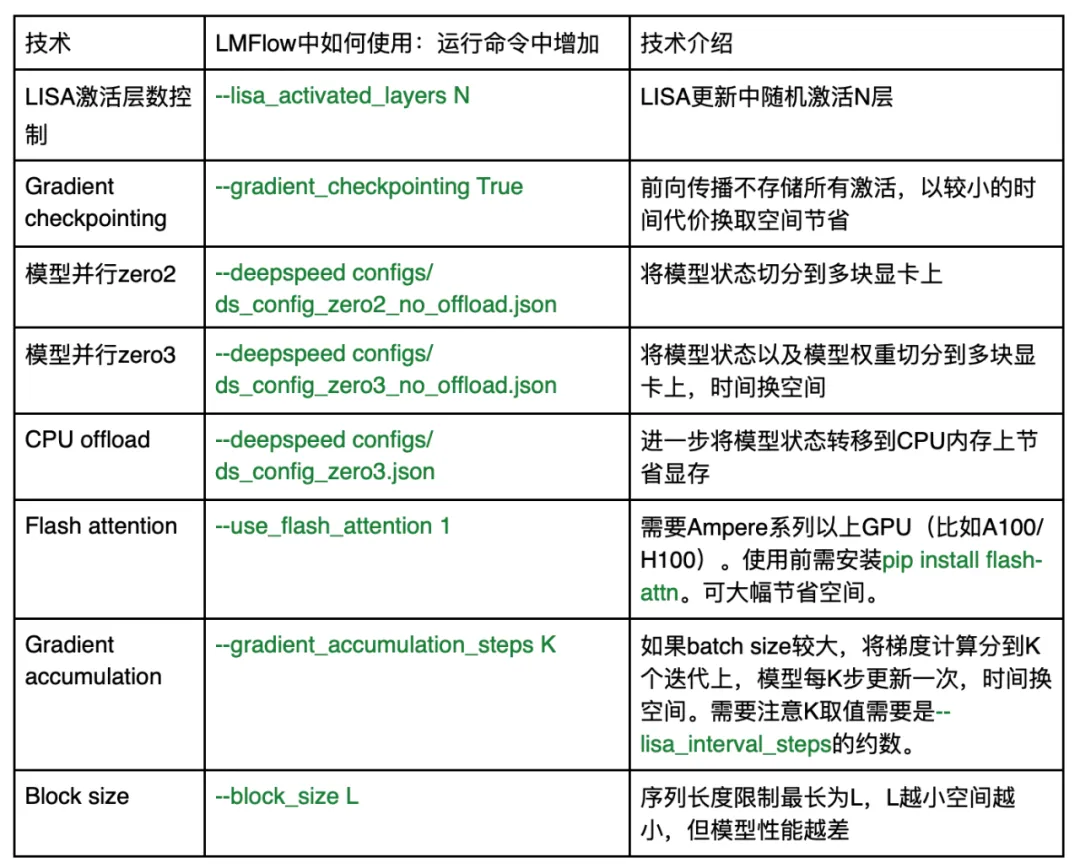
如果在使用過程中遇到任何問題,可通過 github issue 或 github 主頁的微信群聯系作者團隊。LMFlow 將持續維護并集成最新技術。
總結
在大模型競賽的趨勢下,LMFlow 中的 LISA 為所有人提供了 LoRA 以外的第二個選項,讓大多數普通玩家可以通過這些技術參與到這場使用和研究大模型的浪潮中來。正如團隊口號所表達的:讓每個人都能訓得起大模型(Large Language Model for All)。