













只需單卡RTX 3090,低比特量化訓練就能實現LLaMA-3 8B全參微調
自 2010 年起,AI 技術歷經多個重大發展階段,深度學習的崛起和 AlphaGo 的標志性勝利顯著推動了技術前進。尤其是 2022 年底推出的 ChatGPT,彰顯了大語言模型(LLM)的能力達到了前所未有的水平。自此,生成式 AI 大模型迅速進入高速發展期,并被譽為第四次工業革命的驅動力,尤其在推動智能化和自動化技術在產業升級中有巨大潛力。這些技術正在改變我們處理信息、進行決策和相互交流的方式,預示著將對經濟和社會各層面帶來深遠的變革。因此,AI 為我們帶來了重大機遇,然而在 AI 技術不斷進步的同時,其產業落地也面臨諸多挑戰,尤其是高昂的成本問題。例如,在商業化過程中,大模型尤其因成本過高而成為企業的一大負擔。持續的技術突破雖然令人鼓舞,但如果落地階段的成本無法控制,便難以持續資助研發并贏得廣泛信任。然而,開源大模型的興起正逐步改變這一局面,它們不僅技術開放,還通過降低使用門檻促進了技術的平等化和快速發展。例如,普通的消費級 GPU 就能夠支持 7B/8B 規模模型的全參數微調操作,可能比采用高成本閉源模型成本低幾個數量級。在這種去中心化的 AI 范式下,開源模型的應用在保證質量的前提下,可以顯著降低邊際成本,加速技術的商業化進程。此外,觀察顯示,經過量化壓縮的較大模型在性能上往往優于同等大小的預訓練小模型,說明量化壓縮后的模型仍然保持了優秀的能力,這為采用開源模型而非自行重復預訓練提供了充分的理由。
在 AI 技術的迅猛發展中,云端大模型不斷探索技術的極限,以實現更廣泛的應用和更強大的計算能力。然而,市場對于能夠快速落地和支撐高速成長的智能應用有著迫切需求,這使得邊緣計算中的大模型 —— 特別是中小型模型如 7B 和 13B 的模型 —— 因其高性價比和良好的可調性而受到青睞。企業更傾向于自行微調這些模型,以確保應用的穩定運行和數據質量的持續控制。此外,通過回流機制,從應用中收集到的數據可以用于訓練更高效的模型,這種數據的持續優化和用戶反饋的精細化調整成為了企業核心競爭力的一部分。盡管云端模型在處理復雜任務時精度高,但它們面臨的幾個關鍵挑戰不容忽視:
- 推理服務的基礎設施成本:支持 AI 推理的高性能硬件,尤其是 GPU,不僅稀缺而且價格昂貴,集中式商業運營帶來的邊際成本遞增問題成為 AI 業務從 1 到 10 必須翻越的障礙。
- 推理延遲:在生產環境中,模型必須快速響應并返回結果,任何延遲都會直接影響用戶體驗和應用性能,這要求基礎設施必須有足夠的處理能力以滿足高效運行的需求。
- 隱私和數據保護:特別是在涉及敏感信息的商業應用場景中,使用第三方云服務處理敏感數據可能會引發隱私和安全問題,這限制了云模型的使用范圍。
考慮到這些挑戰,邊緣計算提供了一個有吸引力的替代方案。在邊緣設備上直接運行中小模型不僅能降低數據傳輸的延遲,提高響應速度,而且有助于在本地處理敏感數據,增強數據安全和隱私保護。結合自有數據的實時反饋和迭代更新,AI 應用將更高效和個性化。
在當前的開源模型和工具生態中,盡管存在眾多創新和進步,仍面臨一系列不足之處。首先,這些模型和工具往往并未針對本地部署場景進行優化,導致在本地運用時常常受限于算力和內存資源。例如,即便是相對較小的 7B 規模模型,也可能需要高達 60GB 的 GPU 顯存 (需要價格昂貴的 H100/A100 GPU) 來進行全參數微調。此外,市場上可選的預訓練小型模型數量和規模相對有限,大模型的開發團隊往往更專注于追求模型規模的擴展而非優化較小的模型。另一方面,現有的量化技術雖然在模型推理部署中表現良好,但其主要用途是減少模型部署時的內存占用。量化后的模型權重在微調過程中無法進行優化,這限制了開發者在資源有限的情況下使用較大模型的能力。開發者往往希望在微調過程中也能通過量化技術節省內存,這一需求尚未得到有效解決。
我們的出發點在于解決上述痛點,并為開源社區貢獻實質性的技術進步。基于 Neural Architecture Search (NAS) 以及相匹配的 Post-Training Quantization (PTQ) 量化方案,我們提供了超過 200 個從不同規模開源大模型序列壓縮而來的低比特量化小模型,這些模型涵蓋了從 110B 到 0.5B 的規模跨度,并優先保證精度和質量,再次刷新了低比特量化的 SOTA 精度。同時,我們的 NAS 算法深入考量了模型參數量化排布的硬件友好性,使得這些模型能輕易的在主流計算硬件 (如 Nvidia GPU 和 Apple silicon 芯片硬件平臺) 進行適配,極大地方便了開發者的使用。此外,我們推出了 Bitorch Engine 開源框架以及專為低比特模型訓練設計的 DiodeMix 優化器,開發者可以直接對低比特量化模型在量化空間進行全參數監督微調與繼續訓練,實現了訓練與推理表征的對齊,大幅度壓縮模型開發與部署的中間環節。更短的工程鏈條將大幅度提升工程效率,加快模型與產品迭代。通過結合低比特權重訓練技術和低秩梯度技術,我們就能實現在單卡 RTX 3090 GPU 上對 LLaMA-3 8B 模型進行全參數微調(圖 1)。上述解決方案簡潔有效,不僅節省資源,而且有效地解決了量化模型精度損失的問題。我們將在下文對更多技術細節進行詳細解讀。

圖 1. 單卡 3090 實現 LLaMA-3 8B 全參微調
模型量化
大模型時代的顯著特征之一便是模型對計算資源需求的大幅度攀升。GPTQ 與 AWQ 等權重 PTQ 壓縮方案以可擴展的方式驗證了大語言模型在 4-bit 表征上的可靠性,在相比于 FP16 表征實現 4 倍的權重空間壓縮的同時實現了較小的性能丟失,大幅度降低模型推理所需的硬件資源。與此同時,QLoRA 巧妙地將 4-bit LLM 表征與 LoRA 技術相結合,將低比特表征推廣至監督微調階段,并在微調結束后將 LoRA 模塊與原始 FP16 模型融合,實現了低資源需求下的模型 Parameter-Efficient-Finetuning (PEFT)。這些前沿的高效工程探索為社區提供了便利的研究工具,大幅度降低了模型研究與產業應用的資源門檻,也進一步激發了學術與產業界對更低比特表征的想象空間。
相比于 INT4,更低比特的 Round-To-Nearest (RTN) 量化如 INT2 表征通常要求原始模型有著更平滑的連續參數空間才能保持較低的量化損失,例如,超大規模模型往往存在容量冗余并有著更優的量化容忍度。而通過 LLM.int8 () 等工作對當前基于 transformer 架構的大語言模型分析研究,我們已經觀察到了模型推理中廣泛存在著系統性激活涌現現象,少數通道對最終推理結果起著決定性作用。近期 layer-Importance 等多項工作則進一步觀測到了不同深度的 transformer 模塊對模型容量的參與度也表現出非均勻分布的特性。這些不同于小參數模型的分布特性引申出了大量 Model Pruning 相關研究的同時也為低比特壓縮技術提供了研究啟示。基于這些工作的啟發,我們探索了一種搜索與校準結合的 Two-stage LLM 低比特量化方案。
(1) 首先,我們利用 NAS 相關方法對大語言模型參數空間的量化敏感性進行搜索與排序,利用經典的混合精度表征實現模型參數中的最優比特位分配。為降低模型量化后的大規模硬件部署難度,我們放棄了復雜的矢量量化與 INT3 表征等設計,采用經典 Group-wise MinMax Quantizer,同時僅選擇 INT4 (group size 128) 與 INT2 (group size 64) 作為基礎量化表征。相對簡單的 Quantizer 設計一方面降低了計算加速內核的設計復雜度與跨平臺部署難度,另一方面也對優化方案提出了更高的要求。為此,我們探索了 Layer-mix 與 Channel-mix 兩種排布下的混合精度搜索空間。其中,Channel-mix 量化由于能更好適配 transformer 架構的系統性激活涌現現象,往往能達到更低的量化損失,而 Layer-mix 量化在具備更優的硬件友好度的同時仍然保持了極佳的模型容量。利用高效的混合精度 NAS 算法,我們能在數小時內基于低端 GPU 如 RTX 3090 上完成對 Qwen1.5 110B 大模型的量化排布統計,并基于統計特性在數十秒內完成任意低比特量級模型的最優架構搜索。我們觀察到,僅僅基于搜索與重要性排序,已經可以快速構造極強的低比特模型。
(2) 搜索得到模型的量化排布后,我們引入了一種基于離線知識蒸餾的可擴展 PTQ 校準算法,以應對超低比特量化 (如 2 到 3-bit) 帶來的累積分布漂移問題,僅需使用不超過 512 個樣本的多源校準數據集,即可在數小時內使用單張 A100 GPU 完成 0.5B-110B 大語言模型的 PTQ 校準。盡管額外的校準步驟引入了更長的壓縮時間,從經典低比特以及量化感知訓練(QAT)相關研究的經驗中我們可以了解到,這是構建低量化損失模型的必要條件。而隨著當前開源社區 100B + 大模型的持續涌現 (如 Command R plus、Qwen1.5 110B, LLama3 400B),如何構建高效且可擴展的量化壓縮方案將是 LLM 社區系統工程研究的重要組成部分,也是我們持續關注的方向。我們經驗性的證明,搜索與校準相結合的低比特量化方案在推進低量化損耗表征模型的同時,在開源社區模型架構適配、硬件預期管理等方面都有著顯著優勢。
性能分析
基于 Two-stage 量化壓縮方案,我們提供了超過 200 個從不同規模開源大模型序列壓縮而來的低比特量化小模型,涵蓋了最新的 Llama3、Phi-3、Qwen1.5 以及 Mistral 等系列。我們利用 EleutherAI 的 lm-evaluation-harness 庫等對低比特量化模型的真實性能與產業場景定位進行了探索。其中我們的 4-bit 量化校準方案基本實現了相對于 FP16 的 lossless 壓縮。基于混合 INT4 與 INT2 表征實現的 sub-4 bit 量化校準方案在多項 zero-shot 評測結果表明,搜索與少量數據校準的經典 INT2 量化表征已經足夠維持 LLM 在語言模型閱讀理解 (BoolQ,RACE,ARC-E/C)、常識推理 (Winogr, Hellaswag, PIQA) 以及自然語言推理 (WIC, ANLI-R1, ANLI-R2, ANLI-R3) 方面的核心能力。
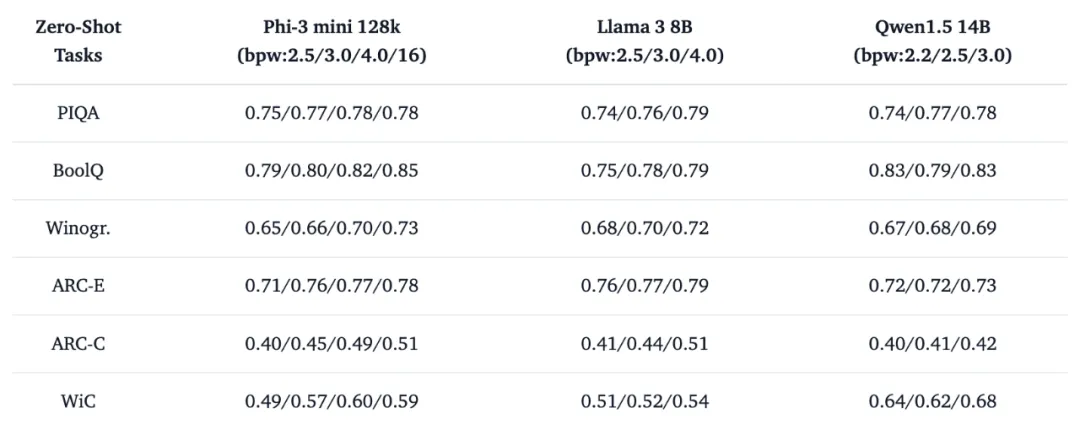
表 1. 低比特量化模型 zero-shot 評測示例
同時我們試圖利用進一步的 few-shot 消融對比實驗探索超低比特在產業應用中的定位,有趣的現象是,INT2 表征為主體的超低比特 (bpw: 2.2/2.5) 模型在 5-shot 幫助下即可實現推理能力的大幅度提升。這種對少量示例樣本的利用能力表明,低比特壓縮技術在構造容量有限但足夠 “聰明” 的語言模型方面已經接近價值兌現期,配合檢索增強 (RAG) 等技術適合構造更具備成本效益的模型服務。
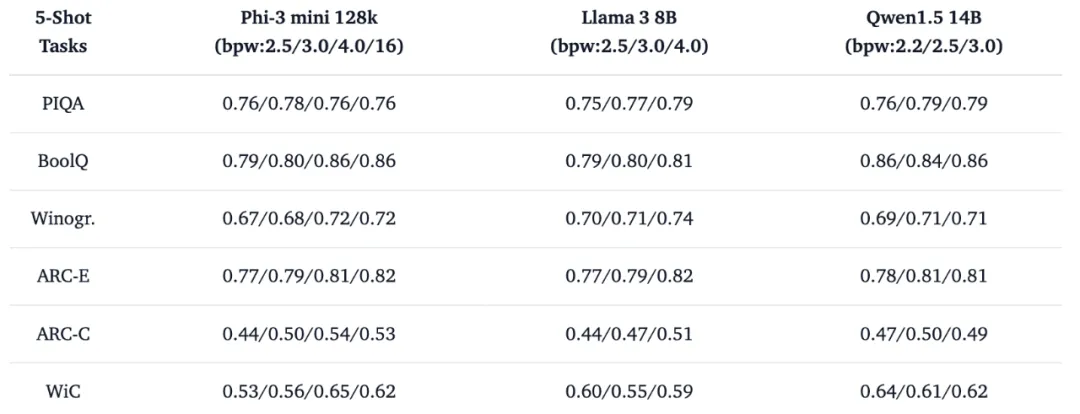
表 2. 低比特量化模型 5-shot 評測示例
考慮到當前少樣本 PTQ 校準僅僅引入了有限的計算資源 (校準數據集 < 512),以我們開源的低比特模型作為初始化進行更充分的全參數量化訓練將進一步提升低比特模型在實際任務中的表現,我們已經為這一需求的高效實現提供了定制化開源工具。
開源工具
我們推出了三款實用的工具來輔助這些模型的使用,并計劃未來持續優化和擴展。
Bitorch Engine (BIE) 是一款前沿的神經網絡計算庫,其設計理念旨在為現代 AI 研究與開發找到靈活性與效率的最佳平衡。BIE 基于 PyTorch,為低位量化的神經網絡操作定制了一整套優化的網絡組件,這些組件不僅能保持深度學習模型的高精度和準確性,同時也大幅降低了計算資源的消耗。它是實現低比特量化 LLM 全參數微調的基礎。此外,BIE 還提供了基于 CUTLASS 和 CUDA 的 kernel,支持 1-8 bit 量化感知訓練。我們還開發了專為低比特組件設計的優化器 DiodeMix,有效解決了量化訓練與推理表征的對齊問題。在開發過程中,我們發現 PyTorch 原生不支持低比特張量的梯度計算,為此我們對 PyTorch 進行了少量調整,提供了支持低比特梯度計算的修改版,以方便社區利用這一功能。目前我們為 BIE 提供了基于 Conda 和 Docker 的兩種安裝方式。而完全基于 Pip 的預編譯安裝版本也會在近期提供給社區,方便開發者可以更便捷的使用。
green-bit-llm 是為 GreenBitAI low-bit LLM 專門開發的工具包。該工具包支持云端和消費級 GPU 上的高性能推理,并與 Bitorch Engine 配合,完全兼容 transformers、PEFT 和 TRL 等主流訓練 / 微調框架,支持直接使用量化 LLM 進行全參數微調和 PEFT。目前,它已經兼容了多個低比特模型序列,詳見表 3。
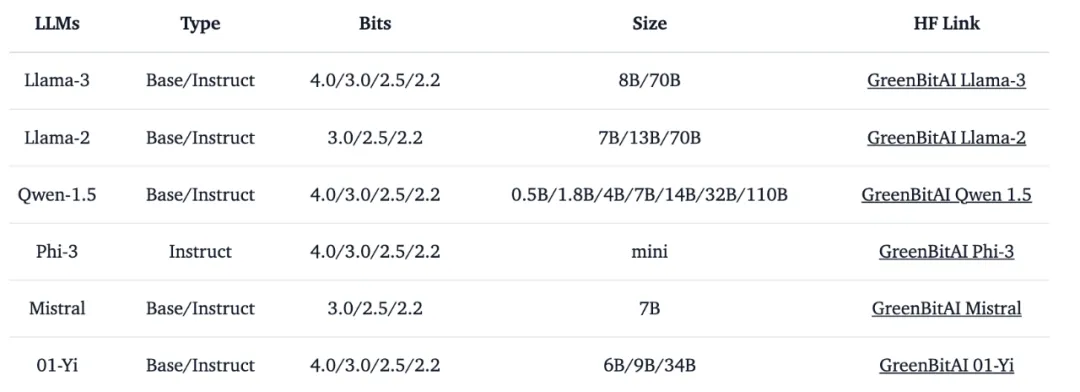
表 3. 已支持低比特模型序列信息
以目前最新的開源大模型 Llama-3 8b base 模型為例,我們選擇它的 2.2/2.5/3.0 bit 作為全參數量化監督微調 (Q-SFT) 對象,使用 huggingface 庫托管的 tatsu-lab/alpaca 數據集 (包含 52000 個指令微調樣本) 進行 1 個 epoch 的最小指令微調對齊訓練測試,模型完全在量化權重空間進行學習而不涉及常規的 LoRA 參數優化與融合等后處理步驟,訓練結束后即可直接實現高性能的量化推理部署。在這一例子中,我們選擇不更新包括 Embedding,、LayerNorm 以及 lm.head 在內的任何其他 FP16 參數,以驗證量化空間學習的有效性。傳統 LoRA 微調、Q-SFT 配合 Galore 優化器微調以及單純使用 Q-SFT 微調對低比特 Llama 3 8B 模型能力的影響如表 4 中所示。

表 4. Q-SFT 對量化 LLM 的 zero-shot 能力影響
相比于傳統的 LoRA 微調 + 后量化的工程組合,Q-SFT 直接在推理模型量化空間進行學習的方式大幅度簡化了大模型從開發到部署之間的工程鏈條,同時實現了更好的模型微調效果,為更具成本效益的模型擴展提供了解決方案。此外,推理模型與訓練模型的表征對齊也為更絲滑的端側學習與應用提供了可能性,例如,在端側進行非全參數 Q-SFT 將成為更可靠的端側優化管線。
在我們的自研低比特模型以外,green-bit-llm 完全兼容 AutoGPTQ 系列 4-bit 量化壓縮模型,這意味著 huggingface 現存的 2848 個 4-bit GPTQ 模型都可以基于 green-bit-llm 在量化參數空間進行低資源繼續學習 / 微調。作為 LLM 部署生態最受歡迎的壓縮格式之一,現有 AutoGPTQ 愛好者可以基于 green-bit-llm 在模型訓練和推理之間進行無縫切換,不需要引入新的工程節點。
Q-SFT 和 Bitorch-Engine 能在低資源環境下穩定工作的關鍵是,我們探索了專用于低比特大模型的 DiodeMix 優化器,以緩解 FP16 梯度與量化空間的表征 Mismatch 影響,量化參數更新過程被巧妙的轉換為基于組間累積梯度的相對大小排序問題。更符合量化參數空間的高效定制優化器將是我們未來持續探索的重要方向之一。
gbx-lm 工具將 GreenBitAI 的低比特模型適配至蘋果的 MLX 框架,進而能在蘋果芯片上高效的運行大模型。目前已支持模型的加載和生成等基礎操作。此外,該工具還提供了一個示例,遵循我們提供的詳盡指南,用戶可以在蘋果電腦上迅速建立一個本地聊天演示頁面,如下圖所示。
我們非常期待與更多開發者一同推動開源社區的發展。





























