80M參數打平GPT-4!蘋果發超強上下文理解模型,聰明版Siri馬上就來
會讀心的Siri想不想要?
今天,蘋果發布了自家的最新模型ReALM,僅需80M參數,就能在上下文理解能力上打平甚至超越GPT-4!

論文地址:https://arxiv.org/pdf/2403.20329.pdf
ReALM可以將任何形式的上下文轉換為文本來進行理解,比如解析屏幕、多輪對話、以及上下文中的引用。
在此基礎上,用戶正在關注什么,甚至是想些什么,都逃不過AI的法眼。
有了這個技術,你的Siri會反應更快,而且更加智能。

比如你讓Siri推薦一些披薩店,在看到列表后,你可能希望選擇其中一個,打電話叫個外賣。
以前憨憨的Siri并不能執行后面這個操作,但有了ReALM之后,就可以通過分析設備數據等操作,理解你的指示。
在幾項相關基準測試中,ReALM的性能表現非常亮眼,連最小的80M參數模型也能媲美GPT-4,而更大的模型分數則更高。

模糊指令
讓AI模型根據模糊的語言指令(比如「這個」、「那個」),來執行任務是一個相當復雜的問題。
不過,看起來蘋果已經找到了方法,讓AI模型能夠綜合各種模態、各種維度的信息,像人類一樣思考和工作。
人類在交談時,會聯系到相當多的信息,——玩手機時也一樣(比如后臺任務、其他界面的顯示、非對話實體)。
傳統的模型很難理解這么復雜的參考信息,而蘋果通過將所有內容轉換為文本來簡化了這個問題。
下面是一個對話場景轉換為文本的例子:

在這方面,即使是ReALM最小的模型都表現得足夠好(GPT-4級別),而且僅僅80M的參數非常適合在終端設備上使用。
——做更適合iPhone等設備的智能,這顯然是蘋果想要開辟的道路。
以解析屏幕為例,GPT-4等模型依賴圖像識別,背后是基于大量圖像訓練數據而產生的大量參數。
而ReALM選擇將圖像轉換為文本,節省了高級圖像識別所需的參數,從而變得更小、更高效。
此外,蘋果還通過限制解碼、使用簡單的后處理等方法來避免幻覺問題。
近期,蘋果的人工智能研究不斷發表,而6月將要召開的WWDC,會讓我們看到蘋果更多面向未來的布局。
論文細節
首先給出一圖流總結:

數據集
論文使用的數據集由合成數據,以及在注釋者幫助下創建的數據組成。
每個數據點都包含用戶查詢和實體列表,以及與相應用戶查詢相關的真值實體(或實體集)。
反過來,每個實體又包含有關其類型和其他屬性的信息,如名稱和與實體相關的其他文本細節(如警報的標簽和時間)。
對于存在相關屏幕上下文的數據點,上下文的形式包括實體的邊界框、實體周圍的對象列表以及這些周圍對象的屬性(如類型、文本內容和位置)。
下表給出了訓練集和測試集的情況:

會話數據
在這種情況下,將收集用戶與代理交互相關的實體的數據。
為此,會向測評員展示帶有綜合實體列表的屏幕截圖,并要求測評員提供能明確引用綜合列表中任意挑選的實體的查詢。
例如,可能會向測評員提供企業或警報的綜合列表,并要求他們引用該列表中的特定實體。
例如,可能會向測評員顯示一個綜合構建的企業列表,然后讓他們引用所提供的列表中的特定企業。
例如,他們可能會說「帶我去倒數第二的那個」或「打電話給主街上的那個」。
合成數據
另一種獲取數據的方法是依靠模板合成數據。
這種方法對基于類型的引用特別有用,因為用戶查詢和實體類型足以解析引用,而不需要依賴描述。

需要注意的是,此數據集的合成性質并不排除它包含可以將多個實體解析為給定引用的數據點:例如,對于查詢「play it」,「it」可以解析為「音樂」和「視頻」類型的所有實體。
有兩個模板可以生成合成數據。第一個「基礎」模板包括引用、實體和必要時可能的槽值(slot values)。
第二個「語言」模板導入了基礎模板,并添加了不同的查詢變量,這些查詢可用于基礎模板中定義的引用的目標案例。
數據生成腳本采用基礎模板和語言模板,并通過用基礎模板中定義的提及和槽值替換引用,生成語言模板中給出的可能查詢。
它遍歷所有受支持的實體。對于與模板中的實體匹配的實體類型,它會連接引用和實體,否則它只會添加沒有引用的實體類型。
屏幕數據
屏幕數據是從存在電話號碼、電子郵件或者實際地址信息的各種網頁中收集的。
論文對屏幕數據進行了兩個階段的注釋處理。
第一階段是根據屏幕提取查詢,第二階段是識別給定查詢的實體和提及。
在第一個分級項目中,測評員會得到一張帶有綠色和紅色方框的屏幕截圖(圖 1a),以及綠色框中包含的信息,并要求他們將綠色方框中的數據歸類為其中一個實體,如電話號碼、電子郵件地址等。
然后,要求測評員對綠框中的數據提供三個唯一的查詢結果。
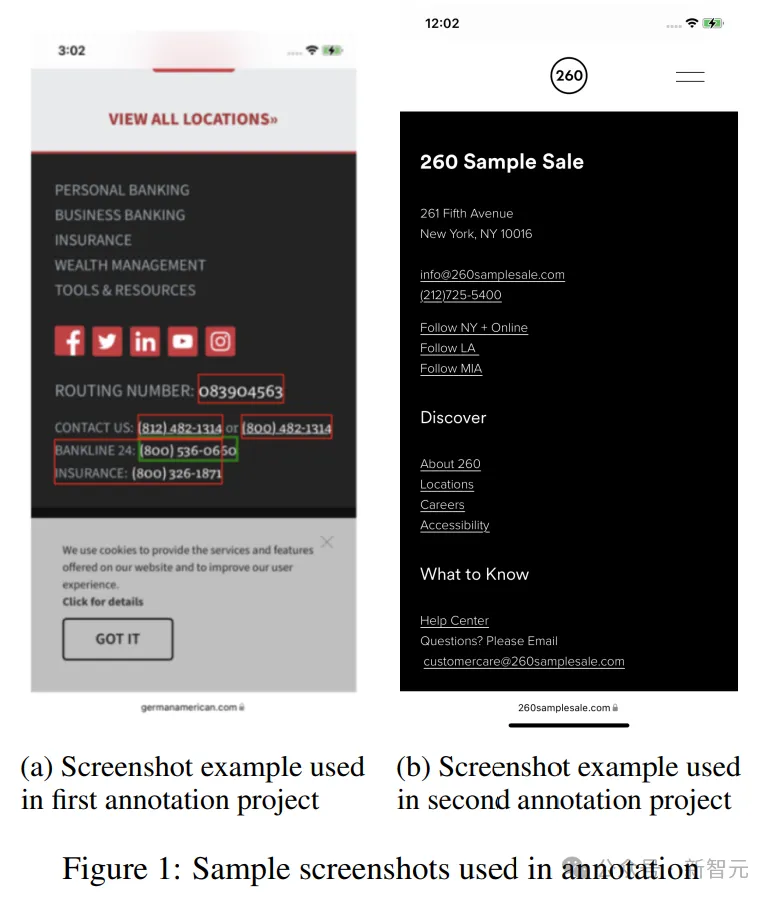
在第二個注釋項目(圖1b)中,將第一步收集到的查詢以列表形式逐一展示給評分員,并附帶相應的屏幕截圖(無邊界框)和所有屏幕實體。
測評員被問及該查詢是否提到了給定的視覺實體之一,查詢是否聽起來自然。此外,他們還被要求提供所給查詢中提及的列表實體,并標記查詢中提及該實體的部分。
模型
基線
論文將其提出的模型ReALM與兩種基線方法進行了比較:一種是基于MARRS中提出的參考解析器的重新實現(這種方法不使用LLM);另一種是基于ChatGPT。
研究方法
在論文的具體實施中使用以下流程對LLM(FLAN-T5模型)進行微調。
將解析后的輸入提供給模型,并對其進行微調。

需要注意的是,與基線不同,論文沒有在FLAN-T5模型上運行廣泛的超參數搜索,而是堅持使用默認的微調參數。
對于由用戶查詢和相應實體組成的每個數據點,我們都會將其轉換為句子格式,以便提供給LLM進行訓練。
會話引用
為了完成這項工作,論文假設會話引用有兩種類型:基于類型的引用和描述性引用。
基于類型的引用在很大程度上依賴于將用戶查詢與實體類型結合使用,以確定哪個實體(一組實體中的哪一個)與相關的用戶查詢最相關:
例如,如果用戶說「play this」,我們就知道他們指的是一首歌或一部電影這樣的實體,而不是電話號碼或地址;「call him」同樣指的是一組電話號碼或聯系人中的第一個,而不是警報器。
相比之下,描述性引用傾向于使用實體的某個屬性來唯一標識它:例如,「The one in Times Square」可能是指一組地址或企業中的一家。

需要注意的是,通常情況下,引用可能同時依賴于類型和描述來明確指代一個對象:考慮示例「play the one from Abbey Road」與「directions to the one on Abbey Road」,這兩種情況都依賴于實體類型和描述,來識別第一種情況下的歌曲,以及第二種情況下的地址。
在論文提出的方法中,簡單地對實體的類型和各種屬性進行編碼。
解析屏幕
對于屏幕上的引用,先假設存在能夠解析屏幕文本以提取實體的上游數據檢測器。
然后,獲得這些實體的類型、邊界框和相關的非實體文本元素列表。
使用下面給出的算法,將這些實體(以及屏幕的相關部分)以僅涉及文本的方式編碼到模型中:

研究人員假設所有實體及其周圍對象的位置都可以通過各自邊界框的中心來表示。
然后先從上到下(垂直,沿y軸)對這些中心(以及相關對象)進行排序,并在保持穩定的情況下,從左到右(水平,沿x軸)排序。
接下來,邊距內的所有對象都被視為在同一行上,并用制表符彼此分隔,邊距外更下方的對象被放置在下一行。
重復進行上面的操作,就可以有效地將屏幕信息從左到右、從上到下編碼為純文本。
實驗結果
下表展示了ReALM和其他SOTA模型PK的結果:

總體而言,ReALM在所有類型的數據集中都優于MARRS模型,并且干掉了參數量大幾個數量級的GPT-3.5。
在屏幕相關的數據集上,ReALM采用的文本編碼方法能夠表現得幾乎與GPT-4(采用屏幕截圖)一樣好。
最后,研究人員嘗試了不同尺寸的模型。可以看到,隨著模型大小的增加,所有數據集的性能都有所提高,而屏幕相關數據集的差異最為明顯,因為這項任務在本質上更加復雜。