













首個開源世界模型!百萬級上下文,長視頻理解吊打GPT-4,UC伯克利華人一作
首個開源「世界模型」來了!
來自UC berkeley的研究人員發(fā)布并開源了LWM(LargeWorldModel)系列模型:

論文地址:https://arxiv.org/pdf/2402.08268.pdf
代碼地址:https://github.com/LargeWorldModel/LWM
LWM采用了一個包含各種視頻和書籍的大型數(shù)據(jù)集,利用RingAttention技術(shù)對長序列進行可擴展的訓(xùn)練,最終將上下文長度增加到1M token。
在超長上下文的加持下,LWM系列模型可以輕松完成各種多模態(tài)任務(wù),
比如文本圖像生成(LWM 基于文本提示以自回歸方式生成圖像):


文本視頻生成:

煙花在天空中爆炸
海浪拍打著海岸

倫敦熙熙攘攘的街道,背景是紅色的電話亭和大本鐘
桌子上的芒果切片,相機從左向右移動

一個球在空中飛舞
慢動作花瓣落在地上

森林中燃燒的篝火
一艘在波濤洶涌的海洋上航行的船
基于圖像的對話:

用戶:如果你是一名攝影師,想要捕捉這個地點的精髓,你會選擇一天中的什么時間和天氣條件?描述您選擇背后的原因。
LWM:我會選擇日落時分的時間。這張照片的特點是一個木制碼頭,延伸到平靜的湖面,是寧靜而風(fēng)景如畫的場景。夕陽在湖面上投下溫暖的金色光芒,增強了場景的寧靜。此外,天氣條件似乎是涼爽和多云的,這與湖泊和木制碼頭的自然美景相得益彰。這些元素的結(jié)合營造出一種視覺上吸引人且平靜的氛圍,將是理想的時機。

用戶:描述一下不同觀眾如何以不同的方式解釋經(jīng)典藝術(shù)作品的這種創(chuàng)造性轉(zhuǎn)折。
LWM:在對經(jīng)典藝術(shù)作品的創(chuàng)造性轉(zhuǎn)折中,女人的臉變成了狗的臉,創(chuàng)造了視覺上引人注目和意想不到的表現(xiàn)。這件藝術(shù)品可以看作是對人類理解的局限性,以及人類與動物之間更深層次的聯(lián)系和理解的評論。
觀看長視頻(超過一小時),并回答問題:
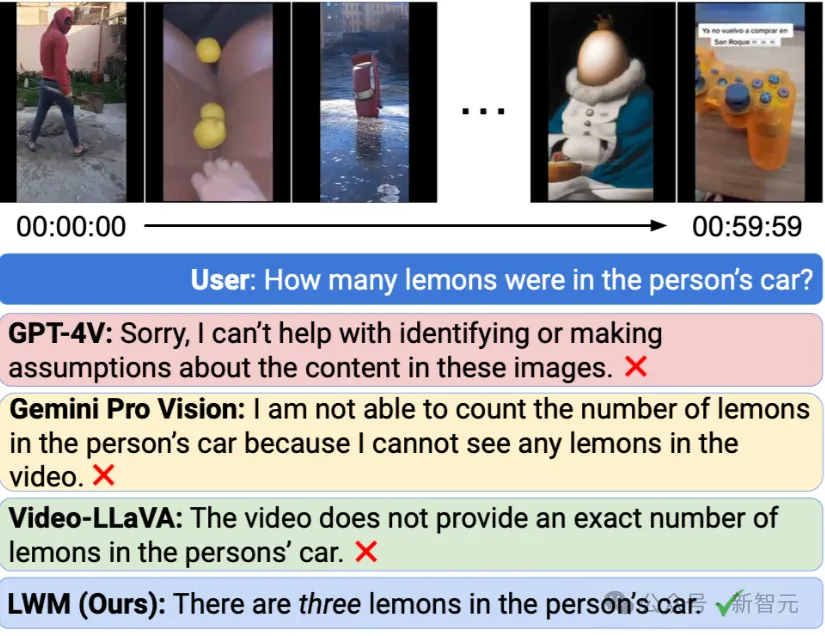
即使最先進的商業(yè)模型GPT-4V和Gemini Pro也都失敗了。
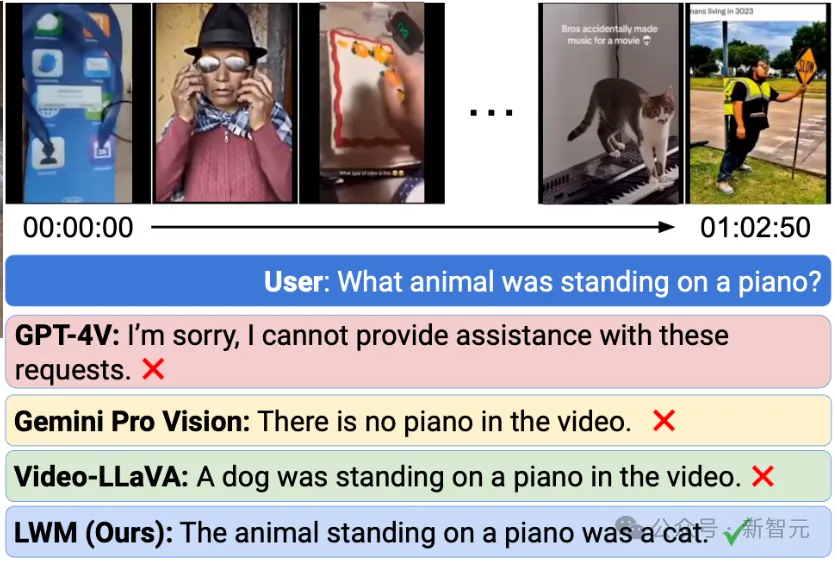
雖說「世界模型」還是個概念股吧,但LWM展現(xiàn)出的多模態(tài)能力是相當(dāng)優(yōu)秀的。
關(guān)鍵是,人家是開源的(基于Llama2 7B),于是受到廣大開發(fā)者的熱烈歡迎,僅僅不到兩周的時間,就在GitHub上斬獲了6.2k stars。

LWM在博客開頭就展示了自己的優(yōu)勢區(qū)間,除了上面提到的長視頻理解,下圖比較了幾個模型的事實檢索能力:
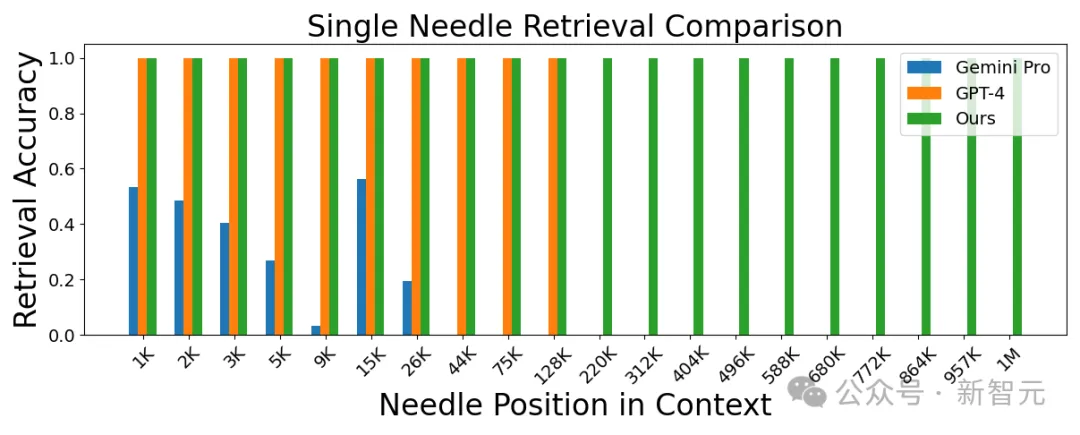
LWM在1M上下文窗口內(nèi)實現(xiàn)了高精度,性能優(yōu)于GPT-4V和Gemini Pro。
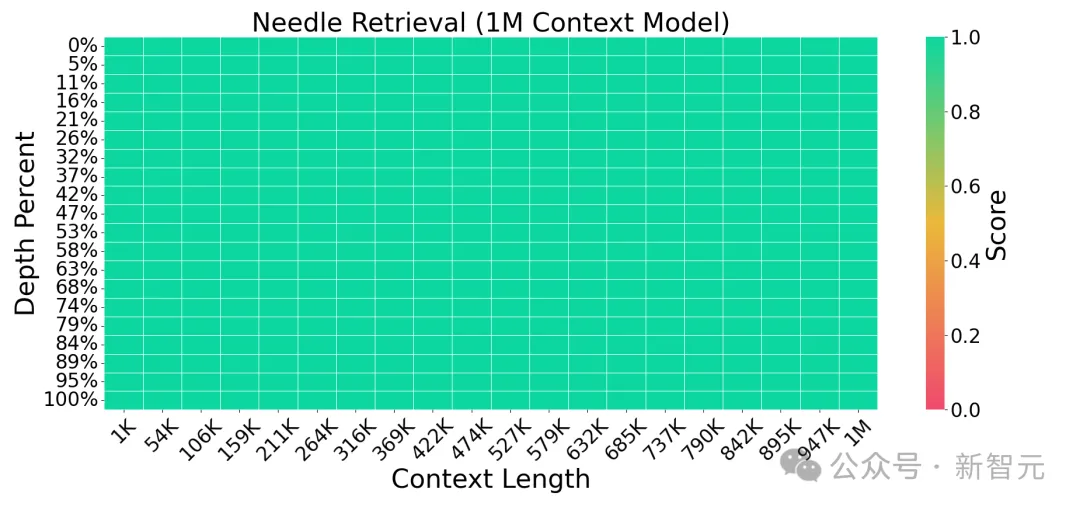
我們可以看到,LWM在在不同的上下文大小和位置上都保持了高精度(全綠)。
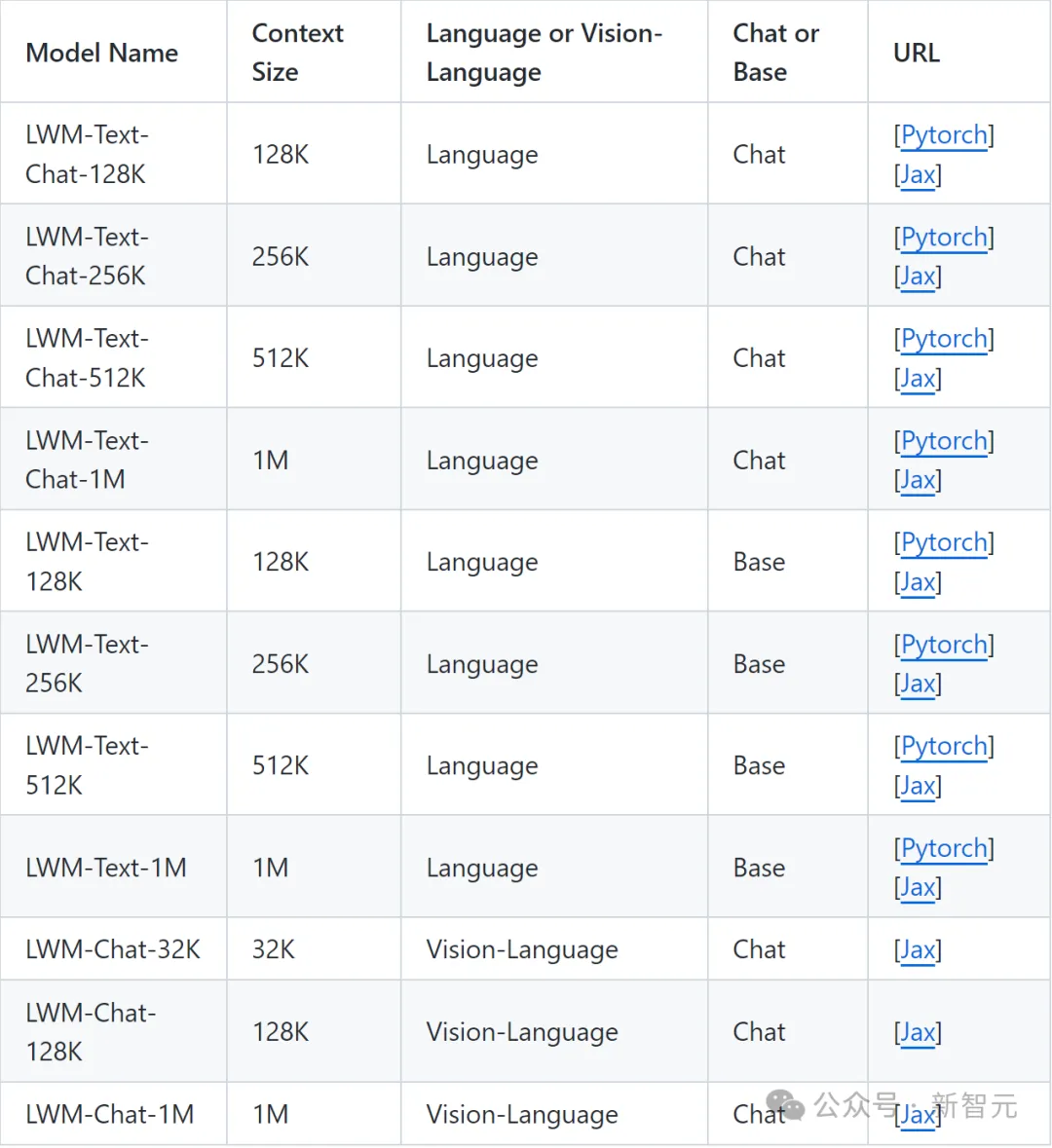
目前,LWM放出了一系列不同上下文大小(從32K到1M)的模型,包括純語言版本和視頻語言版本。其中視覺語言模型僅在Jax中可用,純語言模型在PyTorch和Jax中都可用。
開源技術(shù)細(xì)節(jié)
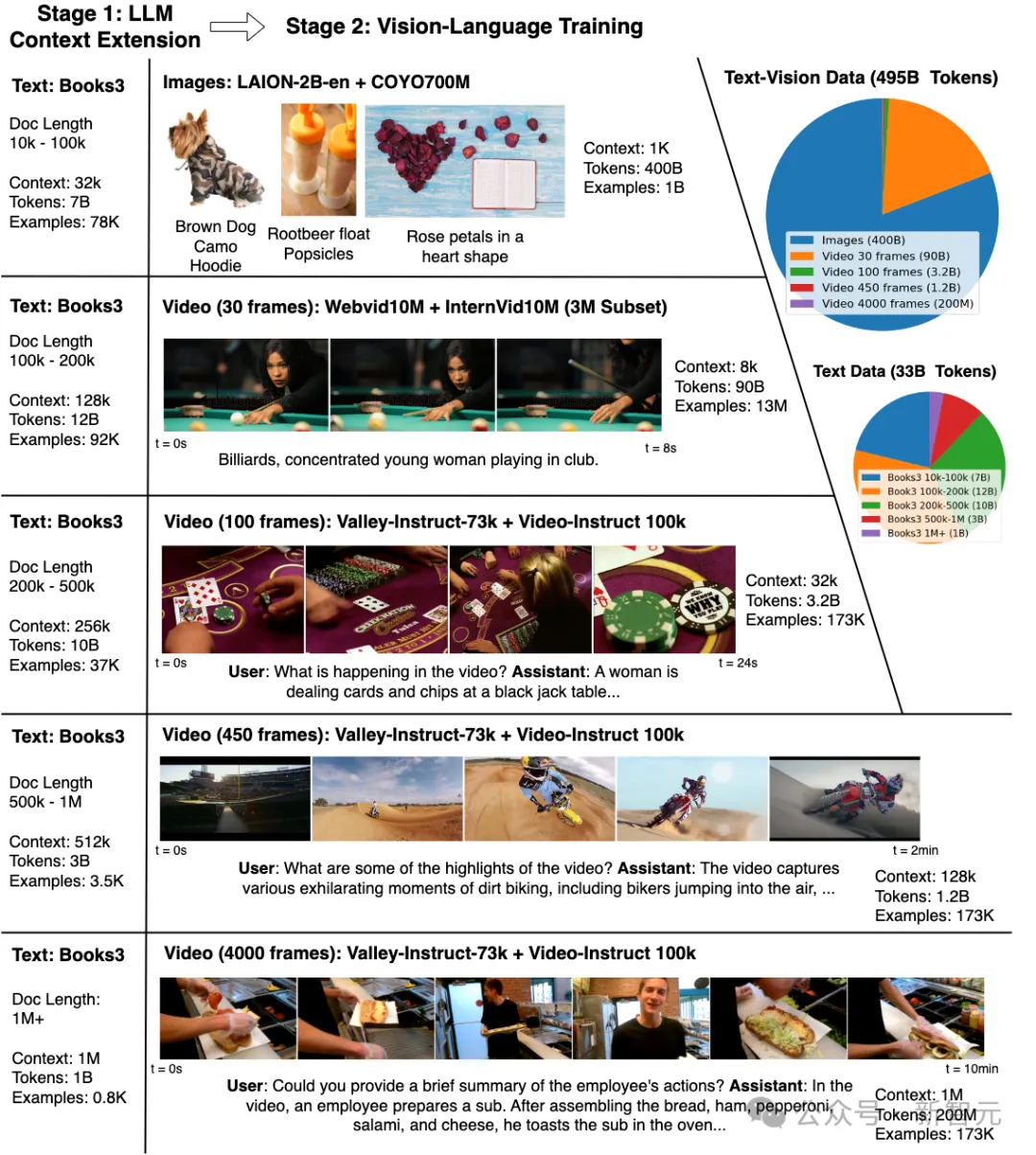
上圖展示了LWM的多模態(tài)訓(xùn)練。
第一階段是上下文擴展,重點是使用Books3數(shù)據(jù)集擴展上下文大小,從32K增長到1M。
第二階段,視覺語言培訓(xùn),重點是對不同長度的視覺和視頻內(nèi)容進行培訓(xùn)。餅圖詳細(xì)說明了訓(xùn)練數(shù)據(jù)的分布情況,包括495B的文本-視頻數(shù)據(jù),以及33B的文本數(shù)據(jù)。
圖中還展示了模型的交互功能。
語言模型階段
這個階段首先開發(fā)LWM-Text和LWM-Text-Chat,通過使用RingAttention逐步增加序列長度數(shù)據(jù)進行訓(xùn)練,并修改位置編碼參數(shù)以考慮更長的序列長度。
由于計算的二次復(fù)雜度所施加的內(nèi)存限制,對長文檔的訓(xùn)練非常昂貴。
為了解決計算限制,研究人員使用RingAttention,利用具有序列并行性的塊計算在理論上擴展到無限上下文,僅受可用設(shè)備數(shù)量的限制。
作者使用Pallas進一步將RingAttention與FlashAttention融合在一起,以優(yōu)化性能。通常,如果每個設(shè)備有足夠大的token,RingAttention期間的通信成本與計算完全重疊,并且不會增加任何額外的開銷。
訓(xùn)練步驟
模型以LLaMA-2 7B為基礎(chǔ),分5個階段逐步增加模型的有效上下文長度:32K、128K、256K、512K和1M。對于每個階段,使用來自The Pile的Books3數(shù)據(jù)集的不同過濾版本進行訓(xùn)練。
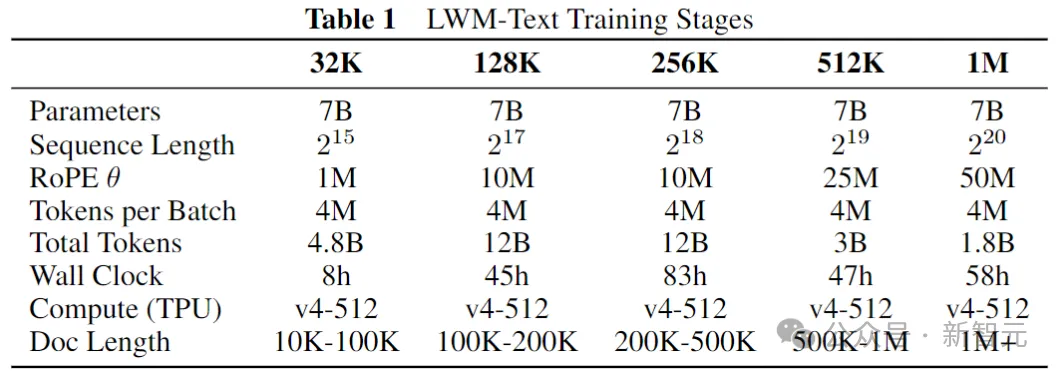
上表詳細(xì)介紹了每個訓(xùn)練階段的信息,例如token數(shù)量、總時間和Books3數(shù)據(jù)集過濾約束。每個階段以前一個階段作為初始化。
研究人員還構(gòu)建了一個簡單的QA數(shù)據(jù)集,用于學(xué)習(xí)長上下文聊天能力。將Books3數(shù)據(jù)集中的文檔分塊成1000個token的固定塊,將每個塊提供給短上下文語言模型,并提示它生成一個關(guān)于該段落的問答對。
對于聊天模型的微調(diào),研究人員在UltraChat和自定義QA數(shù)據(jù)集上訓(xùn)練每個模型,比例約為7:3。
作者發(fā)現(xiàn)將UltraChat數(shù)據(jù)預(yù)打包到訓(xùn)練序列長度至關(guān)重要,而且需要與自定義的QA數(shù)據(jù)示例分開。
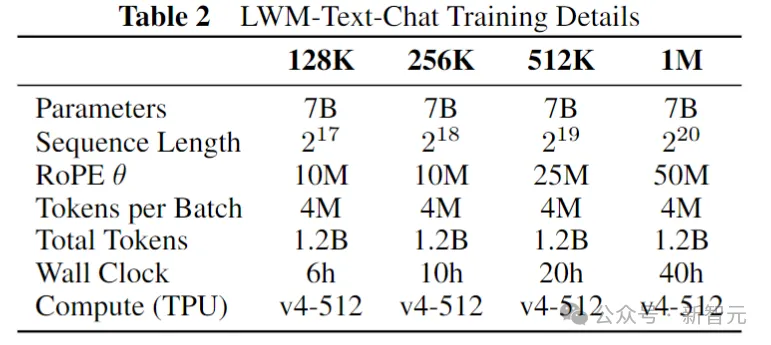
聊天模型并沒有采用漸進式訓(xùn)練,而是從各自的預(yù)訓(xùn)練模型以相同的上下文長度進行初始化。
視覺模型階段
第二階段旨在有效地聯(lián)合訓(xùn)練長視頻和語言序列。
LWM和LWM-Chat 的架構(gòu)修改
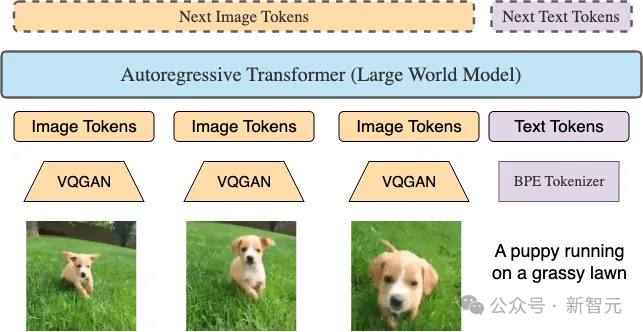
LWM是數(shù)百萬長標(biāo)記序列上的自回歸變換器。視頻中的每一幀都用VQGAN產(chǎn)生256個token。這些token與文本token連接起來,饋送到Transformer中,以自回歸方式預(yù)測下一個token。
輸入和輸出token的順序反映了不同的訓(xùn)練數(shù)據(jù)格式,包括圖像-文本、文本-圖像、視頻、文本-視頻和純文本格式。
LWM本質(zhì)上是使用多種模式以任意到任意方式進行訓(xùn)練的。為了區(qū)分圖像和文本token,以及進行解碼,這里采用特殊的分隔符。在視覺數(shù)據(jù)中,也會處理視頻的中間幀和最終幀。
這里使用來自aMUSEd的預(yù)訓(xùn)練VQGAN,將256 × 256個輸入圖像標(biāo)記為16 × 16個離散token。
模型使用視覺和文本token的交錯串聯(lián)進行訓(xùn)練,并進行自回歸預(yù)測。
不同序列長度的訓(xùn)練
以LWM-Text-1M文本模型為初始化,對大量組合的文本-圖像和文本-視頻數(shù)據(jù)執(zhí)行漸進式訓(xùn)練過程,這里沒有額外擴展RoPE θ,因為它已經(jīng)支持高達(dá)1M的上下文。
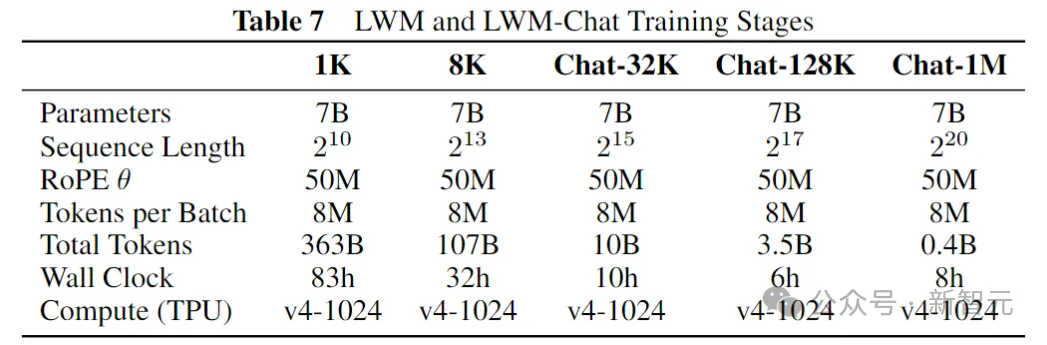
上表顯示了每個訓(xùn)練階段的詳細(xì)信息,每個模型是從先前較短的序列長度階段初始化的。
對于每個階段,根據(jù)以下數(shù)據(jù)進行訓(xùn)練:
LWM-1K:在大型文本圖像數(shù)據(jù)集上進行訓(xùn)練,該數(shù)據(jù)集由LAION-2Ben和COYO-700M混合組成。數(shù)據(jù)集被過濾后僅包含至少256分辨率的圖像——總共大約1B個文本圖像對。
在訓(xùn)練過程中,將文本-圖像對連接起來,并隨機交換模態(tài)的順序,以對文本-圖像生成、無條件圖像生成和圖像標(biāo)題進行建模。這里將文本-圖像對打包為1K個token的序列。
LWM-8K:在WebVid10M和3M InternVid10M示例的文本視頻數(shù)據(jù)集組合上進行訓(xùn)練。與之前的工作類似,每種模態(tài)使用相同的比例聯(lián)合訓(xùn)練圖像和視頻。
這里將圖像打包成8K token序列和30幀視頻,速度為4FPS。與圖像訓(xùn)練類似,隨機交換每個文本-視頻對的模態(tài)順序。
LWM-Chat-32K/128K/1M:在最后3個階段,研究人員對每個下游任務(wù)的聊天數(shù)據(jù)組合進行訓(xùn)練:
文本圖像生成
圖像理解
文本視頻生成
視頻理解
通過對預(yù)訓(xùn)練數(shù)據(jù)的隨機子集進行采樣,并用聊天格式進行增強,構(gòu)建了文本-圖像和文本-視頻聊天數(shù)據(jù)的簡單版本。為了理解圖像,這里使用來自ShareGPT4V的圖像聊天指示。
最后,對于視頻理解聊天數(shù)據(jù),使用Valley-Instruct-73K和Video-ChatGPT-100K指令數(shù)據(jù)的組合。對于所有短上下文數(shù)據(jù)(圖像生成、圖像理解、視頻生成),將序列打包到訓(xùn)練上下文長度。
在打包過程中,研究人員發(fā)現(xiàn)關(guān)鍵是要掩蓋注意力,以便每個文本視覺對只關(guān)注自己,以及重新加權(quán)損失,以使計算與非打包+填充訓(xùn)練方案中的訓(xùn)練相同。
對于視頻理解數(shù)據(jù),如果視頻太長,會統(tǒng)一采樣最大幀數(shù),以適應(yīng)模型的訓(xùn)練上下文長度。在訓(xùn)練期間,4 個下游任務(wù)等比例平均分配。
盡管視覺語言模型可以攝取長視頻,但由于上下文長度有限,通常是通過對視頻幀執(zhí)行大型時間子采樣來完成的。
例如,Video-LLaVA被限制為從視頻中均勻采樣8幀,無論原始視頻有多長。因此,模型可能會丟失更細(xì)粒度的時間信息,而這些信息對于準(zhǔn)確回答有關(guān)視頻的任何問題非常重要。

相比之下,本文的模型是在1M令牌的長序列上訓(xùn)練的,因此,可以同時處理數(shù)千幀視頻,以在短時間間隔內(nèi)檢索細(xì)粒度信息。在上圖的示例中,LWM正確回答了有關(guān)由500多個獨立剪輯組成的1小時長YouTube視頻的問題。
不過作者也承認(rèn),LWM生成的答案可能并不總是準(zhǔn)確的,并且該模型仍在努力解決需要對視頻有更高層次理解的更復(fù)雜的問題。希望LWM將有助于未來的工作,開發(fā)改進的基礎(chǔ)模型,以及長視頻理解的基準(zhǔn)。






























