為什么公共云的彈性能力很難被發揮出來?
王小瑞 AutoMQ 聯合創始人 & CEO
云計算通過資源池化實現單位資源成本更優,使企業能夠將 IDC 建設、基礎軟件研發和運維等工作外包給云廠商,從而更專注于業務創新。資源池不僅包括服務器,還包括人才。云廠商集聚了優秀工程師,通過云服務為眾多企業提供專業服務,讓專業的事交給最專業的人。
云計算發展這么多年,彈性是云計算從業者最關注的技術能力之一,但是真正落實到具體的案例上,很少有客戶能把彈性用好,彈性反而成為了一種口號,一種理想的架構,本文嘗試討論為什么現實和理想差距這么大,以及有哪些低投入高回報的彈性方案。
云廠商通過包年包月打折來留住客戶,與彈性場景相悖
下表是一份典型的包年包月 EC2 價格與按量付費價格對比,總結出來的游戲規則:
- 包年包月相比按量付費大約有 50% 的成本節省 這也是為什么大多數企業選擇包年包月方式來使用 EC2 資源。從云廠商的角度這么設計非常合理,因為云廠商是通過預測全網客戶的使用量來確定一個 Region 要預留多少空閑水位,假設 On Demand 和 Reserved 實例價格一致,將導致云廠商難以預測一個 Region 的水位,甚至會出現白天和晚上有巨大的差異,會直接影響供應鏈的采購決策。云廠商是典型的類零售商業模式,每個 Region 的空閑機器數量類比為庫存,庫存比例越高,會導致利潤率越低。
- Spot 實例恰好做到既便宜又是按小時付費 這也要求應用能處理好 Spot 實例被強制回收帶來的影響,對于無狀態應用相對簡單,Spot 實例在回收之前會通知應用,大部分云廠商會給到分鐘級別的回收窗口,應用只要做到優雅下線,就能做到對業務無影響。海外專業基于 Spot 實例來管理計算資源的創業公司[1],有大量的產品化功能幫助用戶用好 Spot 實例。 AutoMQ 公司也積累了豐富的 Spot 實例使用經驗[2]。但是對于有狀態應用,Spot 實例使用起來的門檻變得非常高,實例被強制回收前,就需要做到將狀態轉移。比如 Kafka,Redis,MySQL 這類應用。針對這類數據型的基礎軟件通常不建議用戶直接部署到 Spot 實例上。
這個游戲規則既有合理的地方也有值得優化的地方,筆者認為至少還可以在以下方面做的更好:
- Spot 回收機制提供 SLA 要能鼓勵更多用戶使用 Spot 實例,那么 Spot 的回收機制中的消息通知要能提供確定的 SLA,這樣一些關鍵業務就能敢于大規模使用 Spot 實例。
- 創建新實例 API 提供 SLA Spot 被回收后,應用的兜底方案是繼續開通新的資源(如新的 Spot 實例,或新的 On-demand 實例),這時開通新實例的 API 也要能有確定的 SLA,這個 SLA 會直接影響到應用的可用性。
- 卸載云盤提供 SLA Detach EBS 也要能有確定的 SLA,因為一旦發生強制回收 Spot 實例,要能允許用戶自動化處理好應用狀態卸載。
EC2 實例類型 | 價格/月 | 相對 On Demand 價格比例 |
On Demand | $56.210 | 100% |
Spot | $24.747 | 44% |
Reserved 1YR | $35.259 | 63% |
Reserved 3YR | $24.455 | 44% |
AWS US EAST m6g.large
程序員很難做好資源回收這件事情
C/C++ 程序員大量的精力在和內存作斗爭,但是仍然不能保證內存資源不泄露。原因是資源準確回收是一件極具挑戰的事情,比如一個函數返回一個指針,那么這個對象是誰負責回收,C/C++ 是沒有約定的,如果再涉及到多線程,則更加噩夢。為此 C++ 發明了智能指針,通過一個線程安全的引用計數來管理對象。Java 通過內置的 GC 機制,通過運行時來檢測對象回收,徹底解決了對象回收問題,不過也帶來了一定的運行時開銷。最近特別火的 Rust 語言,本質上也是類 C++ 的智能指針回收方式,創新性的將內存回收檢查機制做到了編譯階段,從而大幅提升了內存回收的效率,避免了 C/C++ 程序員常犯的內存問題,筆者認為 Rust 將是 C/C++ 的一個完美替代。
回到云操作系統這個領域,程序員可以通過一個 API 就能創建一臺 ECS,一個 Kafka 實例,一個 S3 Object,這個 API 背后帶來的是賬單的變化。創建容易,回收則變得非常困難。創建時候通常會指定最大規格,比如創建一個 Kafka 實例,先來 20 臺機器,因為未來擴容縮容都很困難,不如一次到位。
雖然云計算提供了彈性,但程序員難以有效地按需管理資源,導致資源回收困難。這促使企業在云上資源創建時設立繁瑣的審批流程,類似于傳統 IDC 的資源管理方式。最終導致的結果即程序員在云上使用資源的方式與 IDC 趨同,即需要通過 CMDB 進行資源管理,并依賴人工審批流程來避免資源浪費。
我們也看到了一些優秀的彈性實踐案例。例如某大型企業在使用 EC2 時,每個 EC2 的 Instance ID 存活周期不超過 1 個月,一旦超過, 就會被列為“爺爺輩的 EC2”,要上團隊的黑榜單。這是一個非常棒的不可變基礎設施實踐方法,能有效避免工程師在服務器上保留狀態,如配置,數據等,從而讓應用走向彈性架構變得可行。
當前云計算的階段還處在 C/C++ 階段,還沒有出現優秀的資源回收解決方案,所以企業還在大量使用流程審批機制,實質上導致了企業無法發揮云的最大優勢:彈性。這也是導致企業云支出較高的主要原因之一。
相信只要有問題,一定會有更優秀的解法,解決云資源回收的類 Java/Rust 方案一定會在不久的將來問世。
從基礎軟件到應用層,還沒有為彈性做好準備
筆者曾在 2018 年開始為淘寶天貓的數千個應用設計彈性方案[3],當時淘寶天貓的應用已經做到了離線和在線混部來提升部署密度,但是在線應用仍然為預留模式,無法做到按需彈性。根本問題還是應用在擴縮時,可能會產生非預期的行為,即使運行在 Kubernetes 之上,仍然不能徹底解決,如應用會調用各種中間件的 SDK(數據庫、緩存、MQ、業務緩存等),應用本身啟動也消耗時間較長,看似無狀態的應用,實則也包含了各種狀態,如包括單元標簽,灰度標簽等,讓整個應用需要大量的人工操作,人工觀察才能有效擴縮容。
為了讓 Java 應用從分鐘級的冷啟動提升到毫秒級,當時為 Docker 開發了 Snapshot 能力[3],這項能力的生產應用足足比 AWS 領先了 4 年(AWS 于 2022 年 Re:invent 會議上發布了 Lambda SnapStart[4][5] 特性)。通過 Snapshot 方式啟動應用可以數百毫秒就能增加一臺可以立刻工作的計算節點,這項能力讓應用不需要改造成 Lambda 函數方式就能做到像 Lambda 一樣,根據流量來增減計算資源,也就是我們看到的 Lambda 提供的 Pay as you go 能力。
應用層做彈性已經如此復雜,到了基礎軟件做彈性挑戰更大,如數據庫、緩存、MQ、大數據等產品。分布式高可用高可靠的要求決定了這些產品都需要將數據存儲多副本。一旦數據量大,彈性將變得非常困難,遷移數據會影響業務的可用性。為此,要在云環境解決這個問題,就要用云原生的方式,我們在設計 AutoMQ(賦能 Kafka 的云原生方案)時,將彈性作為最高優先級,核心挑戰是要將存儲卸載到云服務,例如按量付費的 S3,而不是自建存儲系統。下圖是 AutoMQ 線上的流量和節點變化圖,會看到 AutoMQ 是根據流量全自動增減機器,如果這些機器采用 Spot 實例,將為企業節省大量的成本,真正做到 Pay as you go。
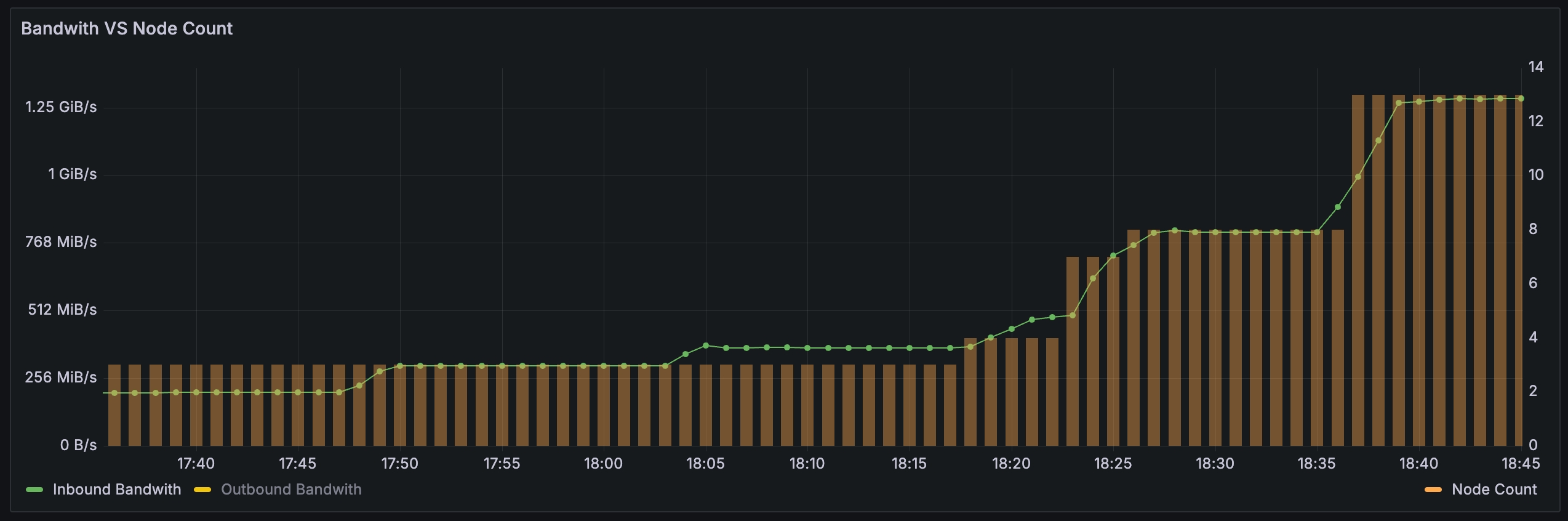
AutoMQ 根據流量自動增減節點
企業如何使用好彈性能力來降本增效
Google 在 2018 年推出了 Cloud Run[6] 全托管式計算平臺,基于 HTTP 通信的應用僅需提供監聽端口和容器鏡像給 Cloud run,所有基礎設施的管理將全自動由 Cloud run 來執行。這種方式相比 AWS Lambda 方式最大優勢是無需綁定到單個云廠商,未來可以更好的遷移到其他計算平臺。很快 AWS 和 Azure 跟進推出了類似的產品,Azure Container Apps[7] 和 AWS App Runner[8]。
專業的事情交給專業的人做,彈性是一個非常有挑戰的工作,推薦云上的應用可以盡可能依賴這些無代碼綁定托管框架,如 Cloud run,做到應用消耗的計算資源可以按照請求來付費。
基礎軟件如數據庫、緩存、大數據、MQ 等,很難用一個統一的托管框架來解決,這類應用的演進趨勢是每個品類都在向彈性架構演進,如 Amazon Aurora Serverless,Mongodb Serverless[9],從云廠商到第三方開源軟件商都有共識要能走到徹底的彈性架構。
企業在選擇類似開源基礎軟件時,要盡可能選擇具備彈性能力的產品,判斷的標準是是否能運行在 Spot 實例上,是否能極具性價比。同時也要關注這類產品是否能更好的在多個云上運行,這決定了企業在未來走向多云架構,甚至混合云架構時,是否具備移植性。