













超越BEVFusion!DifFUSER:擴散模型殺入自動駕駛多任務(BEV分割+檢測雙SOTA)
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
目前,隨著自動駕駛技術的越發成熟以及自動駕駛感知任務需求的日益增多,工業界和學術界非常希望一個理想的感知算法模型,可以同時完成如3D目標檢測以及基于BEV空間的語義分割在內的多個感知任務。對于一輛能夠實現自動駕駛功能的車輛而言,其通常會配備環視相機傳感器、激光雷達傳感器以及毫米波雷達傳感器來采集不同模態的數據信息,從而充分利用不同模態數據之間的互補優勢,比如三維的點云數據可以為3D目標檢測任務提供算法模型必要的幾何數據和深度信息;2D的圖像數據可以為基于BEV空間的語義分割任務提供至關重要的色彩和語義紋理信息,通過將不同模態數據的有效結果,使得部署在車上的多模態感知算法模型輸出更加魯棒和準確的空間感知結果。
雖然最近在學術界和工業界提出了許多基于Transformer網絡框架的多傳感、多模態數據融合的3D感知算法,但均采用了Transformer中的交叉注意力機制來實現多模態數據之間的融合,以實現比較理想的3D目標檢測結果。但是這類多模態的特征融合方法并不完全適用于基于BEV空間的語義分割任務。此外,除了采用交叉注意力機制來完成不同模態之間信息融合的方法外,很多算法采用基于LSS中前向的2D到3D的視角轉換方式來構建融合后的特征,但也存在著如下的一些問題:
- 由于目前提出的相關多模態融合的3D感知算法,對于不同模態數據特征的融合方式設計的還不夠充分,造成感知算法模型無法準確捕獲到傳感器數據之間的復雜連接關系,進而影響模型的最終感知性能。
- 不同傳感器采集數據的過程中難免會引入無關的噪聲信息,這種不同模態之間的內在噪聲,也會導致不同模態特征融合的過程中會混入噪聲,從而造成多模態特征融合的不準確,影響后續的感知任務。
針對上述提到的在多模態融合過程中存在的諸多可能會影響到最終模型感知性能的問題,同時考慮到生成模型最近展現出來的強大性能,我們對生成模型進行了探索,用于實現多傳感器之間的多模態融合和去噪任務。基于此,我們提出了一種基于條件擴散的生成模型感知算法DifFUSER,用于實現多模態的感知任務。通過下圖可以看出,我們提出的DifFUSER多模態數據融合算法可以實現更加有效的多模態融合過程。
提出的算法模型與其它算法模型的結果可視化對比圖
論文鏈接:https://arxiv.org/pdf/2404.04629.pdf
網絡模型的整體架構&細節梳理
在詳細介紹本文提出的基于條件擴散模型的多任務感知算法的DifFUSER的模塊細節之前,下圖展示了我們提出的DifFUSER算法的整體網絡結構。
 提出的DifFUSER感知算法模型網絡結構圖
提出的DifFUSER感知算法模型網絡結構圖
通過上圖可以看出,我們提出的DifFUSER網絡結構主要包括三個子網絡,分別是主干網絡部分、DifFUSER的多模態數據融合部分以及最終的BEV語義分割、3D目標檢測感知任務頭部分。
- 主干網絡部分:該部分主要對網絡模型輸入的2D圖像數據以及3D的激光雷達點云數據進行特征提取用于輸出相對應的BEV語義特征。對于提取圖像特征的主干網絡而言,主要包括2D的圖像主干網絡以及視角轉換模塊。對于提取3D的激光雷達點云特征的主干網絡而言,主要包括3D的點云主干網絡以及特征Flatten模塊。
- DifFUSER多模態數據融合部分:我們提出的DifFUSER模塊以層級的雙向特征金字塔網絡的形式鏈接在一起,我們把這樣的結構稱為cMini-BiFPN。該結構為潛在的擴散提供了可以替代的結構,可以更好的處理來自不同傳感器數據中的多尺度和寬高詳細特征信息。
- BEV語義分割、3D目標檢測感知任務頭部分:由于我們的算法模型可以同時輸出3D目標檢測結果以及BEV空間的語義分割結果,所以3D感知任務頭包括3D檢測頭以及語義分割頭。此外,我們提出的算法模型涉及到的損失則包括擴散損失、檢測損失和語義分割損失,通過將所有損失進行求和,并通過反向傳播的方式來更新網絡模型的參數。
接下來,我們會仔細介紹模型中各個主要子部分的實現細節。
融合架構設計(Conditional-Mini-BiFPN,cMini-BiFPN)
對于自動駕駛系統中的感知任務而言,算法模型能夠對當前的外部環境進行實時的感知是至關重要的,所以確保擴散模塊的性能和效率是非常重要的。因此,我們從雙向特征金字塔網絡中得到啟發,引入一種條件類似的BiFPN擴散架構,我們稱之為Conditional-Mini-BiFPN,其具體的網絡結構如上圖所示。


漸進傳感器Dropout訓練(PSDT)
對于一輛自動駕駛汽車而言,配備的自動駕駛采集傳感器的性能至關重要,在自動駕駛車輛日常行駛的過程中,極有可能會出現相機傳感器或者激光雷達傳感器出現遮擋或者故障的問題,從而影響最終自動駕駛系統的安全性以及運行效率。基于這一考慮出發,我們提出了漸進式的傳感器Dropout訓練范式,用于增強提出的算法模型在傳感器可能被遮擋等情況下的魯棒性和適應性。
通過我們提出的漸進傳感器Dropout訓練范式,可以使得算法模型通過利用相機傳感器以及激光雷達傳感器采集到的兩種模態數據的分布,重建缺失的特征,從而實現了在惡劣狀況下的出色適應性和魯棒性。具體而言,我們利用來自圖像數據和激光雷達點云數據的特征,以三種不同的方式進行使用,分別是作為訓練目標、擴散模塊的噪聲輸入以及模擬傳感器丟失或故障的條件,為了模擬傳感器丟失或故障的條件,我們在訓練期間逐漸將相機傳感器或激光雷達傳感器輸入的丟失率從0增加到預定義的最大值a=25。整個過程可以用下面的公式進行表示:

其中,代表當前模型所處的訓練輪數,通過定義dropout的概率用于表示特征中每個特征被丟棄的概率。通過這種漸進式的訓練過程,不僅訓練模型有效去噪并生成更具有表現力的特征,而且還最大限度地減少其對任何單個傳感器的依賴,從而增強其處理具有更大彈性的不完整傳感器數據的能力。
門控自條件調制擴散模塊(GSM Diffusion Module)

具體而言,門控自條件調制擴散模塊的網絡結構如下圖所示

門控自條件調制擴散模塊網絡結構示意圖

實驗結果&評價指標
定量分析部分
為了驗證我們提出的算法模型DifFUSER在多任務上的感知結果,我們主要在nuScenes數據集上進行了3D目標檢測以及基于BEV空間的語義分割實驗。
首先,我們比較了提出的算法模型DifFUSER與其它的多模態融合算法在語義分割任務上的性能對比情況,具體的實驗結果如下表所示:
 不同算法模型在nuScenes數據集上的基于BEV空間的語義分割任務的實驗結果對比情況
不同算法模型在nuScenes數據集上的基于BEV空間的語義分割任務的實驗結果對比情況
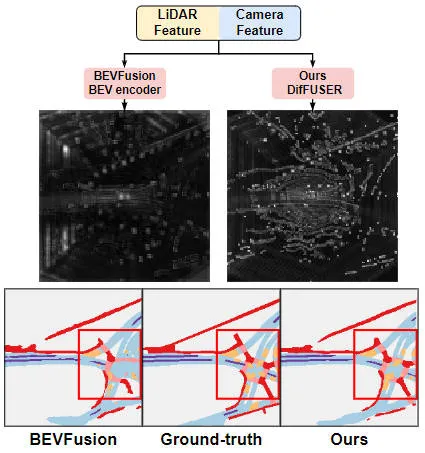
通過實驗結果可以看出,我們提出的算法模型相比于基線模型而言在性能上有著顯著的提高。具體而言,BEVFusion模型的mIoU值只有62.7%,而我們提出的算法模型已經達到了69.1%,具有6.4%個點的提升,這表明我們提出的算法在不同類別上都更有優勢。此外,下圖也更加直觀的說明了我們提出的算法模型更具有優勢。具體而言,BEVFusion算法會輸出較差的分割結果,尤其在遠距離的場景下,傳感器錯位的情況更加明顯。與之相比,我們的算法模型具有更加準確的分割結果,細節更加明顯,噪聲更少。

提出算法模型與基線模型的分割可視化結果對比
此外,我們也將提出的算法模型與其它的3D目標檢測算法模型進行對比,具體的實驗結果如下表所示

不同算法模型在nuScenes數據集上的3D目標檢測任務的實驗結果對比情況
通過表格當中列出的結果可以看出,我們提出的算法模型DifFUSER相比于基線模型在NDS和mAP指標上均有提高,相比于基線模型BEVFusion的72.9%NDS以及70.2%的mAP,我們的算法模型分別要高出1.8%以及1.0%。相關指標的提升表明,我們提出的多模態擴散融合模塊對特征的減少和特征的細化過程是有效的。
此外,為了表明我們提出的算法模型在傳感器故障或者遮擋情況下的感知魯棒性,我們進行了相關分割任務的結果比較,如下圖所示。

不同情況下的算法性能比較
通過上圖可以看出,在采樣充足的情況下,我們提出的算法模型可以有效的對缺失特征進行補償,用于作為缺失傳感器采集信息的替代內容。我們提出的DifFUSER算法模型生成和利用合成特征的能力,有效地減輕了對任何單一傳感器模態的依賴,確保模型在多樣化和具有挑戰性的環境中能夠平穩運行。
定性分析部分
下圖展示了我們提出的DifFUSER算法模型在3D目標檢測以及BEV空間的語義分割結果的可視化,通過可視化結果可以看出,我們提出的算法模型具有很好的檢測和分割效果。

結論
本文提出了一個基于擴散模型的多模態感知算法模型DifFUSER,通過改進網絡模型的融合架構以及利用擴散模型的去噪特性來提高網絡模型的融合質量。通過在Nuscenes數據集上的實驗結果表明,我們提出的算法模型在BEV空間的語義分割任務中實現了SOTA的分割性能,在3D目標檢測任務中可以和當前SOTA的算法模型取得相近的檢測性能。






























