Meta訓(xùn)AI,成本已超阿波羅登月!谷歌豪言投資超千億美元,賽過OpenAI星際之門
就在剛剛,Meta AI主管Yann LeCun證實(shí):為了買英偉達(dá)GPU,Meta已經(jīng)花了300億美元,這個(gè)成本,已經(jīng)超過了阿波羅登月計(jì)劃!

300億美元雖然驚人,但比起微軟和OpenAI計(jì)劃打造的1000億美元星際之門,這還是小case了。
谷歌DeepMind CEO Hassabis甚至放話稱:谷歌要砸進(jìn)的數(shù),比這個(gè)還多。
這才哪到哪呢。

LeCun:Meta買英偉達(dá)GPU,的確超過阿波羅登月
為了發(fā)展AI,Meta是破釜沉舟了。
在這個(gè)訪談中,主持人問道:據(jù)說Meta購(gòu)入了50萬塊英偉達(dá)GPU,按照市價(jià)算的話,這個(gè)價(jià)格是300億美元。所以,整個(gè)成本比阿波羅登月項(xiàng)目話要高,對(duì)嗎?
對(duì)此,LeCun表示承認(rèn):是的,的確如此。
他補(bǔ)充道,「不僅是訓(xùn)練,還包括部署的成本。我們面臨的最大問題,就是GPU的供給問題。」
有人提出質(zhì)疑,認(rèn)為這應(yīng)該不是真的。作為史上最大的推理組織,他們應(yīng)該不是把所有的錢都花在了訓(xùn)練上。
也有人戳破了這層泡沫,表示每個(gè)巨頭都在撒謊,以此營(yíng)造「自己擁有更多GPU」的假象——
雖然的確在英偉達(dá)硬件上投入大量資金,但其實(shí)只有一小部分用于實(shí)際訓(xùn)練模型。「我們擁有數(shù)百萬個(gè)GPU」的概念,就是聽起來好吹牛罷了。

當(dāng)然,也有人提出質(zhì)疑:考慮通貨膨脹,阿波羅計(jì)劃的成本應(yīng)該是接近2000-2500億美元才對(duì)。

的確,有人經(jīng)過測(cè)算,考慮阿波羅計(jì)劃1969年的原始價(jià)值、根據(jù)通貨膨脹進(jìn)行調(diào)整的話,它的總成本應(yīng)該在2170億或2410億美元。
 https://apollo11space.com/apollo-program-costs-new-data-1969-vs-2024/
https://apollo11space.com/apollo-program-costs-new-data-1969-vs-2024/
而沃頓商學(xué)院教授Ethan Mollick表示,雖然遠(yuǎn)不及阿波羅計(jì)劃,但以今天的美元計(jì)算,Meta在GPU上的花費(fèi)幾乎與曼哈頓計(jì)劃一樣多。

不過至少,網(wǎng)友們表示,很高興對(duì)巨頭的AI基礎(chǔ)設(shè)施有了一瞥:電能、土地、可容納100萬個(gè)GPU的機(jī)架。
開源Llama 3大獲成功
此外,在Llama 3上,Meta也斬獲了亮眼的成績(jī)。
在Llama 3的開發(fā)上,Meta團(tuán)隊(duì)主要有四個(gè)層面的考量:

模型架構(gòu)
架構(gòu)方面,團(tuán)隊(duì)采用的是稠密自回歸Transformer,并在模型中加入了分組查詢注意力(GQA)機(jī)制,以及一個(gè)新的分詞器。
訓(xùn)練數(shù)據(jù)和計(jì)算資源
由于訓(xùn)練過程使用了超過15萬億的token,因此團(tuán)隊(duì)自己搭建了兩個(gè)計(jì)算集群,分別具有24000塊H100 GPU。
指令微調(diào)
實(shí)際上,模型的效果主要取決于后訓(xùn)練階段,而這也是最耗費(fèi)時(shí)間精力的地方。
為此,團(tuán)隊(duì)擴(kuò)大了人工標(biāo)注SFT數(shù)據(jù)的規(guī)模(1000萬),并且采用了諸如拒絕采樣、PPO、DPO等技術(shù),來嘗試在可用性、人類特征以及預(yù)訓(xùn)練中的大規(guī)模數(shù)據(jù)之間找到平衡。
如今,從最新出爐的代碼評(píng)測(cè)來看,Meta團(tuán)隊(duì)的這一系列探索可以說是大獲成功。
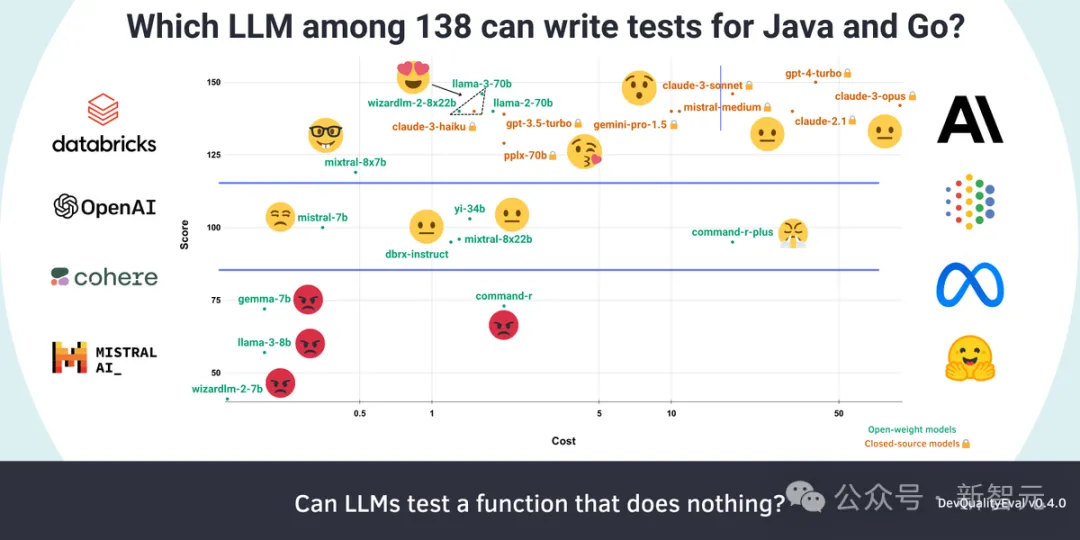
Symflower首席技術(shù)官兼創(chuàng)始人Markus Zimmermann在對(duì)GPT-3.5/4、Llama 3、Gemini 1.5 Pro、Command R+等130多款LLM進(jìn)行了全面評(píng)測(cè)之后表示:「大語言模型的王座屬于Llama 3 70B!」
- 在覆蓋率上達(dá)到100%,在代碼質(zhì)量上達(dá)到70%
- 性價(jià)比最高的推理能力
- 模型權(quán)重開放

不過值得注意的是,GPT-4 Turbo在性能方面是無可爭(zhēng)議的贏家——拿下150分滿分。
可以看到,GPT-4(150分,40美元/百萬token)和Claude 3 Opus(142分,90美元/百萬token)性能確實(shí)很好,但在價(jià)格上則要比Llama、Wizard和Haiku高了25到55倍。
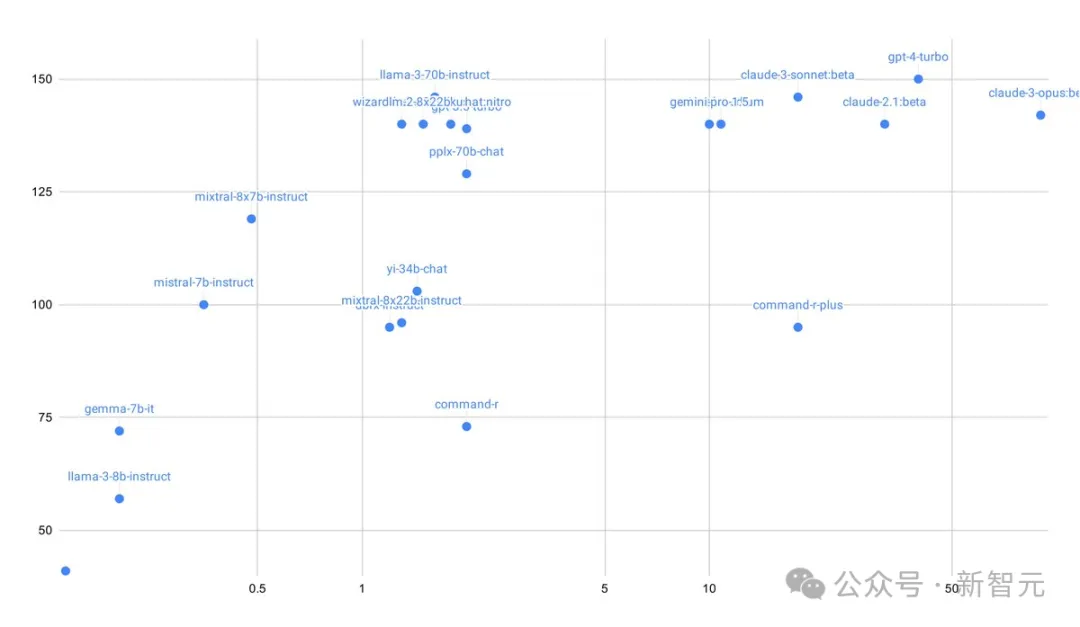
具體來說,在Java中,Llama 3 70B成功識(shí)別出了一個(gè)不容易發(fā)現(xiàn)的構(gòu)造函數(shù)測(cè)試用例,這一發(fā)現(xiàn)既出人意料又有效。
此外,它還能70%的時(shí)間編寫出高質(zhì)量的測(cè)試代碼。
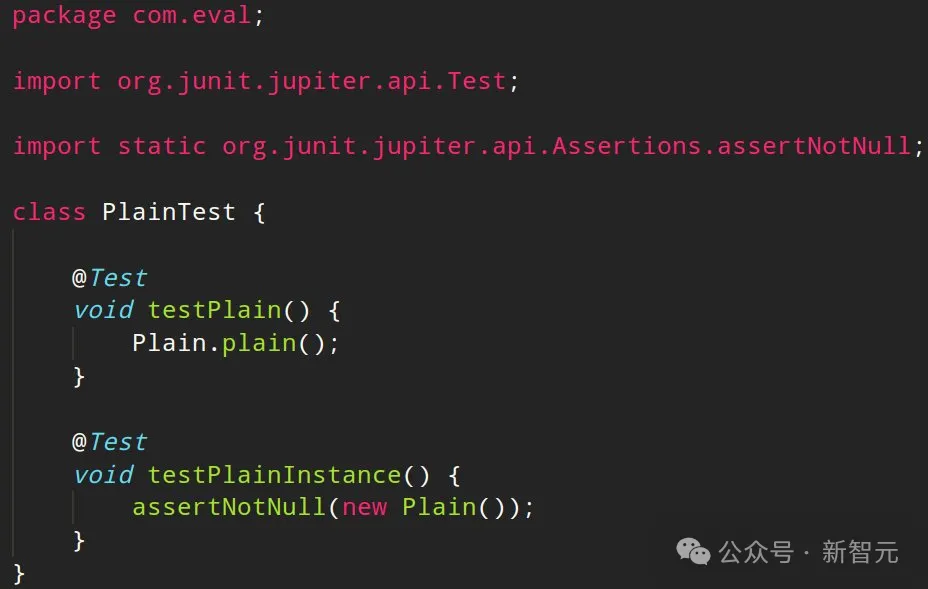
GPT-4 Turbo在生成測(cè)試代碼時(shí)傾向于加入一些明顯的注釋,但這在高質(zhì)量的代碼編寫中通常是需要避免的。

測(cè)試代碼的質(zhì)量大大受到微調(diào)的影響:在性能測(cè)試中,WizardLM-2 8x22B比Mixtral 8x22B-Instruct高出30%。
在生成可編譯代碼的能力方面,較小參數(shù)的模型如Gemma 7B、Llama 3 8B和WizardLM 2 7B表現(xiàn)不佳,但Mistral 7B卻做得很好。

團(tuán)隊(duì)在評(píng)估了138款LLM之后發(fā)現(xiàn),其中有大約80個(gè)模型連生成簡(jiǎn)單測(cè)試用例的能力都不可靠。
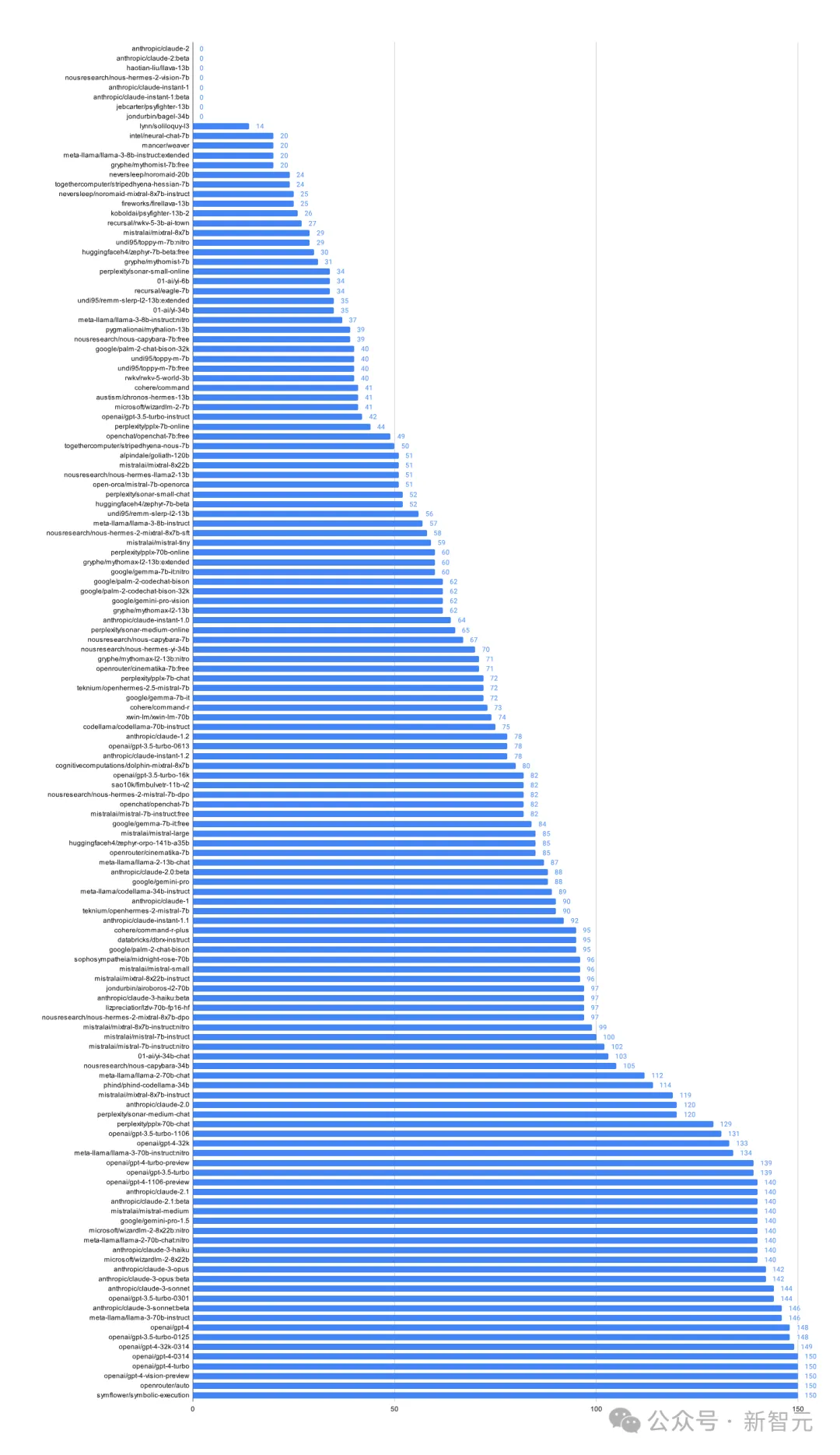
如果得分低于85分,就意味著模型的表現(xiàn)不盡如人意。不過,上圖并未完全反映評(píng)測(cè)中的全部發(fā)現(xiàn)和見解,團(tuán)隊(duì)預(yù)計(jì)將在下個(gè)版本中進(jìn)行補(bǔ)充
詳細(xì)評(píng)測(cè)可進(jìn)入下面這篇文章查看:

評(píng)測(cè)地址:https://symflower.com/en/company/blog/2024/dev-quality-eval-v0.4.0-is-llama-3-better-than-gpt-4-for-generating-tests/
想要贏得人工智能戰(zhàn)爭(zhēng),代價(jià)昂貴到慘烈
如今,各大科技公司都在付出昂貴的代價(jià),爭(zhēng)取打贏這場(chǎng)AI戰(zhàn)爭(zhēng)。
讓AI變得更智能,科技巨頭們需要花費(fèi)多少資金?
谷歌DeepMind老板Demis Hassabis在半個(gè)月前的TED大會(huì)上做出了預(yù)測(cè):在開發(fā)AI方面,谷歌預(yù)計(jì)投入1000多億美元。

作為谷歌人工智能計(jì)劃最中心、最靈魂的人物,DeepMind實(shí)驗(yàn)室的領(lǐng)導(dǎo)者,Hassabis的這番言論,也表達(dá)了對(duì)OpenAI的毫不示弱。
根據(jù)The Information報(bào)道,微軟和OpenAI計(jì)劃花1000億美元打造「星際之門」,這臺(tái)超算預(yù)計(jì)包含數(shù)百萬個(gè)專用服務(wù)器芯片,為GPT-5、GPT-6等更高級(jí)的模型提供動(dòng)力。

當(dāng)Hassabis被問及競(jìng)爭(zhēng)對(duì)手花在超算上的巨額成本時(shí),他輕描淡寫地指出:谷歌的花費(fèi)可能會(huì)超出這個(gè)數(shù)字。
我們現(xiàn)在不談具體的數(shù)字,不過我認(rèn)為,隨著時(shí)間的推移,我們的投資會(huì)超過這個(gè)數(shù)。
如今,生成式AI的熱潮已經(jīng)引發(fā)了巨大的投資熱。
根據(jù)Crunchbase的數(shù)據(jù),僅AI初創(chuàng)企業(yè),去年就籌集了近500億美元的資金。
而Hassabis的發(fā)言表明,AI領(lǐng)域的競(jìng)爭(zhēng)絲毫沒有放緩的意思,還將更加白熱化。
谷歌、微軟、OpenAI,都在為「第一個(gè)到達(dá)AGI」這一壯舉,展開激烈角逐。
1000億美元的瘋狂數(shù)字
在AI技術(shù)上要花掉超千億美元,這1000億都花會(huì)花在哪里呢?
首先,開發(fā)成本的大頭,就是芯片。
目前這一塊,英偉達(dá)還是說一不二的老大。谷歌Gemini和OpenAI的GPT-4 Turbo,很大程度上還是依賴英偉達(dá)GPU等第三方芯片。

模型的訓(xùn)練成本,也越來越昂貴。
斯坦福此前發(fā)布的年度AI指數(shù)報(bào)告就指出:「SOTA模型的訓(xùn)練成本,已經(jīng)達(dá)到前所未有的水平。」
報(bào)告數(shù)據(jù)顯示,GPT-4使用了「價(jià)值約7800萬美元的計(jì)算量來進(jìn)行訓(xùn)練」,而2020年訓(xùn)練GPT-3使用的計(jì)算量,僅為430萬美元。
與此同時(shí),谷歌Gemini Ultra的訓(xùn)練成本為1.91億美元。
而AI模型背后的原始技術(shù),在2017年的訓(xùn)練成本僅為900美元。
報(bào)告還指出:AI模型的訓(xùn)練成本與其計(jì)算要求之間存在直接關(guān)聯(lián)。
如果目標(biāo)是AGI的話,成本很可能會(huì)直線上升。
1.9億美元:從谷歌到OpenAI,訓(xùn)練AI模型的成本是多少
說到這里,就讓我們盤一盤,各大科技公司訓(xùn)練AI模型所需的成本,究竟是多少。
最近的《人工智能指數(shù)報(bào)告》,就披露了訓(xùn)練迄今為止最復(fù)雜的AI模型所需要的驚人費(fèi)用。
讓我們深入研究這些成本的細(xì)分,探討它們的含義。
Transformer(谷歌):930美元
Transformer模型是現(xiàn)代AI的開創(chuàng)性架構(gòu)之一,這種相對(duì)適中的成本,凸顯了早期AI訓(xùn)練方法的效率。
它的成本,可以作為了解該領(lǐng)域在模型復(fù)雜性和相關(guān)費(fèi)用方面進(jìn)展的基準(zhǔn)。
BERT-Large(谷歌):3,288美元
與前身相比,BERT-Large模型的訓(xùn)練成本大幅增加。
BERT以其對(duì)上下文表征的雙向預(yù)訓(xùn)練而聞名,在自然語言理解方面取得了重大進(jìn)展。然而,這一進(jìn)展是以更高的財(cái)務(wù)成本為代價(jià)的。
RoBERTa Large(Meta):160美元
RoBERTa Large是BERT的一個(gè)變體,針對(duì)穩(wěn)健的預(yù)訓(xùn)練進(jìn)行了優(yōu)化,其訓(xùn)練成本的躍升,反映了隨著模型變得越來越復(fù)雜,計(jì)算需求也在不斷提高。
這一急劇增長(zhǎng),凸顯了與突破人工智能能力界限相關(guān)費(fèi)用在不斷上升。
LaMDA (谷歌): $1.3M美元
LaMDA旨在進(jìn)行自然語言對(duì)話,代表了向更專業(yè)的AI應(yīng)用程序的轉(zhuǎn)變。
訓(xùn)練LaMDA所需的大量投資,凸顯了對(duì)為特定任務(wù)量身定制的AI模型需求的不斷增長(zhǎng),后者就需要更廣泛的微調(diào)和數(shù)據(jù)處理。
GPT-3 175B(davinci)(OpenAI):$4.3M
GPT-3以其龐大的規(guī)模和令人印象深刻的語言生成能力而聞名,代表了AI發(fā)展的一個(gè)重要里程碑。
訓(xùn)練GPT-3的成本,反映了訓(xùn)練如此規(guī)模的模型所需的巨大算力,突出了性能和可負(fù)擔(dān)性之間的權(quán)衡。
Megatron-Turing NLG 530B (微軟/英偉達(dá)): $6.4M
訓(xùn)練Megatron-TuringNLG的成本,說明了具有數(shù)千億個(gè)參數(shù)的更大模型的趨勢(shì)。
這種模型突破了AI能力的界限,但帶來了驚人的訓(xùn)練成本。它大大提高了門檻,讓業(yè)領(lǐng)導(dǎo)者和小型參與者之間的差距越拉越大。
PaLM(540B)(谷歌):$12.4M
PaLM具有大量的參數(shù),代表了AI規(guī)模和復(fù)雜性的巔峰之作。
訓(xùn)練PaLM的天文數(shù)字成本,顯示出推動(dòng)AI研發(fā)界限所需的巨大投資,也引發(fā)了人們的質(zhì)疑:這類投資真的是可持續(xù)的嗎?
GPT-4 (OpenAI): $78.3M
GPT-4的預(yù)計(jì)訓(xùn)練成本,也標(biāo)志著人工智能經(jīng)濟(jì)學(xué)的范式轉(zhuǎn)變——AI模型的訓(xùn)練費(fèi)用達(dá)到了前所未有的水平。
隨著模型變得越來越大、越來越復(fù)雜,進(jìn)入的經(jīng)濟(jì)壁壘也在不斷升級(jí)。此時(shí),后者就會(huì)限制創(chuàng)新,和人們對(duì)AI技術(shù)的可得性。
Gemini Ultra(谷歌):$191.4M
訓(xùn)練Gemini Ultra的驚人成本,體現(xiàn)了超大規(guī)模AI模型帶來的挑戰(zhàn)。
雖然這些模型表現(xiàn)出了突破性的能力,但它們的訓(xùn)練費(fèi)用已經(jīng)達(dá)到了天文數(shù)字。除了資金最充足的大公司之外,其余的企業(yè)和組織都被擋在了壁壘之外。
芯片競(jìng)賽:微軟、Meta、谷歌和英偉達(dá)爭(zhēng)奪AI芯片霸主地位
雖然英偉達(dá)憑借長(zhǎng)遠(yuǎn)布局在芯片領(lǐng)域先下一城,但無論是AMD這個(gè)老對(duì)手,還是微軟、谷歌、Meta等巨頭,也都在奮勇直追,嘗試采用自己的設(shè)計(jì)。

5月1日,AMD的MI300人工智能芯片銷售額達(dá)到10億美元,成為其有史以來銷售最快的產(chǎn)品。
與此同時(shí),AMD還在馬不停蹄地加大目前供不應(yīng)求的AI芯片的產(chǎn)量,并且預(yù)計(jì)在2025年推出新品。

4月10日,Meta官宣下一代自研芯片,模型訓(xùn)練速度將獲巨大提升。
Meta訓(xùn)練和推理加速器(MTIA)專為與Meta的排序和推薦模型配合使用而設(shè)計(jì),這些芯片可以幫助提高訓(xùn)練效率,并使實(shí)際的推理任務(wù)更加容易。
同在4月10日,英特爾也透露了自家最新的AI芯片——Gaudi 3 AI的更多細(xì)節(jié)。
英特爾表示,與H100 GPU相比,Gaudi 3可以在推理性能上獲得50%提升的同時(shí),在能效上提升40%,并且價(jià)格更便宜。
3月19日,英偉達(dá)發(fā)布了「地表最強(qiáng)」AI芯片——Blackwell B200。
英偉達(dá)表示,全新的B200 GPU可以憑借著2080億個(gè)晶體管,提供高達(dá)20 petaflops的FP4算力。
不僅如此,將兩個(gè)這樣的GPU與一個(gè)Grace CPU結(jié)合在一起的GB200,可以為L(zhǎng)LM推理任務(wù)提供比之前強(qiáng)30倍的性能,同時(shí)也可大大提高效率。
此外,老黃還曾暗示每個(gè)GPU的價(jià)格可能在3萬到4萬美元之間。
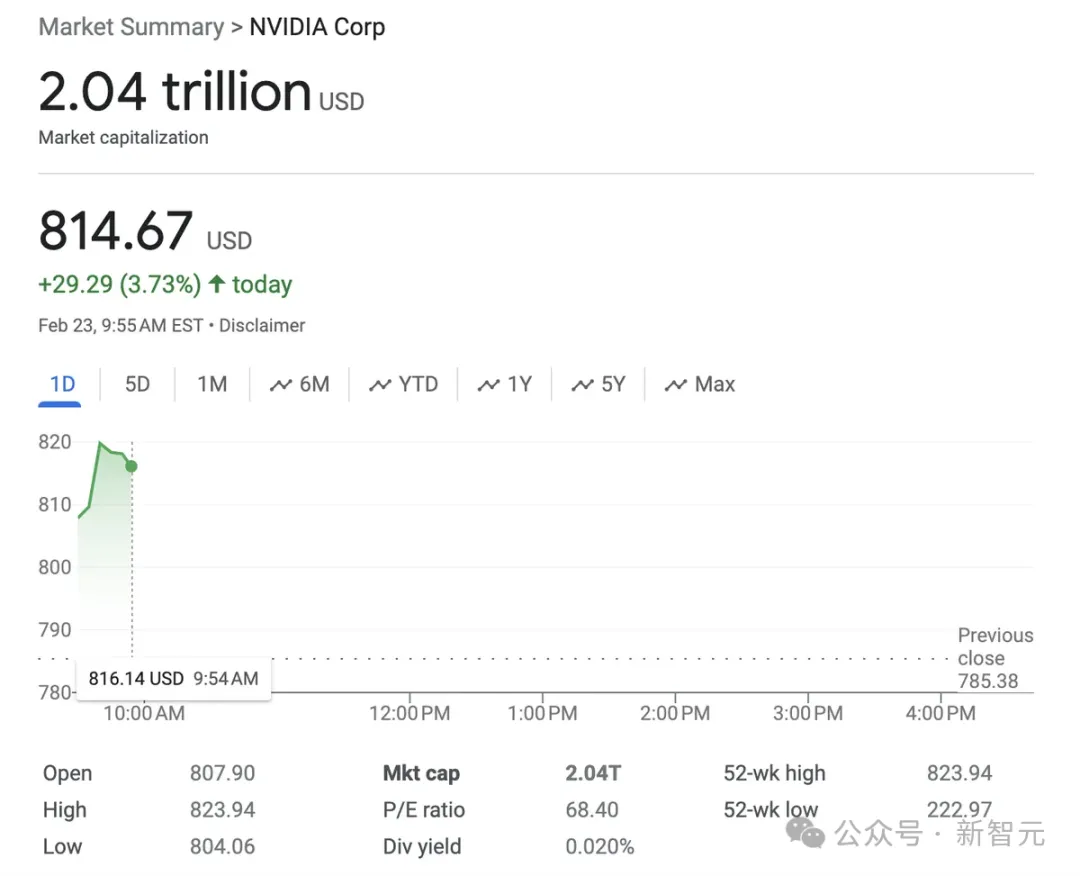
2月23日,英偉達(dá)市值一舉突破2萬億美元,成為了首家實(shí)現(xiàn)這一里程碑的芯片制造商。
同時(shí),這也讓英偉達(dá)成為了美國(guó)第三家市值超過2萬億美元的公司,僅次于蘋果(2.83萬億美元)和微軟(3.06萬億美元)。
2月22日,微軟和英特爾達(dá)成了一項(xiàng)數(shù)十億美元的定制芯片交易。
據(jù)推測(cè),英特爾將會(huì)為微軟生產(chǎn)其自研的AI芯片。

2月9日,《華爾街日?qǐng)?bào)》稱Sam Altman的AI芯片夢(mèng),可能需要高達(dá)7萬億美元的投資。
「這樣一筆投資金額將使目前全球半導(dǎo)體行業(yè)的規(guī)模相形見絀。去年全球芯片銷售額為5270億美元,預(yù)計(jì)到2030年將達(dá)到每年1萬億美元。」