挑戰OpenAI,微軟自研5000億參數絕密武器曝光!前谷歌DeepMind高管帶隊
不需要OpenAI,微軟或許也會成為AI領頭羊!
外媒Information爆料稱,微軟內部正在開發自家首款5000億參數的大模型MAl-1。

這恰好是,納德拉帶領團隊證明自己的時候到了。
在向OpenAI投資100多億美元之后,微軟才獲得了GPT-3.5/GPT-4先進模型的使用權,但終究不是長久之計。
甚至,此前有傳言稱,微軟已經淪落為OpenAI的一個IT部門。
在過去的一年,每個人熟知的,微軟在LLM方面的研究,主要集中在小體量phi的更新,比如Phi-3的開源。
而在大模型的專攻上,除了圖靈系列,微軟內部還未透露半點風聲。
就在今天,微軟首席技術官Kevin Scott證實,MAI大模型確實正在開發中。

顯然,微軟秘密籌備大模型的計劃,是為了能夠開發出一款全新LLM,能夠與OpenAI、谷歌、Anthropic頂尖模型競爭。
畢竟,納德拉曾說過,「如果OpenAI明天消失了,也無關緊要」。
「我們有的是人才、有的是算力、有的是數據,我們什么都不缺。我們在他們之下,在他們之上,在他們周圍」。

看來,微軟的底氣,就是自己。

自研5000億MAI-1大模型
據介紹,MAI-1大模型由前谷歌DeepMind負責人Mustafa Suleyman,負責監督。
值得一提的是,Suleyman在加入微軟之前,還是AI初創Inflection AI創始人兼CEO。
創辦于2022年,一年的時間,他帶領團隊推出了大模型Inflection(目前已更新到了2.5版本),以及日活破百萬的高情商AI助手Pi。
不過因為無法找到正確的商業模式,Suleyman和另一位聯創,以及大部分員工,在3月份共同加入微軟。

也就是說,Suleyman和團隊負責這個新項目MAI-1,會為此帶來更多的前沿大模型的經驗。
還是要提一句,MAI-1模型是微軟自研發的,并非從Inflection模型繼承而來。
據兩位微軟員工稱,「MAI-1與Inflection之前發布的模型不同」。不過,訓練過程可能會用到其訓練數據和技術。
擁有5000億參數,MAI-1的參數規模將遠遠超出,微軟以往訓練的任何小規模開源模型。
這也意味著,它將需要更多的算力、數據,訓練成本也是高昂的。
為了訓練這款新模型,微軟已經預留了一大批配備英偉達GPU的服務器,并一直在編制訓練數據以優化模型。
其中,包括來自GPT-4生成的文本,以及外部來源(互聯網公共數據)的各種數據集。
大小模型,我都要
相比之下,GPT-4曾被曝出有1.8萬億參數,Meta、Mistral等AI公司發布較小開源模型,則有700億參數。
當然,微軟采取的是多管齊下的策略,即大小模型一起研發。
其中,最經典的便是Phi-3了——一個能夠塞進手機的小模型,而且最小尺寸3.8B性能碾壓GPT-3.5。

Phi-3 mini在量化到4bit的情況下,僅占用大約1.8GB的內存,用iPhone14每秒可生成12個token。
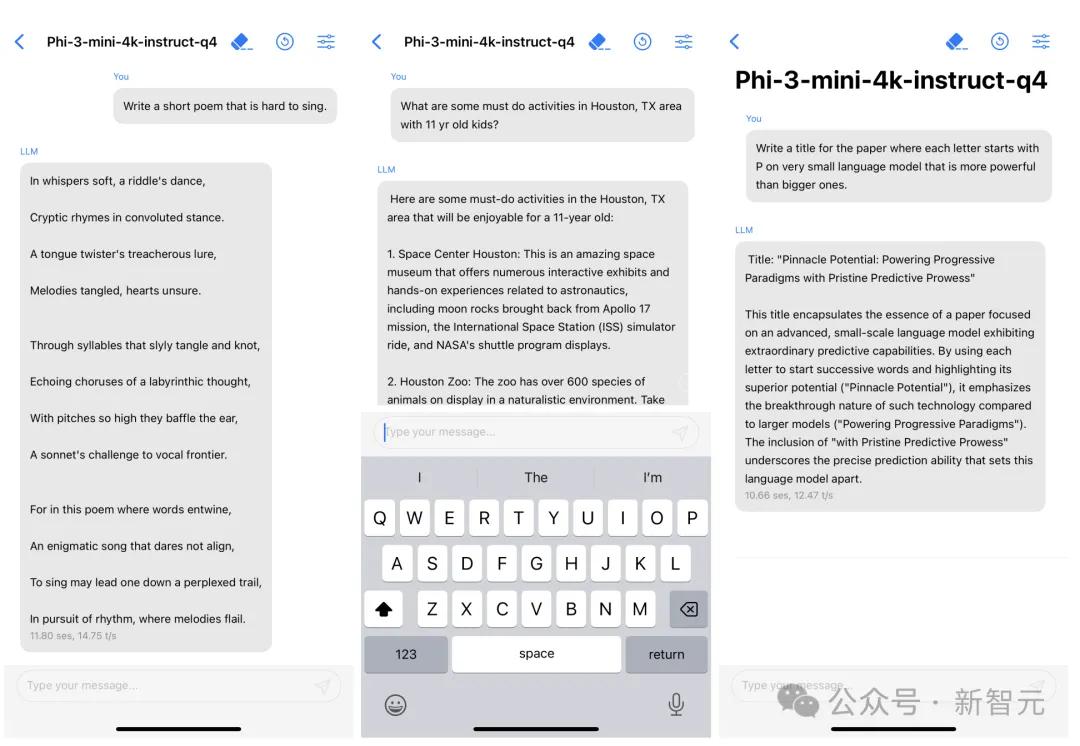
在網友拋出「應該用更低成本訓練AI,不是更好嗎」的問題后,Kevin Scott回復到:
這并不是一個非此即彼的關系。在許多AI應用中,我們結合使用大型前沿模型和更小、更有針對性的模型。我們做了大量工作,確保SLM在設備上和云中都能很好地運作。我們在訓練SLM方面積累了大量經驗,甚至還將其中一些工作開源,供他人研究和使用。我認為,在可預見的未來,這種大與小的結合還將繼續下去。

這表明,微軟既要開發成本低廉、可集成到應用中,并能在移動設備上運行的SLM,也要開發更大、更先進的AI模型。
目前,微軟自稱是一家「Copilot公司」。得到AI加持的Copilot聊天機器人,可以完成撰寫電子郵件、快速總結文件等任務。
而未來,下一步的機會在哪?
大小模型兼顧,正體現了充滿創新活力的微軟,更愿意探索AI的新路徑。
不給OpenAI當「IT」了?
話又說回來,自研MAI-1,并不意味著微軟將會拋棄OpenAI。
首席技術官Kevin Scott在今早的帖子中首先,肯定了微軟與OpenAI合作五年的堅固「友誼」。
我們一直在為合作伙伴OpenAI建造大型超算,來訓練前沿的AI模型。然后,兩家都會將模型,應用到自家的產品和服務中,讓更多的人受益。
而且,每一代新的超算都將比上一代,更加強大,因此OpenAI訓出的每個前沿模型,都要比上一個更加先進。
我們將繼續沿著這條路走下去——不斷構建更強大的超算,讓OpenAI能夠訓練出引領整個行業的模型。我們的合作將會產生越來越大的影響力。
前段時間,外媒曝出了,微軟和OpenAI聯手打造AI超算「星際之門」,將斥資高達1150億美元。
據稱,最快將在2028年推出超算,并在2030年之前進一步擴展。

包括此前,微軟工程師向創業者Kyle Corbitt爆料稱,微軟正在緊鑼密鼓地建設10萬個H100,以供OpenAI訓練GPT-6。

種種跡象表明,微軟與OpenAI之間合作,只會更加牢固。
此外,Scott還表示,「除了與OpenAI的合作,微軟多年來一直都在讓MSR和各產品團隊開發AI模型」。
AI模型幾乎深入到了,微軟的所有產品、服務和運營過程中。團隊們有時也需要進行定制化工作,不論是從零開始訓模型,還是對現有模型進行微調。
未來,還會有更多類似的這樣的情況。
這些模型中,一些被命名為Turing、MAI等,還有的命名為Phi,我們并將其開源。
雖然我的表達可能沒有那么引人注目,但這是現實。對于我們這些極客來說,鑒于這一切在實踐中的復雜性,這是一個非常令人興奮的現實。
解密「圖靈」模型
除了MAI、Phi系列模型,代號「Turing」是微軟在2017年在內部開啟的計劃,旨在打造一款大模型,并應用到所有產品線中。

經過3年研發,他們在2020年首次發布170億參數的T-NLG模型,創當時有史以來最大參數規模的LLM記錄。

到了2021年,微軟聯手英偉達發布了5300億參數的Megatron-Turing(MT-NLP),在一系列廣泛的自然語言任務中表現出了「無與倫比」的準確性。

同年,視覺語言模型Turing Bletchley首次面世。
去年8月,該多模態模型已經迭代到了V3版本,而且已經整合進Bing等相關產品中,以提供更出色的圖像搜索體驗。

此外,微軟還在2021年和2022年發布了「圖靈通用語言表示模型」——T-ULRv5和T-ULRv6兩個版本。
目前,「圖靈」模型已經用在了,Word中的智能查詢(SmartFind),Xbox中的問題匹配(Question Matching)上。
還有團隊研發的圖像超分辨率模型Turing Image Super-Resolution(T-ISR),已在必應地圖中得到應用,可以為全球用戶提高航空圖像的質量。

目前,MAI-1新模型具體會在哪得到應用,還未確定,將取決于其性能表現。
順便提一句,關于MAI-1更多的信息,可能會在5月21日-23日微軟Build開發者大會上首次展示。
接下來,就是坐等MAI-1發布了。