LidaRF:研究用于街景神經輻射場的激光雷達數據(CVPR'24)
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
光真實感模擬在自動駕駛等應用中發揮著關鍵作用,其中神經輻射場(NeRFs)的進步可能通過自動創建數字3D資產來實現更好的可擴展性。然而,由于街道上相機運動的高度共線性和在高速下的稀疏采樣,街景的重建質量受到影響。另一方面,該應用通常需要從偏離輸入視角的相機視角進行渲染,以準確模擬如變道等行為。LidaRF提出了幾個見解,允許更好地利用激光雷達數據來改善街景中NeRF的質量。首先,框架從激光雷達數據中學習幾何場景表示,這些表示與基于隱式網格的輻射解碼表示相結合,從而提供了由顯式點云提供的更強幾何信息。其次,提出了一種魯棒的遮擋感知深度監督方案,允許通過累積使用密集的激光雷達點。第三,根據激光雷達點生成增強的訓練視角,以進一步改進,方法在真實駕駛場景下的新視角合成中取得了顯著改進。
LidaRF的貢獻主要體現在三個方面:
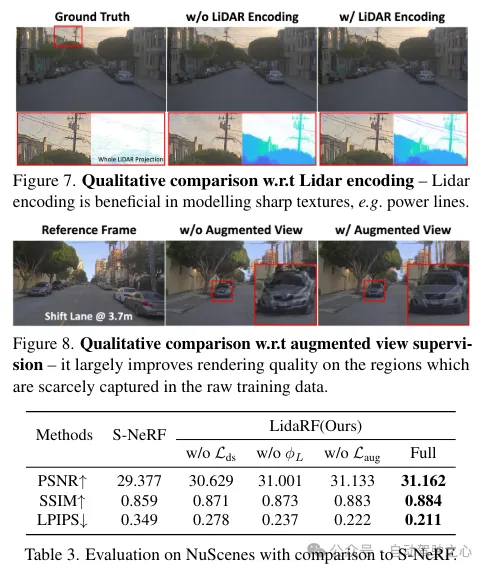
(i)融合激光雷達編碼和網格特征以增強場景表示。雖然激光雷達已被用作自然的深度監督源,但將激光雷達納入NeRF輸入中,為幾何歸納偏置提供了巨大的潛力,但實現起來并不簡單。為此,采用了基于網格的表示法,但將從點云中學習的特征融合到網格中,以繼承顯式點云表示法的優勢。受到3D感知框架成功的啟發,利用3D稀疏卷積網絡作為一種有效且高效的架構,從激光雷達點云的局部和全局上下文中提取幾何特征。
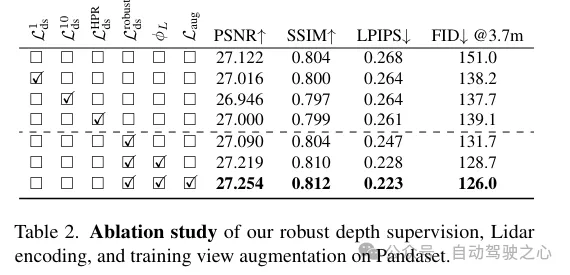
(ii)魯棒的遮擋感知深度監督。與現有工作類似,這里也使用激光雷達作為深度監督的來源,但更加深入。由于激光雷達點的稀疏性限制了其效用,尤其是在低紋理區域,通過跨鄰近幀密集化激光雷達點來生成更密集的深度圖。然而,這樣獲得的深度圖沒有考慮到遮擋,產生了錯誤的深度監督。因此,提出了一種健壯的深度監督方案,采用class學習的方式——從近場到遠場逐步監督深度,并在NeRF訓練過程中逐漸過濾掉錯誤的深度,從而更有效地從激光雷達中學習深度。
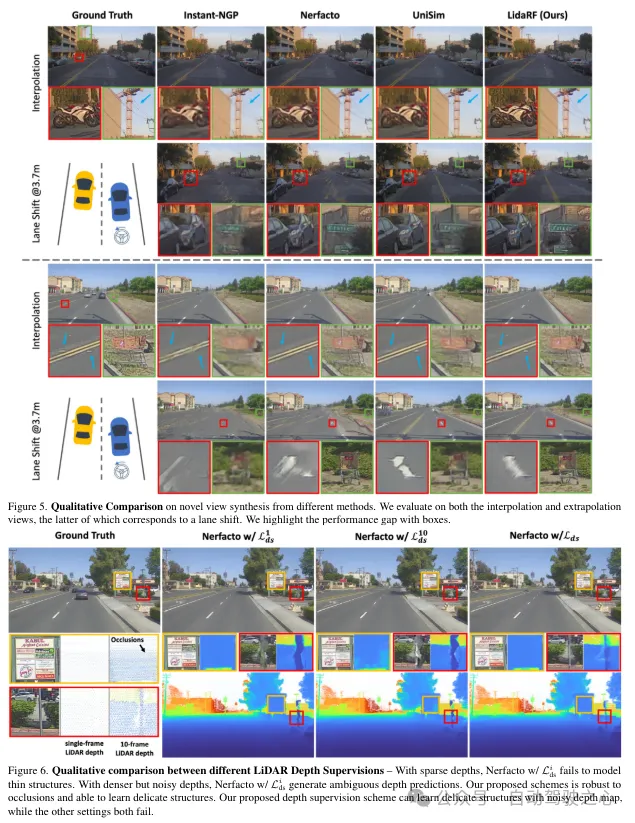
(iii)基于激光雷達的視圖增強。此外,鑒于駕駛場景中的視圖稀疏性和覆蓋有限,利用激光雷達來密集化訓練視圖。也就是說,將累積的激光雷達點投影到新的訓練視圖中;請注意,這些視圖可能與駕駛軌跡有一定的偏離。這些從激光雷達投影的視圖被添加到訓練數據集中,它們并沒有考慮到遮擋。然而,我們應用了前面提到的監督方案來解決遮擋問題,從而提高了性能。雖然我們的見解也適用于一般場景,但在這項工作中,更專注于街道場景的評估,與現有技術相比,無論是定量還是定性,都取得了顯著的改進。
LidaRF在需要更大程度偏離輸入視圖的有趣應用(如變道)中也顯示出優勢,在具有挑戰性的街道場景應用中顯著提高了NeRF的質量。
LidaRF整體框架一覽
LidaRF概述如下所示,它以采樣的3D位置x和射線方向d作為輸入,并輸出對應的密度α和顏色c。它采用稀疏UNet融合了哈希編碼和激光雷達編碼。此外,通過激光雷達投影生成增強的訓練數據,并使用提出的健壯深度監督方案訓練幾何預測。

1)激光雷達編碼的混合表示法
激光雷達點云具有強大的幾何指導潛力,這對NeRF(神經輻射場)來說極具價值。然而,僅依賴激光雷達特征來進行場景表示,由于激光雷達點的稀疏性(盡管有時間累積),會導致低分辨率的渲染。此外,由于激光雷達的視野有限,例如它不能捕獲超過一定高度的建筑物表面,因此在這些區域中會出現空白渲染。相比之下,本文的框架融合了激光雷達特征和高分辨率的空間網格特征,以利用兩者的優勢,并共同學習以實現高質量和完整的場景渲染。
激光雷達特征提取。在這里詳細描述了每個激光雷達點的幾何特征提取過程,參照圖2,首先將整個序列的所有幀的激光雷達點云聚合起來,以構建更密集的點云集合。然后將點云體素化為體素網格,其中每個體素單元內的點的空間位置進行平均,為每個體素單元生成一個3維特征。受到3D感知框架廣泛成功的啟發,在體素網格上使用3D稀疏UNet對場景幾何特征進行編碼,這允許從場景幾何的全局上下文中學習。3D稀疏UNet將體素網格及其3維特征作為輸入,并輸出neural volumetric 特征,每個被占用的體素由n維特征組成。
激光雷達特征查詢。對于沿著要渲染的射線上的每個樣本點x,如果在搜索半徑R內有至少K個附近的激光雷達點,則查詢其激光雷達特征;否則,其激光雷達特征被設置為空(即全零)。具體來說,采用固定半徑最近鄰(FRNN)方法來搜索與x相關的K個最近的激光雷達點索引集,記作。與[9]中在啟動訓練過程之前預先確定射線采樣點的方法不同,本文的方法在執行FRNN搜索時是實時的,因為隨著NeRF訓練的收斂,來自region網絡的樣本點分布會動態地趨向于集中在表面上。遵循Point-NeRF的方法,我們的方法利用一個多層感知機(MLP)F,將每個點的激光雷達特征映射到神經場景描述中。對于x的第i個鄰近點,F將激光雷達特征和相對位置作為輸入,并輸出神經場景描述作為:
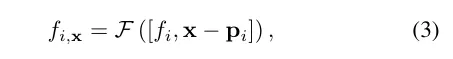
為了獲得采樣位置x處的最終激光雷達編碼?,使用標準的反距離權重法來聚合其K個鄰近點的神經場景描述

輻射解碼的特征融合。將激光雷達編碼?L與哈希編碼?h進行拼接,并應用一個多層感知機Fα來預測每個樣本的密度α和密度嵌入h。最后,通過另一個多層感知機Fc,根據觀察方向d的球面諧波編碼SH和密度嵌入h來預測相應的顏色c。
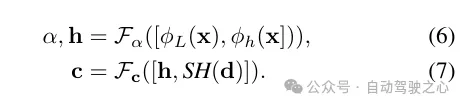
2)魯棒深度監督
除了特征編碼外,還通過將激光雷達點投影到圖像平面上來從它們中獲取深度監督。然而,由于激光雷達點的稀疏性,所得益處有限,不足以重建低紋理區域,如路面。在這里,我們提出累積相鄰的激光雷達幀以增加密度。盡管3D點能夠準確地捕獲場景結構,但在將它們投影到圖像平面以進行深度監督時,需要考慮點之間的遮擋。遮擋是由于相機與激光雷達及其相鄰幀之間的位移增加而產生的,從而產生虛假的深度監督,如圖3所示。由于即使累積后激光雷達的稀疏性,處理這個問題也非常困難,使得諸如z緩沖之類的基本原理圖形技術無法應用。在這項工作中,提出了一種魯棒的監督方案,以在訓練NeRF時自動過濾掉虛假的深度監督。

遮擋感知的魯棒監督方案。本文設計了一個class訓練策略,使得模型最初使用更近、更可靠的深度數據進行訓練,這些數據更不容易受到遮擋的影響。隨著訓練的進行,模型逐漸開始融合更遠的深度數據。同時,模型還具備了丟棄與其預測相比異常遙遠的深度監督的能力。
回想一下,由于車載攝像頭的向前運動,它產生的訓練圖像是稀疏的,視野覆蓋有限,這給NeRF重建帶來了挑戰,尤其是當新視圖偏離車輛軌跡時。在這里,我們提出利用激光雷達來增強訓練數據。首先,我們通過將每個激光雷達幀的點云投影到其同步的攝像頭上并為RGB值進行插值來為其上色。累積上色的點云,并將其投影到一組合成增強的視圖上,生成如圖2所示的合成圖像和深度圖。
實驗對比分析