













百萬(wàn)tokens低至1元!大模型越來(lái)越卷了
在剛剛舉行的 ICLR 2024 大會(huì)上,智譜AI的大模型技術(shù)團(tuán)隊(duì)公布了面向激動(dòng)人心的AGI通用人工智能前景的三大技術(shù)趨勢(shì),同時(shí)預(yù)告了GLM的后續(xù)升級(jí)版本。
前天,智譜大模型開(kāi)放平臺(tái)(bigmodel.cn)上線了新的價(jià)格體系。入門級(jí)產(chǎn)品 GLM-3 Turbo 模型調(diào)用價(jià)格下調(diào)80%!從5元/百萬(wàn)tokens降至1元/百萬(wàn)tokens。1元可以購(gòu)買100萬(wàn)tokens。
調(diào)整后,使用GLM-3 Turbo創(chuàng)作一萬(wàn)條小紅書(shū)文案(以350字計(jì))將僅需約1元錢,足以讓更多企業(yè)和個(gè)人都能用上這款入門級(jí)產(chǎn)品。
來(lái)自智譜AI開(kāi)放平臺(tái)官網(wǎng)
除了降價(jià),官方還特別提供用戶 tokens 優(yōu)惠計(jì)劃——從今天起,新注冊(cè)開(kāi)放平臺(tái)用戶贈(zèng)送額度提升500%。開(kāi)放平臺(tái)新注冊(cè)用戶獲贈(zèng)從500 萬(wàn)tokens提升至2500萬(wàn)tokens(包含2000萬(wàn)入門級(jí)額度和500萬(wàn)企業(yè)級(jí)額度)。
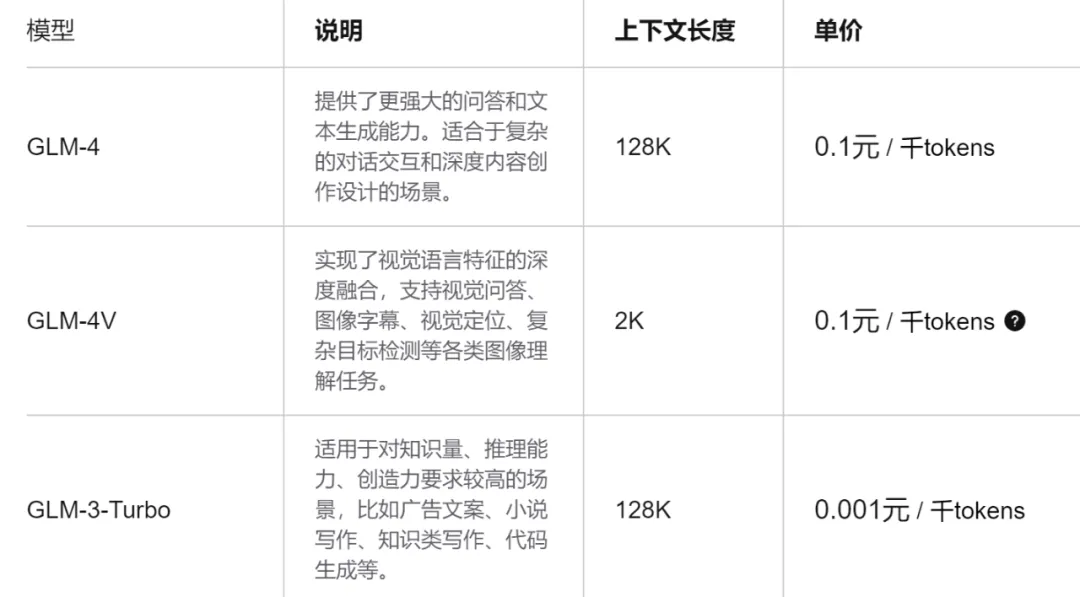
GLM-3 Turbo(最大支持 128k)是大模型開(kāi)放平臺(tái)最受歡迎的模型產(chǎn)品,不僅速度快,而且適用于對(duì)知識(shí)量、推理能力、創(chuàng)造力要求較高的場(chǎng)景,此次調(diào)價(jià)后更具競(jìng)爭(zhēng)力,國(guó)內(nèi)其他128k級(jí)別大模型的調(diào)用價(jià)格大多從百萬(wàn)tokens數(shù)元到幾十元不等。
企業(yè)級(jí)產(chǎn)品 GLM-4/GLM-4V 價(jià)格仍維持在 0.1元/千 tokens,百萬(wàn)tokens的價(jià)格為100元,但作為一款能力逼近GPT-4的國(guó)內(nèi)領(lǐng)先大模型,這一價(jià)格還是比較能打。從公開(kāi)的API 調(diào)用收費(fèi)來(lái)看,OpenAI 最新模型 GPT-4 Turbo 每100萬(wàn)tokens輸入/輸出價(jià)格分別是10/30美元。Claude 3 Opus 更貴,每百萬(wàn)tokens輸入/輸出價(jià)格15/75美元。如果折合成人民幣,這些數(shù)字至少還要乘以7。
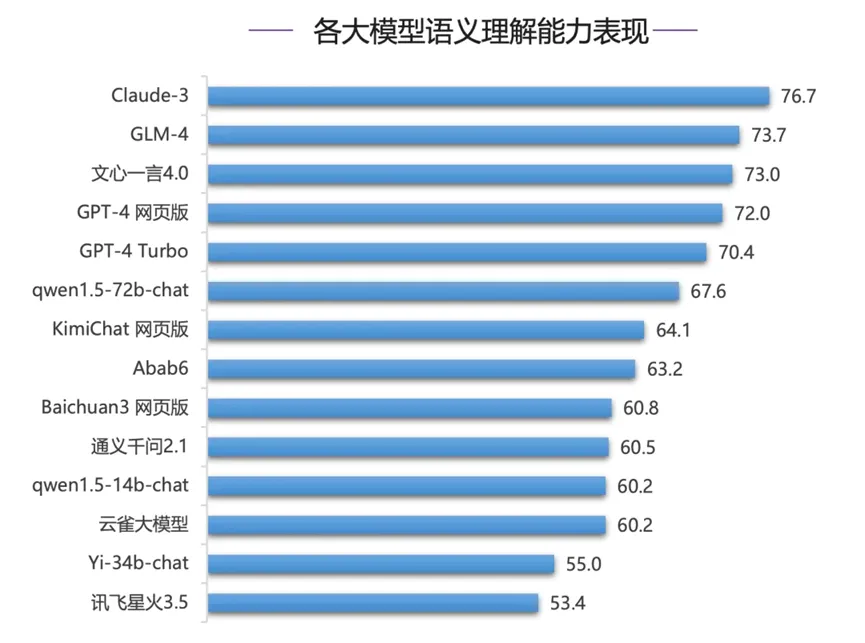
SuperBench榜單:GLM-4超過(guò)GPT-4系列模型位居第二
對(duì)于開(kāi)發(fā)者和企業(yè)來(lái)說(shuō),模型的使用成本是一個(gè)重要考量,大模型降價(jià)有利于吸引更多的開(kāi)發(fā)者和企業(yè)客戶,擴(kuò)大其生態(tài)圈。華福證券最近發(fā)布報(bào)告稱,大模型成本優(yōu)化與算力需求并不是直接的此長(zhǎng)彼消,而是互相搭臺(tái)、相互成就。定價(jià)的持續(xù)走低有望帶來(lái)更快的商業(yè)化落地,進(jìn)而會(huì)衍生出更多的微調(diào)及推理等需求,將逐步盤(pán)活國(guó)內(nèi)AI應(yīng)用及國(guó)產(chǎn)算力發(fā)展。
這次 API定價(jià)更新也體現(xiàn)出智譜AI覆蓋開(kāi)發(fā)者用戶的決心——單次調(diào)用適合對(duì)實(shí)時(shí)性要求高的中小用戶;批量調(diào)用定價(jià)更低,則是為數(shù)據(jù)量大、對(duì)成本敏感的企業(yè)及用戶量身定制。作為國(guó)內(nèi)應(yīng)用最為廣泛的開(kāi)放平臺(tái),智譜的開(kāi)放平臺(tái)上已經(jīng)聚集了超過(guò)數(shù)十萬(wàn)的企業(yè)和開(kāi)發(fā)者,并且在持續(xù)快速增長(zhǎng),過(guò)去的半年每日的token消耗增長(zhǎng)超過(guò)一百倍。比如官方開(kāi)發(fā)的三個(gè)調(diào)用工具,網(wǎng)頁(yè)檢索、函數(shù)調(diào)用以及知識(shí)庫(kù),自從1月上線以來(lái)調(diào)用次數(shù)已經(jīng)超過(guò) 3 億次。
技術(shù)的進(jìn)步也為降低開(kāi)發(fā)、運(yùn)行 LLMs 成本提供了現(xiàn)實(shí)可能。例如,從基礎(chǔ)設(shè)施來(lái)看,隨著一些老款A(yù)I芯片(比如 Nvidia A100 )降價(jià),大模型培訓(xùn)成本下降了約60%。英偉達(dá)也優(yōu)化了軟件性能,幫助開(kāi)發(fā)者更快訓(xùn)練和運(yùn)行大模型。研發(fā)人員也在模型架構(gòu)、模型壓縮以及GPU調(diào)用等方面探索到一些降本增效的辦法。
智譜曾表示,通過(guò)模型推理算子優(yōu)化、模型壓縮及硬件高效適配、高性能系統(tǒng)實(shí)現(xiàn)以及精細(xì)化集群調(diào)度等技術(shù)將 GLM-3 Turbo的推理成本壓縮到1/5。自大模型開(kāi)放平臺(tái)上線以來(lái),在模型效果和推理性能不斷提升的情況下,已累計(jì)降價(jià)超過(guò)百倍。除了降價(jià),智譜AI還宣布包括GLM-3 Turbo 以及最先進(jìn)基座大模型GLM-4在內(nèi)的GLM系列模型也將迎來(lái)更新,目前正在灰度測(cè)試中,很快將和廣大開(kāi)發(fā)者和應(yīng)用者見(jiàn)面。
















