














譯者 | 晶顏
審校 | 重樓
不同于互聯網上隨處可見的傳統問題庫,這些問題需要跳出常規思維。
大語言模型(LLM)在數據科學、生成式人工智能(GenAI)和人工智能領域越來越重要。這些復雜的算法提升了人類的技能,并在諸多行業中推動了效率和創新性的提升,成為企業保持競爭力的關鍵。
然而,盡管GenAI和LLM越來越常見,但我們依然缺少能深入理解其復雜性的詳細資源。職場新人在進行GenAI和LLM功能以及實際應用的面試時,往往會覺得自己像是陷入了未知領域。
為此,我們編寫了這份指導手冊,收錄了7個有關GenAI & LLM的技術性面試問題。這份指南配有深入的答案,旨在幫助您更好地迎接面試,以充足的信心來應對挑戰,以及更深層次地理解GenAI & LLM在塑造人工智能和數據科學未來方面的影響和潛力。
1. 如何在Python中使用嵌入式字典構建知識圖譜?
一種方法是使用哈希(Python中的字典,也稱為鍵-值表),其中鍵(key)是單詞、令牌、概念或類別,例如“數學”(mathematics)。每個鍵(key)對應一個值(value),這個值本身就是一個哈希:嵌套哈希(nested hash)。嵌套哈希中的鍵也是一個與父哈希中的父鍵相關的單詞,例如“微積分”(calculus)之類的單詞。該值是一個權重:“微積分”的值高,因為“微積分”和“數學”是相關的,并且經常出現在一起;相反地,“餐館”(restaurants)的值低,因為“餐館”和“數學”很少出現在一起。
在LLM中,嵌套哈希可能是embedding(一種將高維數據映射到低維空間的方法,通常用于將離散的、非連續的數據轉換為連續的向量表示,以便于計算機進行處理)。由于嵌套哈希沒有固定數量的元素,因此它處理離散圖譜的效果遠遠好于矢量數據庫或矩陣。它帶來了更快的算法,且只需要很少的內存。
2. 當數據包含1億個關鍵字時,如何進行分層聚類?
如果想要聚類關鍵字,那么對于每一對關鍵字{A, B},你可以計算A和B之間的相似度,獲悉這兩個詞有多相似。目標是生成相似關鍵字的集群。
Sklearn等標準Python庫提供凝聚聚類(agglomerative clustering),也稱為分層聚類(hierarchical clustering)。然而,在這個例子中,它們通常需要一個1億x 1億的距離矩陣。這顯然行不通。在實踐中,隨機單詞A和B很少同時出現,因此距離矩陣是非常離散的。解決方案包括使用適合離散圖譜的方法,例如使用問題1中討論的嵌套哈希。其中一種方法是基于檢測底層圖中的連接組件的聚類。
3. 如何抓取像Wikipedia這樣的大型存儲庫,以檢索底層結構,而不僅僅是單獨的條目?
這些存儲庫都將結構化元素嵌入到網頁中,使內容比乍一看更加結構化。有些結構元素是肉眼看不見的,比如元數據。有些是可見的,并且也出現在抓取的數據中,例如索引、相關項、面包屑或分類。您可以單獨檢索這些元素,以構建良好的知識圖譜或分類法。但是您可能需要從頭開始編寫自己的爬蟲程序,而不是依賴Beautiful Soup之類的工具。富含結構信息的LLM(如xLLM)提供了更好的結果。此外,如果您的存儲庫確實缺乏任何結構,您可以使用從外部源檢索的結構來擴展您的抓取數據。這一過程稱為“結構增強”(structure augmentation)。
4. 如何用上下文令牌增強LLM embeddings?
Embeddings由令牌組成;這些是您可以在任何文檔中找到的最小的文本元素。你不一定要有兩個令牌,比如“數據”和“科學”,你可以有四個令牌:“數據^科學”、“數據”、“科學”和“數據~科學”。最后一個表示發現了“數據科學”這個詞。第一個意思是“數據”和“科學”都被發現了,但是在一個給定段落的隨機位置,而不是在相鄰的位置。這樣的令牌稱為多令牌(multi-tokens)或上下文令牌。它們提供了一些很好的冗余,但如果不小心,您可能會得到巨大的embeddings。解決方案包括清除無用的令牌(保留最長的一個)和使用可變大小的embeddings。上下文內容可以幫助減少LLM幻覺。
5. 如何實現自校正(self-tuning)以消除與模型評估和訓練相關的許多問題?
這適用于基于可解釋人工智能的系統,而不是神經網絡黑匣子。允許應用程序的用戶選擇超參數并標記他喜歡的那些。使用該信息查找理想的超參數并將其設置為默認值。這是基于用戶輸入的自動強化學習。它還允許用戶根據期望的結果選擇他最喜歡的套裝,使您的應用程序可定制。在LLM中,允許用戶選擇特定的子LLM(例如基于搜索類型或類別),可以進一步提高性能。為輸出結果中的每個項目添加相關性評分,也有助于微調您的系統。
6. 如何將矢量搜索的速度提高幾個數量級?
在LLM中,使用可變長度(variable-length)embeddings極大地減少了embeddings的大小。因此,它可以加速搜索,以查找與前端提示符中捕獲到的相似的后端embeddings。但是,它可能需要不同類型的數據庫,例如鍵-值表(key-value tables)。減少令牌的大小和embeddings表是另一個解決方案:在一個萬億令牌系統中,95%的令牌永遠不會被提取來回答提示。它們只是噪音,因此可以擺脫它們。使用上下文令牌(參見問題4)是另一種以更緊湊的方式存儲信息的方法。最后,在壓縮embeddings上使用近似最近鄰搜索(approximate nearest neighbor,ANN)來進行搜索。概率版本(pANN)可以運行得快得多,見下圖。最后,使用緩存機制來存儲訪問最頻繁的embeddings 或查詢,以獲得更好的實時性能。
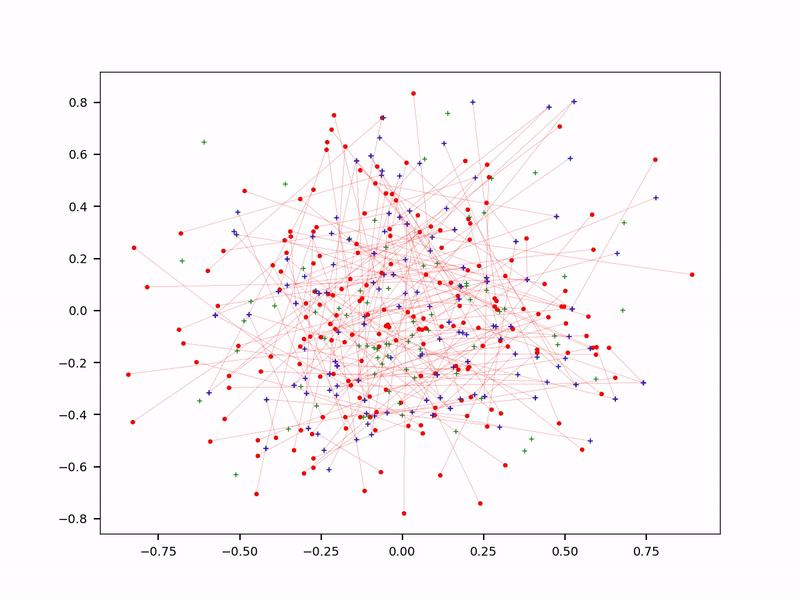
概率近似最近鄰搜索(pANN)
根據經驗來看,將訓練集的大小減少50%會得到更好的結果,過度擬合效果也會大打折扣。在LLM中,選擇幾個好的輸入源比搜索整個互聯網要好。對于每個頂級類別都有一個專門的LLM,而不是一刀切,這進一步減少了embeddings的數量:每個提示針對特定的子LLM,而非整個數據庫。
7. 從你的模型中獲得最佳結果的理想損失函數是什么?
最好的解決方案是使用模型評估指標作為損失函數。之所以很少這樣做,是因為您需要一個損失函數,它可以在神經網絡中每次神經元被激活時非常快地更新。在神經網絡環境下,另一種解決方案是在每個epoch之后計算評估指標,并保持在具有最佳評估分數的epoch生成解決方案上,而不是在具有最小損失的epoch生成解決方案上。
我目前正在研究一個系統,其中的評價指標和損失函數是相同的。不是基于神經網絡的。最初,我的評估指標是多元Kolmogorov-Smirnov距離(KS)。但如果沒有大量的計算,在大數據上對KS進行原子更新(atomic update)是極其困難的。這使得KS不適合作為損失函數,因為你需要數十億次原子更新。但是通過將累積分布函數(cumulative distribution)改變為具有數百萬個bins參數的概率密度函數(probability density function),我能夠想出一個很好的評估指標,它也可以作為損失函數。
原文標題:7 Cool Technical GenAI & LLM Job Interview Questions,作者:Vincent Granville
鏈接:https://www.datasciencecentral.com/7-cool-technical-genai-llm-job-interview-questions/。





















