一文帶你看懂并優化AI應用的架構設計
AI技術現在很火,各大公司都開始朝著這個領域發力。他們不僅創建出很多出色成果,還通過一系列技術、工具和服務,幫助普通開發者也能輕而易舉地開發出新穎的AI應用。
延伸閱讀,點擊鏈接了解 Akamai cloud-computing
本文將告訴大家如何在Akamai云計算平臺上優化一個基于Qwik和OpenAI服務的Web項目。具體來說,我們將通過本文詳細剖析項目的整體架構和優化方式,從而為廣大開發者帶來啟發。
基本架構
假設有這樣的一個Web應用:
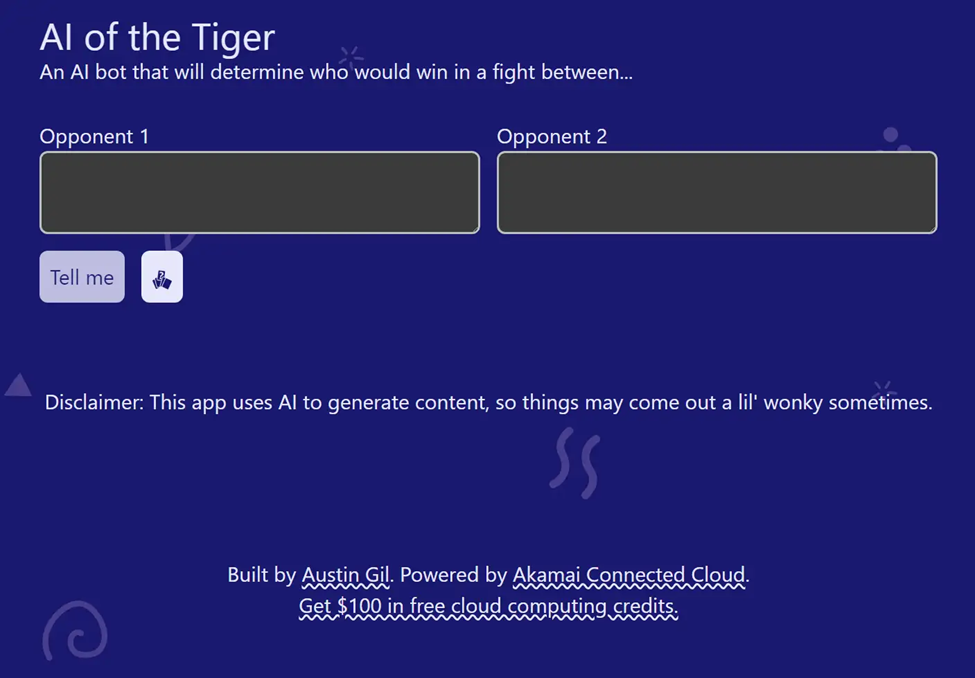
在兩個文本框中輸入兩個“對手”,隨后由AI來決定在戰斗中誰會獲勝。該應用還提供了一些解釋決策原因以及創建圖像的選項。該應用相當基礎,用戶提交兩個對手,然后應用程序即時返回一個由AI生成的響應,從中得知哪個對手會在戰斗中獲勝。
架構也很簡單:
- 客戶端向服務器發送請求。
- 服務器構造提示并將提示轉發給OpenAI。
- OpenAI向服務器返回一個流式響應。
- 服務器對流式響應進行任何必要的調整,并將其轉發給客戶端。
該應用搭建在Akamai的云計算服務(以前的Linode)上,不過下文將要介紹的內容對任何云平臺應該都適用。
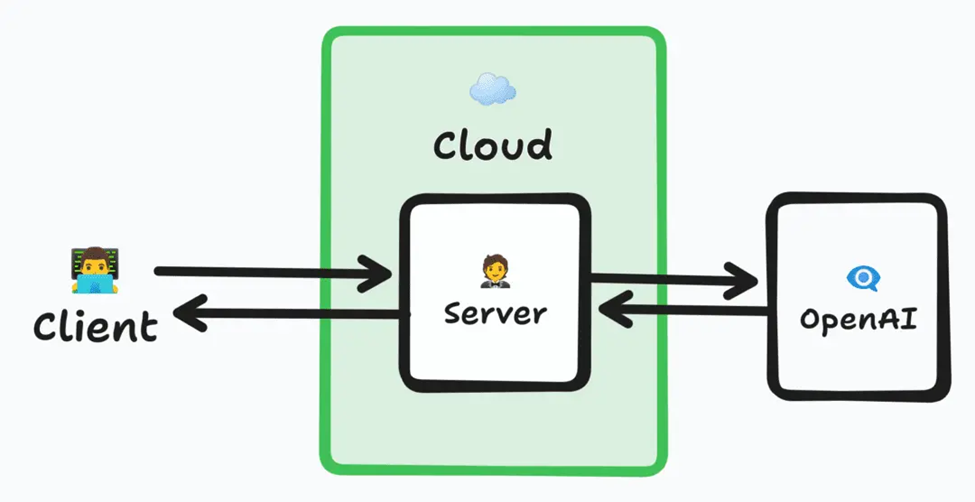
看起來像是高級餐廳里的服務員, ? ?則是“一只眼睛”,或者說是AI
從技術上講,這是完全可行的,但存在一些問題,特別是當用戶提交重復請求時。將響應存儲在我們自己的服務器上,并且只針對唯一請求訪問OpenAI,可能會讓整個過程更快速,更具成本效益。
這就需要假設我們不需要每個請求都是非確定性的(即相同的輸入產生不同的輸出)。我們可以假設相同的輸入產生相同的輸出是可接受的。畢竟,誰會贏得一場戰斗的預測結果可能并不會改變。
添加數據庫架構
如果我們想要存儲來自OpenAI的響應,一種實際的放置地點是某種類型的數據庫,這種數據庫應該能讓我們圍繞兩個對手進行快速、簡單的查找。這樣,在收到請求時,就可以首先檢查數據庫:
- 客戶端向服務器發送請求。
- 服務器檢查數據庫中是否存在與用戶輸入相匹配的條目。
- 如果存在匹配的記錄,服務器使用該數據回復并完成請求。跳過后續步驟。
- 如果不存在匹配的記錄,則服務器繼續執行上一小節中流程的第三步(聯系OpenAI)。
- 在關閉響應前,服務器將OpenAI的結果存儲在數據庫中。
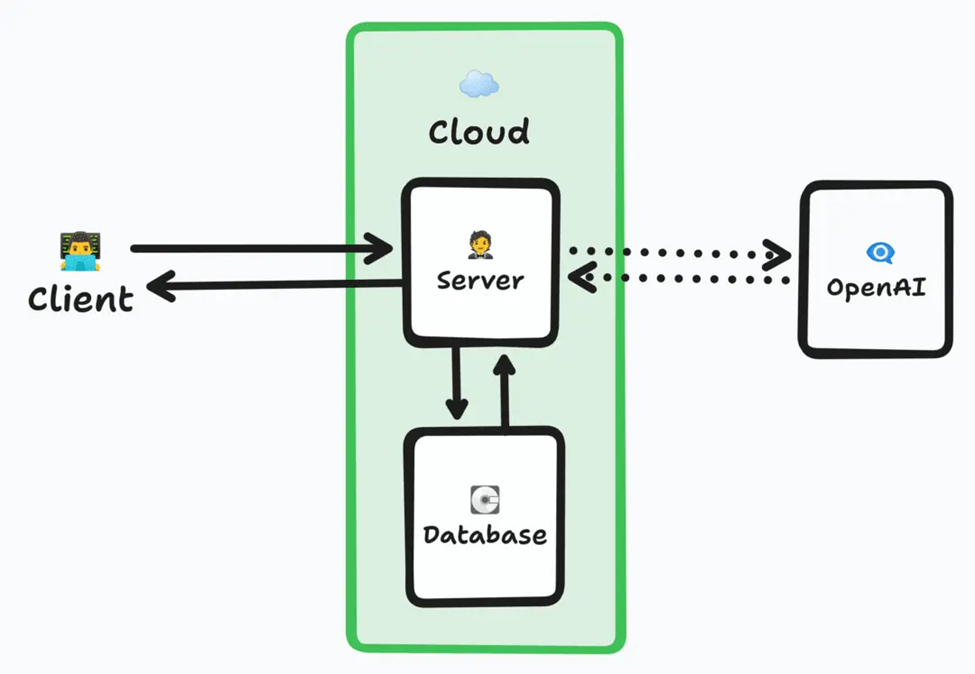
虛線代表可選請求,而 看起來像是一個硬盤
有了這樣的設置,任何重復的請求都將由數據庫直接處理。通過將一些OpenAI請求設置為可選,我們還有可能降低用戶體驗的延遲,同時通過減少API請求的數量來節省費用。
這是一個很好的開始,特別是如果服務器和數據庫位于同一個地區。這將比訪問OpenAI的服務器快得多。
然而,隨著應用程序變得更加受歡迎,我們可能會開始吸引來自世界各地的用戶。數據庫查詢的速度自然是越快越好,但往返傳輸數據造成的延遲又該如何消除?
我們可以通過將應用移動到距離用戶更近的地方來解決這個問題。
引入邊緣計算
邊緣(Edge)指一種讓內容盡可能接近用戶的方式。對一些應用場景來說,邊緣可能意味著物聯網設備或手機基站,但在Web應用之類的場景中,最典型的邊緣往往是內容分發網絡(CDN)。
CDN是一種全球分布的計算機網絡,可以從網絡中最近的節點響應用戶請求。傳統的CDN是為靜態資產設計的,但近年來,CDN開始支持邊緣計算。
有了邊緣計算,我們可以將很多后端邏輯移動到距離用戶非常近的地方,而且不僅限于計算!大多數邊緣計算提供商還在同一邊緣節點上提供某種最終一致的鍵值存儲服務。
這會對我們的應用程序產生什么影響?
- 客戶端向我們的后端發送請求。
- 邊緣計算網絡將請求路由到最近的邊緣節點。
- 邊緣節點檢查與用戶輸入匹配的鍵值存儲中是否存在現有記錄。
- 如果存在匹配的記錄,邊緣節點將使用該數據回復,完成請求。跳過后續步驟。
- 如果不存在匹配的記錄,則邊緣節點將請求轉發到源服務器,源服務器再將其傳遞給OpenAI……
- 在關閉響應前,服務器將OpenAI的結果存儲在邊緣鍵值存儲中。
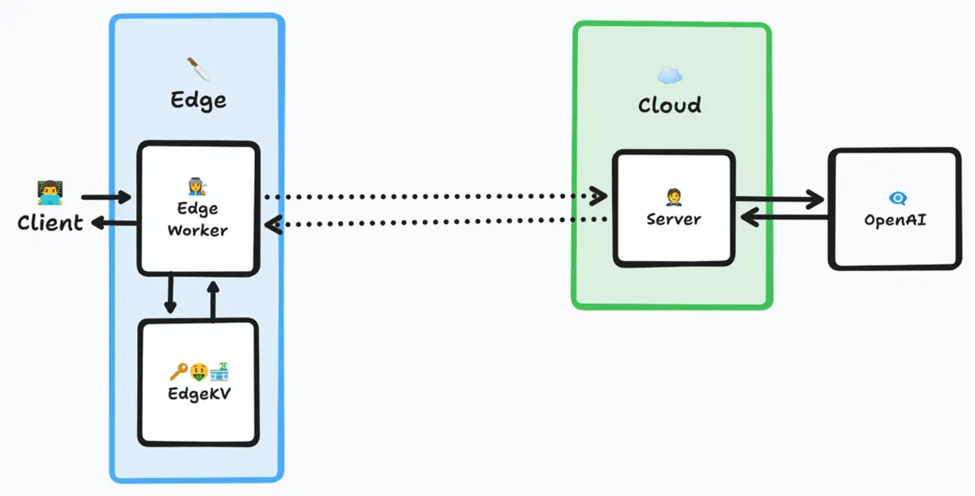
邊緣節點是藍色方框,用 表示;EdgeWorker是Akamai的邊緣計算產品,用 表示;EdgeKV是Akamai的鍵值存儲服務,用 表示。從物理距離來說,邊緣節點比云中的源服務器更接近客戶端
源服務器在這里可能并非絕對必要,但我們認為它的存在有一定必要性。基于數據、計算和邏輯流程考慮,這與先前的架構基本相同。主要區別在于先前存儲的結果現在更接近用戶,幾乎可以立即返回。
注意:盡管數據被緩存在邊緣,但響應仍然是動態構建的。如果不需要動態響應,將CDN放置在源服務器前并設置正確的HTTP頭來緩存響應,可能是一種更簡單的做法。
這樣就完成了!任何重復請求幾乎會立即得到響應,同時也節省了不必要的API請求。文本響應的架構問題順利解決,但是別忘了,還有AI圖像生成功能呢。
緩存圖片
處理圖片時,我們需要考慮內容的交付和存儲。相信OpenAI有自己的解決方案,但一些企業出于安全、合規性或可靠性等原因的考慮,可能希望與圖片交付和存儲有關的整個基礎設施都完全由自己掌控。一些情況下,企業甚至可能寧愿運行自己的圖像生成服務,而不是使用OpenAI。
在當前的工作流程中,用戶發出請求,最終請求傳遞到OpenAI。OpenAI生成圖像,但不返回圖像,而是返回一個JSON響應,其中包含圖像的URL,該URL托管在OpenAI的基礎設施上。使用此響應時,可以用URL將<img>標簽添加到頁面,從而啟動另一個請求來獲取對應的圖像。
如果要將圖像托管在自己的基礎設施上,需要一個存儲圖像的地方。我們可以將圖像寫入源服務器的磁盤,但這可能會快速使用大量磁盤空間,并且必須升級服務器,這可能會很昂貴。對象存儲是一種更便宜的解決方案,我們可以將圖像上傳到自己的對象存儲實例,并使用該實例對應的URL。
這解決了存儲問題,但對象存儲桶通常都部署在單個區域,這與我們在數據庫中存儲文本時遇到的問題類似。單個區域可能距離用戶很遠,這可能會導致很高的延遲。
又到了邊緣的用武之地了。為純靜態資產添加CDN功能其實非常簡單。一旦配置完成,CDN將在初始請求時從對象存儲中拉取圖像,并將其緩存以供來自同一區域的后續訪問者直接交付。
我們的圖片處理流程如下:
- 客戶端發送請求,根據對手生成圖像。
- 邊緣計算檢查該請求的圖像數據是否已存在。如果存在,則直接返回URL。
- 圖像與URL一起添加到頁面,并由瀏覽器請求圖像。
- 如果圖像已經緩存在CDN中,則瀏覽器幾乎能立即加載。流程結束。
- 如果圖像尚未被緩存,CDN將從對象存儲位置拉取圖像,緩存一份副本供未來的請求使用,并將圖像返回給客戶端。這是流程的另一個結尾。
- 如果圖像數據不在邊緣鍵值存儲中,生成圖像的請求將發送到服務器,然后傳遞到OpenAI,后者生成圖像并返回URL信息。服務器啟動任務將圖像保存在對象存儲桶中,將圖像數據存儲在邊緣鍵值存儲中,并將圖像數據返回給邊緣計算節點。
- 使用新的圖像數據,客戶端創建圖像,生成新請求,并從步驟五繼續。
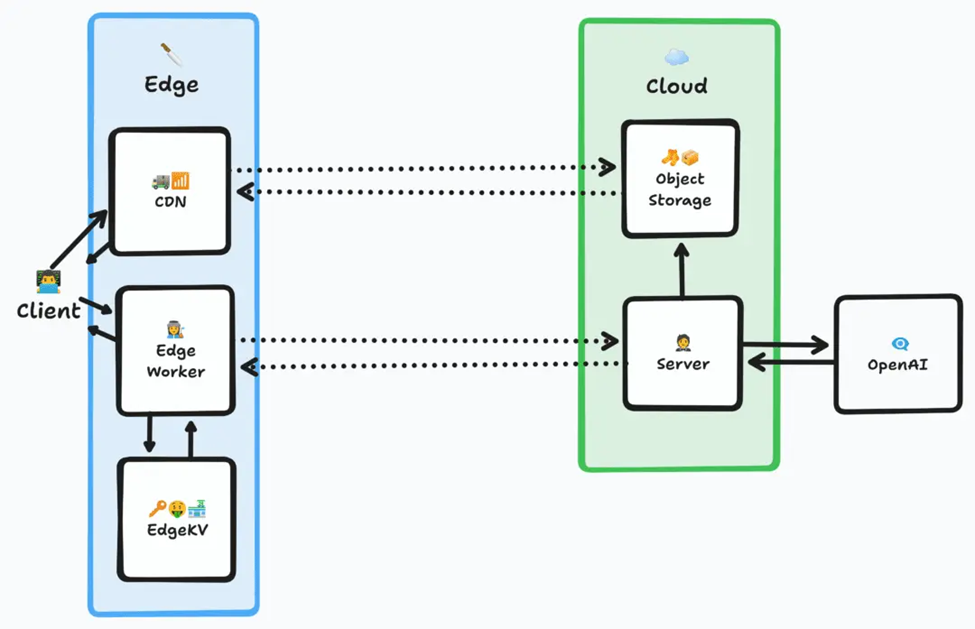
內容交付網絡以交付卡車( )和網絡信號( )表示,對象存儲以盒子里的襪子( )或存儲中的對象表示
誠然,最后這種架構稍微復雜了一些,但如果應用程序要處理大量流量,這種架構也是很有必要的。
大功告成
通過所有這些改變,我們已經為唯一請求創建了AI生成的文本和圖像,并為重復請求提供了來自邊緣的緩存內容。結果是更快的響應時間和更好的用戶體驗(當然,API調用也更少)。
上述內容完全以Akamai云計算平臺為例,但其實所涉及的各種數據庫、邊緣計算、對象存儲和CDN也適用于其他平臺。這是一個有著廣泛適用性的思路。只不過通過與Akamai的云計算和邊緣計算服務整合不僅僅能改善性能,還可以獲得很多非常酷的安全功能。
例如,在Akamai的網絡上,我們可以使用諸如Web應用程序防火墻(WAF)、分布式拒絕服務(DDoS)防護、智能爬蟲檢測等功能,從而更好地保障應用程序、數據、客戶信息的安全性。
這些額外的服務還能提供哪些好處?歡迎關注Akamai,我們回頭再細細道來。
如您所在的企業也在考慮采購云服務或進行云遷移,
點擊鏈接了解Akamai Linode的解決方案