出品 | 51CTO技術棧(微信號:blog51cto)
Mistral 發布了首個代碼模型 Codestral-22B!
該模型的瘋狂之處不僅在于訓練了80多種編程語言,包括許多代碼模型忽略的Swift等。
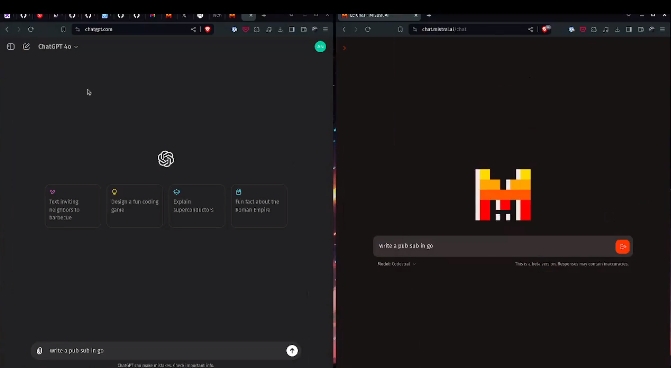
還在于他非同一般的速度。要求用Go語言編寫一個“發布/訂閱”系統。這邊的GPT-4o還在輸出,Codestral已經用快到看不清的速度交卷了!
由于該模型剛剛推出,尚未公開測試。但根據Mistral的負責人說法, Codestral是目前表現最佳的開源代碼模型。
 圖片
圖片
感興趣的朋友可以移步:
-抱抱臉 :https://huggingface.co/mistralai/Codestral-22B-v0.1
-博客:https://mistral.ai/news/codestral/
從博客來看,Codestral在長文本以及多種編程語言的性能測試中都超過了對手,包括70B的CodeLlama、33B的Deepseek Coder和70B的Llama 3 70B。
 圖片
圖片
下面來一起細致地看看代碼模型的“王”,Codestral強在何處。
1.Codestral要為代碼模型立標準
作為 22B 機型,Codestral 為代碼生成的性能/延遲空間設定了一個新標準。在核心上,Codestral 22B具有32K的上下文長度,為開發人員提供了在各種編程環境和項目中編寫和與代碼交互的能力。
 圖片
圖片
上圖:Codestral 擁有 32k 的較大上下文窗口(不同于競爭對手的 4k、8k 或 16k),在代碼生成的遠程評估 RepoBench 中優于所有其他模型。
Codestral近乎瘋狂地在超過80種編程語言的數據集上進行了訓練,這使其適合于各種編程任務,包括從頭開始生成代碼、完成編碼功能、編寫測試和使用中間填充機制完成任何部分代碼。
它涵蓋的編程語言包括流行的SQL、Python、Java、C和C++,以及更特定的Swift和Fortran等,成為編程界的多面手。
Mistral表示,Codestral可以幫助開發人員提升他們的編碼水平,加速工作流程,并在構建應用程序時節省大量的時間和努力。更不用說,它還可以幫助減少錯誤和漏洞的風險。
 上圖:Codestral性能在不同編程語言上的HumanEval評估
上圖:Codestral性能在不同編程語言上的HumanEval評估
在HumanEval上評估Python代碼生成和CruxEval測試Python輸出預測時,該模型分別以81.1%和51.3%的分數超越了競爭對手。它甚至在Bash、Java和PHP的HumanEval上也都取得了第一名。
值得注意的是,該模型在C++、C和Typescript的HumanEval上的表現并不是最好的,但所有測試的平均分數最高,為61.5%,略高于Llama 3 70B的61.2%。在評估SQL性能的Spider評估中,它以63.5%的分數排名第二。
一些流行的開發人員生產力和人工智能應用開發工具已經開始測試Codestral。這包括LlamaIndex、LangChain、Continue.dev、Tabnine和JetBrains等大名鼎鼎的名字。
“從我們的初步測試來看,它是一個生成代碼工作流的好選擇,因為它快速,有有利的上下文窗口,并且指導版本支持工具使用。我們使用LangGraph進行了自我糾正代碼生成的測試,使用指導Codestral工具使用進行輸出,并且它開箱即用效果非常好,”LangChain的首席執行官兼聯合創始人Harrison Chase說。
另外,Codestral已經與JetBrains、SourceGraph和LlamaIndex在內的幾家行業伙伴展開合作。LlamaIndex的CEO Jerry Liu提到他對Codestral的測試說,“到目前為止,它始終能生成高度準確和實用的代碼,即使是復雜的任務也不例外。例如,當我要求它完成一個創建新的 LlamaIndex 查詢引擎的非繁瑣函數時,它生成的代碼盡管基于較舊的代碼庫,卻能無縫運行。”
2.如何開始使用Codestral?
Mistral在Hugging Face上提供Codestral 22B,在其自己的非商業許可下,允許開發人員將該技術用于非商業目的、測試和支持研究工作。
該公司還通過兩個API端點提供該模型:codestral.mistral.ai和api.mistral.ai。
前者旨在為希望在IDE內部使用Codestral的指導或中間填充路線的用戶設計。它配有個人級別的API密鑰,沒有通常的組織速率限制,在八周的測試期間免費使用。而api.mistral.ai是更廣泛的研究、批量查詢或第三方應用開發的常規端點,將每個Token的查詢計費。
比較有趣的是,Mistral在 Le Chat 上公開了 Codestral 的指導版本,允許通過他們免費的對話界面 Le Chat 訪問Codestral。開發人員可以自然、直觀地與 Codestral 互動,充分利用該模型的功能。
3.寫在最后
國產大模型中同樣有表現驚艷的代碼模型,例如阿里不久前開源的70億參數大模型CodeQwen1.5-7B。
在HumanEval測試中,CodeQwen1.5-7B-Chat版本的得分甚至超過了GPT-4早期版本,比GPT-4-Turbo(2023年11月版本)略低。
 圖片
圖片
CodeQwen的開發者Binyuan Hui在祝賀時不忘提醒Mistral的聯創Guillaume Lample,帶上通義一起測評下!
 圖片
圖片
估計我們很快就能看到CodeQwen1.5-7B與Codestral在競技場上一決高下了。