港科大最新!Vista:一種具有高保真度和多功能可控的世界模型
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
原標題:Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
論文鏈接:https://arxiv.org/pdf/2405.17398
代碼鏈接:github.com/OpenDriveLab/Vista
作者單位:香港科技大學 上海人工智能實驗室OpenDriveLab University of Tübingen Tübingen AI Center 香港大學

論文思路:
世界模型可以預見不同動作的結果,這對于自動駕駛至關重要。然而,現有的駕駛世界模型在泛化到未見環境、關鍵細節的預測保真度以及靈活應用的動作可控性方面仍存在局限性。本文提出了Vista,這是一種具有高保真度和多功能可控性的通用駕駛世界模型。基于對現有方法的系統診斷,本文引入了幾個關鍵成分來解決這些局限性。為了在高分辨率下準確預測現實世界的動態,本文提出了兩種新的損失函數,以促進對移動實例和結構信息的學習。本文還設計了一種有效的潛在替換(latent replacement)方法,將歷史幀作為先驗注入,以實現連貫的長時間滾動預測(rollouts)。對于動作可控性(action controllability),本文通過一種高效的學習策略,結合了從高層意圖(命令、目標點)到低層操作(軌跡、角度和速度)的一套多功能控制。在大規模訓練之后,Vista的能力可以無縫地泛化到不同的場景。對多個數據集的廣泛實驗表明,Vista在超過70%的比較中優于最先進的通用視頻生成器,并在FID上超過表現最佳的駕駛世界模型55%,在FVD上超過27%。此外,本文首次利用Vista自身的能力,在不訪問真實動作(ground truth actions)的情況下,建立了一個通用的獎勵機制,用于真實世界動作評估。
主要貢獻:
(1) 本文提出了Vista,這是一種通用的駕駛世界模型,能夠在高時空分辨率下預測逼真的未來。通過捕捉動態(capture dynamics)和保持結構(preserve structures)的兩種新損失函數,以及詳盡的動態先驗以維持長時間滾動預測(long-horizon rollouts)的一致性,其預測保真度得到了極大提升。
(2) 在高效學習策略的推動下,本文通過統一的條件接口將多功能動作可控性集成到Vista中。Vista的動作可控性還可以在零樣本的情況下泛化到不同領域。
(3) 本文在多個數據集上進行了全面的實驗,以驗證Vista的有效性。它優于最具競爭力的通用視頻生成器,并在nuScenes數據集上設立了新的最先進水平。本文的實驗證據表明,Vista可以用作評估動作的獎勵函數(reward function)。
網絡設計:
在可擴展學習技術的驅動下,自動駕駛在過去幾年中取得了令人鼓舞的進展 [17, 54, 129]。然而,對于當前最先進的技術而言,復雜和分布外的情況仍然難以處理 [77]。一種有前景的解決方案是世界模型 [53, 70],它們從歷史觀察和替代動作中推斷出世界的可能未來狀態,從而評估這些動作的可行性。世界模型有潛力在不確定性中進行推理并避免災難性錯誤 [50, 70, 120],從而促進自動駕駛中的泛化和安全性。
盡管世界模型的主要前景是賦予其在新環境中的泛化能力,但現有的駕駛世界模型仍受限于數據規模 [84, 118, 120, 137, 140] 和地理覆蓋范圍 [50, 57]。如表1和圖1所總結的那樣,它們通常還局限于低幀率和低分辨率,導致關鍵細節的丟失。此外,大多數模型僅支持單一的控制模式,例如轉向角和速度。這不足以表達從高層意圖到低層操作的各種動作形式,并且與流行的規劃算法的輸出不兼容 [12, 14, 19, 52, 54, 60]。此外,動作可控性在未見數據集上的泛化能力研究不足。這些局限性阻礙了現有工作的適用性,因此開發一種能夠克服這些局限性的世界模型勢在必行。
為此,本文引入了Vista,這是一種在跨領域泛化、高保真預測和多模態動作可控性方面表現出色的駕駛世界模型。具體來說,本文在全球駕駛視頻的大型語料庫 [130] 上開發了預測模型,以培養其泛化能力。為了實現連貫的未來推斷,本文將Vista基于三種基本的動態先驗條件(見第3.1節)。不僅依賴于標準的擴散損失 [5],本文還引入了兩種顯式損失函數,以增強動態并保持結構細節(見第3.1節),從而提升Vista在高分辨率下模擬逼真未來的能力。為了實現靈活的可控性,本文結合了一套多功能動作格式,包括高層意圖(如命令和目標點)以及低層操作(如軌跡、轉向角和速度)。這些動作條件通過一個統一接口注入,并通過高效的訓練策略進行學習(見第3.2節)。因此,如圖2所示,Vista獲得了以10 Hz和576×1024像素預測逼真未來的能力,并在各種粒度水平上實現了多功能動作可控性。本文還展示了Vista作為通用獎勵函數評估不同動作可靠性的潛力。
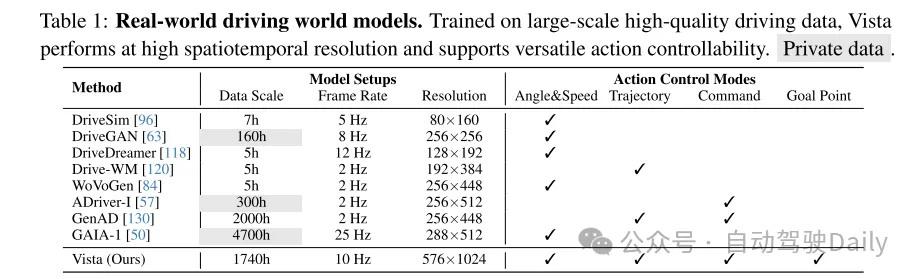
表1:真實世界的駕駛世界模型。Vista在大規模高質量駕駛數據上訓練,能夠在高時空分辨率下運行,并支持多功能動作可控性。

圖1:分辨率比較。Vista的預測分辨率高于以往文獻中的模型。

圖2:Vista的能力。Vista可以從任意環境出發,在高時空分辨率下預測逼真且連續的未來(A-B)。它可以通過多模態動作進行控制(C),并作為通用獎勵函數評估真實世界的駕駛動作(D)。

圖3:[左]:Vista流程。除了初始幀,Vista還可以通過潛在替換吸收更多關于未來動態的先驗知識。其預測可以通過不同的動作進行控制,并通過自回歸展開擴展到長時間范圍。[右]:訓練過程。Vista分為兩個訓練階段,在第二階段中凍結預訓練權重以學習動作控制。

圖4:損失設計示意圖。與標準擴散損失(b)均勻分布不同,本文的動態增強損失(d)能夠自適應地集中在關鍵區域(c)(例如移動的車輛和道路邊緣)進行動態建模。此外,通過顯式監督高頻特征(e),可以增強結構細節(例如邊緣和車道)的學習。
實驗結果:
圖5:在相同條件幀下由不同模型預測的駕駛未來。本文將Vista與公開可用的視頻生成模型在其默認配置下進行對比。盡管之前的模型會產生不對齊和損壞的結果,Vista則不會出現這些問題。
圖6:[頂部]:長時間預測。Vista可以在沒有太多退化的情況下預測15秒高分辨率的未來,涵蓋長距離駕駛。藍線的長度表示之前工作中展示的最長預測時間。[底部]:SVD的長期擴展結果。SVD未能像Vista那樣自回歸地生成一致的高保真視頻。
圖7:人工評估結果。數值表示一個模型優于另一個模型的百分比。Vista在兩個指標上都優于現有的工作。
圖8:動作控制的效果。應用動作控制將生成與真實數據更為相似的預測。
圖9:多功能動作可控性。Vista能夠在多種情景下響應多模態動作條件,預測相應的結果。更多結果請參見附錄E。
圖10:[左]:在Waymo上的不同L2誤差的平均獎勵。[右]:案例研究。本文的獎勵的相對對比可以正確評估L2誤差無法判斷的動作。
圖11:動態先驗的效果。注入更多的動態先驗可以產生與真實值更一致的未來運動,例如左側白色車輛和廣告牌的運動。
圖12:[左]:動態增強損失的效果。通過動態增強損失監督的模型生成更逼真的動態。在第一個例子中,前車沒有保持靜止,而是正常前進。在第二個例子中,當自車向右轉向時,樹木自然地向左移動,遵循現實世界的幾何規則。[右]:結構保持損失的效果。所提出的損失使物體在移動時輪廓更加清晰。
總結:
本文提出了Vista,這是一種具有增強保真度和可控性的可泛化駕駛世界模型。通過系統性的研究,Vista能夠以高時空分辨率預測真實且連續的未來。它還具備多功能動作可控性,能夠泛化到未見過的場景。此外,Vista可以被構建為一個獎勵函數來評估動作。本文希望Vista能夠引發更廣泛的興趣,推動可泛化自主系統的發展。