RAGFlow開源Star量破萬,是時(shí)候思考下RAG的未來是什么了
本文作者為張穎峰,英飛流 InfiniFlow 創(chuàng)始人 CEO,連續(xù)創(chuàng)業(yè)者,先后負(fù)責(zé) 7 年搜索引擎研發(fā),5 年數(shù)據(jù)庫(kù)內(nèi)核研發(fā),10 年云計(jì)算基礎(chǔ)架構(gòu)和大數(shù)據(jù)架構(gòu)研發(fā),10 年人工智能核心算法研發(fā),包括廣告推薦引擎,計(jì)算機(jī)視覺和自然語(yǔ)言處理。先后主導(dǎo)并參與三家大型企業(yè)數(shù)字化轉(zhuǎn)型,支撐過日活千萬,日均兩億動(dòng)態(tài)搜索請(qǐng)求的互聯(lián)網(wǎng)電商業(yè)務(wù)。
搜索技術(shù)是計(jì)算機(jī)科學(xué)中最難的技術(shù)挑戰(zhàn)之一,迄今只有很少一部分商業(yè)化產(chǎn)品可以把這個(gè)問題解決得很好。大多數(shù)商品并不需要很強(qiáng)的搜索,因?yàn)檫@和用戶體驗(yàn)并沒有直接關(guān)系。然而,隨著 LLM 的爆炸性增長(zhǎng),每家使用 LLM 的公司都需要內(nèi)置一個(gè)強(qiáng)大的檢索系統(tǒng),才能使得 LLM 可以真正為企業(yè)用起來,這就是 RAG (基于檢索增強(qiáng)的內(nèi)容生成)—— 通過搜索內(nèi)部信息給 LLM 提供與用戶提問最相關(guān)的內(nèi)容,來幫助 LLM 做最終的答案生成。
想象一下,LLM 正在針對(duì)用戶提問回答,如果沒有 RAG,那么 LLM 不得不根據(jù)自己在訓(xùn)練過程中學(xué)到的知識(shí)來回憶內(nèi)容,而有了 RAG 之后,這種問題回答就如同開卷考試,到教科書中去尋找包含答案的段落,因此回答問題變得容易很多。隨著 LLM 的演進(jìn),新的 LLM 具有更長(zhǎng)的上下文窗口,可以處理更大的用戶輸入,如果可以直接在上下文窗口中載入整個(gè)教科書,為什么還需要去教科書中翻答案呢?實(shí)際上,對(duì)于大多數(shù)應(yīng)用而言,即使 LLM 可以包含上百萬乃至上千萬 Token 的上下文窗口,搜索依然必不可少:
- 企業(yè)通常包含多個(gè)版本的類似文檔,將它們?nèi)總鹘o LLM 會(huì)導(dǎo)致相互沖突的信息。
- 大多數(shù)企業(yè)內(nèi)部場(chǎng)景都需要對(duì)傳給上下文窗口的內(nèi)容做訪問權(quán)限控制。
- LLM 更容易受到跟問題語(yǔ)義相關(guān)但卻跟答案無關(guān)內(nèi)容的干擾,從而分心。
- 即使 LLM 能力很強(qiáng)大,也沒有必要浪費(fèi)多很多的成本和延遲來處理跟用戶提問不相關(guān)的數(shù)百萬個(gè) Token 。
RAG 從出現(xiàn)到流行只花了很短的時(shí)間,這得益于各種 LLMOps 工具迅速將如下的組件串接起來使得整個(gè)系統(tǒng)得以運(yùn)轉(zhuǎn)。
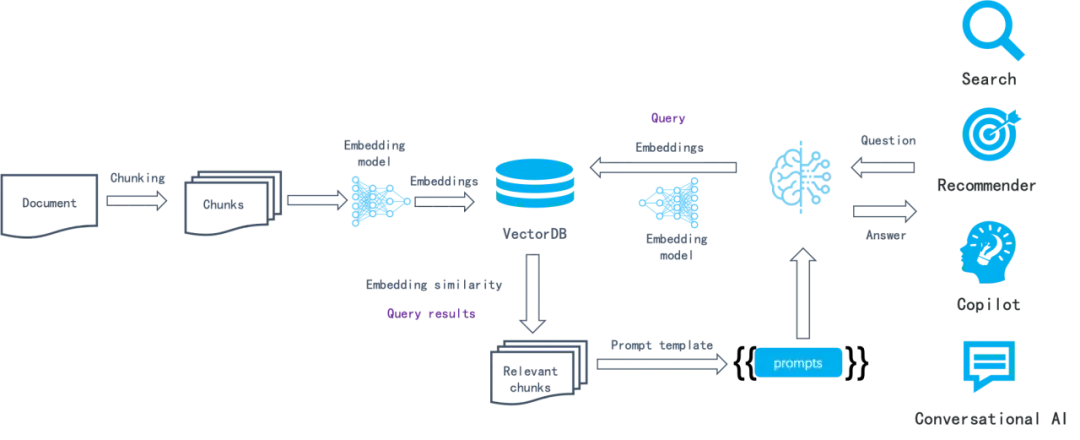
以上這種基于語(yǔ)義相似度的方法已經(jīng)工作了很多年:首先,將數(shù)據(jù)分塊(例如根據(jù)段落),然后通過 Embedding 模型把每個(gè)塊轉(zhuǎn)成向量保存到向量數(shù)據(jù)庫(kù)。在檢索過程中,把提問也轉(zhuǎn)成向量,接著通過向量數(shù)據(jù)庫(kù)檢索到最接近該向量的數(shù)據(jù)塊,這些數(shù)據(jù)塊理論上包含跟查詢語(yǔ)義最相似的數(shù)據(jù)。
在整個(gè)鏈路中,LLMOps 工具可以操作的事情有:
- 解析和切分文檔。通常采用固定大小來把解析好的文本切成數(shù)據(jù)塊。
- 編排任務(wù),包括數(shù)據(jù)寫入和查詢時(shí),負(fù)責(zé)把數(shù)據(jù)塊發(fā)到 Embedding 模型(既包含私有化也包含 SaaS API);返回的向量連同數(shù)據(jù)塊共同發(fā)給向量數(shù)據(jù)庫(kù);根據(jù)提示詞模板拼接向量數(shù)據(jù)庫(kù)返回的內(nèi)容。
- 業(yè)務(wù)邏輯組裝。例如用戶對(duì)話內(nèi)容的生成和返回,對(duì)話跟業(yè)務(wù)系統(tǒng)(如客服系統(tǒng))的連接,等等。
這個(gè)流程的建立很簡(jiǎn)單,但搜索效果卻很一般,因?yàn)檫@套樸素的基于語(yǔ)義相似度的搜索系統(tǒng)包含若干局限:
- Embedding 是針對(duì)整塊文本的處理,對(duì)于一個(gè)特定的問題,它無法區(qū)分文字中特定的實(shí)體 / 關(guān)系 / 事件等權(quán)重明顯需要提高的 Token,這樣導(dǎo)致 Embedding 的有效信息密度有限,整體召回精度不高。
- Embedding 無法實(shí)現(xiàn)精確檢索。例如如果用戶詢問 “2024 年 3 月我們公司財(cái)務(wù)計(jì)劃包含哪些組合”,那么很可能得到的結(jié)果是其他時(shí)間段的數(shù)據(jù),或者得到運(yùn)營(yíng)計(jì)劃,營(yíng)銷管理等其他類型的數(shù)據(jù)。
- 對(duì) Embedding 模型很敏感,針對(duì)通用領(lǐng)域訓(xùn)練的 Embedding 模型在垂直場(chǎng)景可能表現(xiàn)不佳。
- 對(duì)如何數(shù)據(jù)分塊很敏感,輸入數(shù)據(jù)的解析、分塊和轉(zhuǎn)換方式不同,導(dǎo)致的搜索返回結(jié)果也會(huì)大不同。而依托于 LLMOps 工具的體系,對(duì)于數(shù)據(jù)分塊的邏輯往往簡(jiǎn)單粗暴,忽視了數(shù)據(jù)本身的語(yǔ)義和組織。
- 缺乏用戶意圖識(shí)別。用戶的提問可能并沒有明確的意圖,因此即便解決了前述的召回精度問題,在意圖不明的情況下,也沒有辦法用相似度來找到答案。
- 無法針對(duì)復(fù)雜提問進(jìn)行回答,例如多跳問答(就是需要從多個(gè)來源收集信息并進(jìn)行多步推理才能得出綜合答案的問題。
因此可以把這類以 LLMOps 為核心的 RAG 看作 1.0 版本,它的主要特點(diǎn)在于重編排而輕效果,重生態(tài)而輕內(nèi)核。因此,從面世一開始就迅速普及,普通開發(fā)者可以借助于這些工具快速搭建起原型系統(tǒng),但在深入企業(yè)級(jí)場(chǎng)景時(shí),卻很難滿足要求,并且經(jīng)常處于無計(jì)可施的狀態(tài)。隨著 LLM 快速向更多場(chǎng)景滲透,RAG 也需要快速進(jìn)化,畢竟搜索系統(tǒng)的核心是找到答案,而不是找到最相似的結(jié)果。基于這些,我們認(rèn)為未來的 RAG 2.0 可能是這樣工作的:

其主要特點(diǎn)為:
1.RAG 2.0 是以搜索為中心的端到端系統(tǒng),它將整個(gè) RAG 按照搜索的典型流程劃分為若干階段:包含數(shù)據(jù)的信息抽取、文檔預(yù)處理、構(gòu)建索引以及檢索。RAG 2.0 是典型的 AI Infra,區(qū)別于以現(xiàn)代數(shù)據(jù)棧為代表的 Data Infra,它無法用類似的 LLMOps 工具來編排。因?yàn)橐陨檄h(huán)節(jié)之間相互耦合,接口遠(yuǎn)沒有到統(tǒng)一 API 和數(shù)據(jù)格式的地步,并且環(huán)節(jié)之間還存在循環(huán)依賴。例如對(duì)問題進(jìn)行查詢重寫,是解決多跳問答、引入用戶意圖識(shí)別必不可少的環(huán)節(jié)。查詢重寫和獲得答案,是一個(gè)反復(fù)檢索和重寫的過程,編排在這里不僅不重要,甚至?xí)蓴_搜索和排序的調(diào)優(yōu)。近期知名的 AI 編排框架 LangChain 遭到吐槽,就是同樣的道理。
2. 需要一個(gè)更全面和強(qiáng)大的數(shù)據(jù)庫(kù),來提供更多的召回手段,這是由于為解決 RAG 1.0 中召回精度不高的痛點(diǎn),需要采用多種方法混合搜索。除了向量搜索之外,還應(yīng)該包含關(guān)鍵詞全文搜索、稀疏向量搜索,乃至支持類似 ColBERT 這樣 Late Interaction 機(jī)制的張量搜索。
a. 關(guān)鍵詞全文搜索是實(shí)現(xiàn)精確查詢必不可少的手段,當(dāng)用戶檢索意圖明確時(shí),期望的文檔卻沒有返回,這會(huì)使他感到沮喪。其次,通過關(guān)鍵詞全文搜索,可以查看跟查詢匹配的關(guān)鍵詞,從而更直觀地了解檢索到該文檔的原因,這對(duì)于排序的可解釋性也非常重要。所以在絕大多數(shù)情況下,都不應(yīng)該把關(guān)鍵詞全文搜索排除在 RAG 之外。全文搜索是個(gè)很成熟的功能,但并不等于實(shí)現(xiàn)它很容易。除了需要能夠處理海量數(shù)據(jù)之外,為符合 RAG 召回的需要,還必須提供默認(rèn)基于 Top K Union 語(yǔ)義的搜索機(jī)制,這是由于 RAG 的查詢輸入通常不是幾個(gè)關(guān)鍵詞,而是整句話。目前市面上大多數(shù)聲稱提供 BM25 和全文搜索能力的數(shù)據(jù)庫(kù),實(shí)現(xiàn)的都是閹割版本,既無法高性能搜索海量數(shù)據(jù),也無法提供有效召回,不具備企業(yè)級(jí)服務(wù)能力。
b.IBM 研究院最新的研究成果顯示,在若干問答數(shù)據(jù)集的評(píng)測(cè)中,聯(lián)合關(guān)鍵詞全文搜索、稀疏向量、以及向量搜索 3 種召回方式,取得了 SOTA 的結(jié)果。因此,有理由在數(shù)據(jù)庫(kù)中原生支持這種 3 路混合搜索能力。
c. 張量搜索是一種很新的檢索方式。它來自于以 ColBERT 為代表的 Late Interaction 機(jī)制。簡(jiǎn)單地總結(jié),就是 Cross Encoder 為代表的 Reranker 模型,它能夠捕捉查詢和文檔之間的復(fù)雜交互關(guān)系,因此相比向量搜索能夠提供更精準(zhǔn)的搜索排序結(jié)果。但是它的缺點(diǎn)在于,由于需要在查詢時(shí)對(duì)每個(gè)文檔和查詢共同經(jīng)過 Embedding 模型來編碼,這使得排序的速度非常慢,因此 Cross-Encoder 只能用于最終結(jié)果的重排序。而類似 ColBERT 這樣的模型,它仍然把文檔在索引階段就編碼好,這一點(diǎn)類似于向量搜索,但不同之處在于,它把文檔的每個(gè) Token 都用單獨(dú)的向量表示,因此是用許多向量或者一個(gè)張量來表示一個(gè)文檔,在排序計(jì)算時(shí),所有 Token 之間的向量都需要做交叉計(jì)算,這一點(diǎn)跟 Cross Encoder 的機(jī)制類似,因此比向量搜索損失的信息更少,召回精度更高。而相比 Cross Encoder,它的性能要好得多,因?yàn)樵诓樵兤陂g無需對(duì)每個(gè)文檔進(jìn)行編碼, 所以可以理解為既擁有接近 Cross Encoder 的召回精度,也擁有接近向量搜索的性能,這樣可以在召回階段就引入更好的模型,具有非常強(qiáng)的實(shí)際操作價(jià)值。結(jié)合張量搜索和關(guān)鍵詞全文搜索,不失為一種非常值得采用的混合搜索能力。作為數(shù)據(jù)庫(kù)來說,同樣需要為這樣的能力提供選擇。
近期 OpenAI 收購(gòu)了數(shù)據(jù)倉(cāng)庫(kù)公司 Rockset,這背后的邏輯,其實(shí)并不在于數(shù)據(jù)倉(cāng)庫(kù)本身對(duì)于 RAG 有多么大的價(jià)值,而是相比其他數(shù)據(jù)倉(cāng)庫(kù),Rockset 更是一個(gè)索引數(shù)據(jù)庫(kù),它對(duì)表的每列數(shù)據(jù)都建立了倒排索引,因此可以提供類比于 Elasticsearch 的關(guān)鍵詞全文搜索能力,再配套以向量搜索,原生具備這 2 類混合搜索能力的數(shù)據(jù)庫(kù),在當(dāng)前階段,就已經(jīng)沒有多少選擇了,再加上 Rockset 還采用了云原生架構(gòu),2 點(diǎn)結(jié)合,是 OpenAI 做出選擇的主要原因。這些考慮,也是我們?cè)诹硗忾_發(fā) AI 原生數(shù)據(jù)庫(kù) Infinity 的主要原因,我們期望它能原生地包含前述的所有能力,從而可以更好地支撐 RAG 2.0。
3. 數(shù)據(jù)庫(kù)只能涵蓋 RAG 2.0 中的數(shù)據(jù)檢索和召回環(huán)節(jié),還需要站在整個(gè) RAG 的鏈路上,針對(duì)各環(huán)節(jié)進(jìn)行優(yōu)化,這包括:
a. 需要有單獨(dú)的數(shù)據(jù)抽取和清洗模塊,來針對(duì)用戶的數(shù)據(jù),進(jìn)行切分。切分的粒度,需要跟最終搜索系統(tǒng)返回的結(jié)果進(jìn)行迭代。數(shù)據(jù)抽取模塊,需要考慮到用戶的各種不同格式,包含復(fù)雜文檔例如表格處理和圖文等,因此它必須依托于若干模型才能完成任務(wù)。高質(zhì)量的數(shù)據(jù)抽取模塊,是保證高質(zhì)量搜索的前置條件。這部分可以類比為現(xiàn)代數(shù)據(jù)棧的 ETL,但卻比 ETL 更加復(fù)雜,后者是以 SQL 為核心的的確定性規(guī)則系統(tǒng),而前者則是以各種文檔結(jié)構(gòu)識(shí)別模型為核心的非標(biāo)準(zhǔn)化體系。
b. 抽取出的數(shù)據(jù),在送到數(shù)據(jù)庫(kù)索引之前,還可能需要若干預(yù)處理步驟,包括知識(shí)圖譜構(gòu)建,文檔聚類,以及針對(duì)垂直領(lǐng)域的 Embedding 模型微調(diào)等。這些工作,本質(zhì)上是為了輔助在檢索階段提供更多的依據(jù),從而讓檢索更加精準(zhǔn)。這個(gè)步驟不可或缺,它是針對(duì)用戶的復(fù)雜提問,例如多跳問答,意圖不確定,以及垂直問答等情況下的必要手段。通過把文檔中包含的內(nèi)部知識(shí)以多種方式組織,才能確保在召回結(jié)果包含所需要的答案。
c. 檢索階段分為粗篩和精排。精排通常放在數(shù)據(jù)庫(kù)外進(jìn)行,因?yàn)樗枰煌闹嘏判蚰P汀3酥猓€需要對(duì)用戶的查詢不斷改寫,根據(jù)模型識(shí)別出的用戶意圖不斷改寫查詢,然后檢索直至找到滿意的答案。
這些階段,可以說每個(gè)環(huán)節(jié)都是圍繞模型來工作的。它們聯(lián)合數(shù)據(jù)庫(kù)一起,共同保證最終問答的效果。
因此,RAG 2.0 相比 RAG 1.0 會(huì)復(fù)雜很多,其核心是數(shù)據(jù)庫(kù)和各種模型,需要依托一個(gè)平臺(tái)來不斷迭代和優(yōu)化,這就是我們開發(fā)并開源 RAGFlow 的原因。它沒有采用已有的 RAG 1.0 組件,而是從整個(gè)鏈路出發(fā)來根本性地解決 LLM 搜索系統(tǒng)的問題。當(dāng)前,RAGFlow 仍處于初級(jí)階段,系統(tǒng)的每個(gè)環(huán)節(jié),都還在不斷地進(jìn)化中。由于使用了正確的方式解決正確的問題,因此自開源以來 RAGFlow 只用了不到 3 個(gè)月就獲得了 Github 萬星。當(dāng)然,這只是新的起點(diǎn)。