













告別傳統單目視覺!Depth Anything v2超越10倍的精確深度估計!
在單目深度估計研究中,廣泛使用的標記真實圖像具有很多局限性,因此需要借助合成圖像來確保精度。為了解決合成圖像引起的泛化問題,作者團隊采用了數據驅動(大規模偽標記真實圖像)和模型驅動(擴大教師模型)的策略。同時在一個現實世界的應用場景中,展示了未標記真實圖像的不可或缺的作用,證明“精確合成數據+偽標記真實數據”比標記的真實數據更有前景。最后,研究團隊將可轉移經驗從教師模型中提煉到更小的模型中,這類似于知識蒸餾的核心精神,證明了偽標簽蒸餾更加容易和安全。
01 摘要
這項工作展示了Depth Anything V2, 在不追求技巧的情況下,該項研究的目標是為建立一個強大的單目深度估計模型奠定基礎。值得注意的是,與V1相比,這個版本通過三個關鍵實踐產生了更精細,更強大的深度預測:
●用合成圖像替換所有標記的真實圖像;
●擴大教師模型的能力;
●通過大規模偽標記真實圖像的橋梁教授學生模型。
與建立在Stable Diffusion上最新的模型相比,Depth Anything v2的模型效率更高更準確。作者提供不同規模的模型(從25M到1.3B參數),以支持廣泛的場景。得益于強大的泛化能力,研究團隊使用度量標簽對模型進行微調,以獲得度量深度模型。除了模型本身之外,考慮到當前測試集的有限多樣性和頻繁的噪聲,研究團隊構建了一個具有精確注釋和多樣化場景的多功能評估基準,以方便未來的研究。
02 工作概述
單目深度估計(Monocular Depth Estimation,MDE)因其在廣泛的下游任務中的重要作用而受到越來越多的關注。精確的深度信息不僅在經典應用中是有利的,例如3D重建,導航和自動駕駛,而且在其他生成場景中也是可應用的。
從模型建構方面來看,已有的MDE模型可以分為兩類,一類基于判別模型,另一類基于生成模型,從圖1的比較結果,Depthing Anything是更高效輕巧的。根據表1可得,Depth Anything V2可以實現復雜場景的可靠預測,包括且不局限于復雜布局、透明對象、反射表面等;在預測的深度圖中包含精細的細節,包括但不限于薄物體、小孔等;提供不同的模型規模和推理效率,以支持廣泛的應用;具有足夠的可推廣性,可以轉移到下游任務。從Depth Anything v1出發,研究團隊推出v2,認為最關鍵的部分仍然是數據,它利用大規模未標記的數據來加速數據擴展并增加數據覆蓋率。研究團隊進一步構建了一個具有精確注釋和多樣化場景的多功能評估基準。
 ▲圖1|Depthing Anything v2與其他模型比較??【深藍AI】編譯
▲圖1|Depthing Anything v2與其他模型比較??【深藍AI】編譯

▲表1|強大的單目深度估計模型的優選特性??【深藍AI】編譯
重新審視Depth Anything V1標記數據的設計,如此大量的標記圖像真的有利嗎?真實標記的數據有2個缺點:一個是標簽噪聲,即深度圖中的標簽不準確。由于各種收集程序固有的局限性,真實標記數據不可避免地包含不準確的估計,例如無法捕捉透明物體的深度,立體匹配算法以及SFM算法在處理動態物體或異常值時受到的影響。另一個是細節忽略,一些真實數據通常會忽略深度圖中的某些細節,例如樹和椅子的深度往往表示非常粗糙。為了克服這些問題,研究者決定改變訓練數據,尋找具有最好注釋的圖像,專門利用具有深度信息的合成圖像進行訓練,廣泛檢查合成圖像的標簽質量。
合成圖像具有以下優勢:
●所有精細細節都會得到正確標記,如圖2所示;
●可以獲得具有挑戰性的透明物體和反射表面的實際深度,如圖2中的花瓶。
 ▲圖2|合成數據的深度??【深藍AI】編譯
▲圖2|合成數據的深度??【深藍AI】編譯
但是合成數據仍然也具有以下局限性:
●合成圖像與真實圖像之間存在分布偏差。盡管當前的圖像引擎力求達到照片級逼真的效果,但其風格和顏色分布與真實圖像仍存在明顯差異。合成圖像的顏色過于“干凈”,布局過于“有序”,而真實圖像則包含更多隨機性;
●合成圖像的場景覆蓋范圍有限。它們是從具有預定義固定場景類型的圖形引擎迭代采樣的,例如“客廳”和“街景”。
因此在MDE中,從合成圖像到真實圖像的遷移并非易事。為了緩解泛化問題,一些工作使用真實圖像和合成圖像的組合訓練集,但是真實圖像的粗深度圖對細粒度預測具有破壞性。另一個潛在的解決方案是收集更多的合成圖像,但是這是不可持續的。因此,在本文中,研究者提出一個路線圖可以在不進行任何權衡的情況下解決精確性和魯棒性困境,并且適用于任何模型規模。
 ▲圖3|對不同視覺編碼器在合成到真實轉換方面的定性比較??【深藍AI】編譯
▲圖3|對不同視覺編碼器在合成到真實轉換方面的定性比較??【深藍AI】編譯
研究團隊提出的解決方案是整合未標記的真實圖像。團隊最強大的MDE模型基于DINOV2-G,最初僅使用高質量合成圖像進行訓練,然后它在未標記的真實圖像上分配偽深度標簽,最后僅使用大規模且精確的偽標記圖像進行訓練。Depth Anything v1凸顯了大規模無標記真實數據的重要性。針對合成標記圖像的缺點,闡述整合未標記真實圖像的作用:
●彌補差距:由于分布偏移,直接從合成訓練圖像轉移到真實測試圖像具有挑戰性。但是如果可以利用額外的真實圖像作為中間學習目標,這個過程將更加可靠。直觀地講,在對偽標記真實圖像進行明確訓練后,模型可以更熟悉真實世界的數據分布。與手動注釋的圖像相比,自動生成的偽標簽細粒度和完整度更高。
●增強場景覆蓋率:合成圖像的多樣性有限,沒有包含足夠的真實場景。然而可以通過合并來自公共數據集的大規模未標記圖像輕松覆蓋大量不同的場景。此外,由于合成圖像是從預定義視頻中重復采樣的,因此確實非常冗余。相比之下,未標記的真實圖像清晰可辨,信息量豐富。通過在足夠的圖像和場景上訓練,模型不僅表現出更強的零樣本MDE能力,而且還可以作為下游相關任務更好的訓練源。
●將經驗從最強大的模型轉移到較小的模型:如圖5所示,較小的模型本身無法直接從合成到真實的遷移中受益。然而,有了大規模未標記的真實圖像,可以學習模仿更強大的模型的高質量預測,類似于知識蒸餾。
03 關鍵技術
 ▲圖4|Depth Anything v2??【深藍AI】編譯
▲圖4|Depth Anything v2??【深藍AI】編譯
3.1 整體框架
基于以上分析,訓練Depth Anything v2的流程如下:
●基于高質量合成圖像訓練基于DINOv2-G的可靠教師模型;
●在大規模未標記的真實圖像上產生精確的偽深度;
●在偽標記的真實圖像上訓練最終的學生模型,實現穩健的泛化。
研究團隊發布4種學生模型,分別基于DINOv2的小型,基礎,大型和巨型模型。
3.2 細節
如表2所示,使用5個精確合成的數據集和8個大規模偽標記真實數據集進行訓練。與V1相同,對于每個偽標記樣本,忽略top-n-largest-loss最大區域,n設為10%。同時,模型可以產生仿射不變的逆深度,因為模型使用2個損失項對標記圖像進行優化,分別是平移不變損失和梯度匹配損失。其中梯度匹配損失在使用合成圖像時,對深度清晰度優化非常有效。在偽標記圖像上,遵循V1添加額外的特征對齊損失,以保留來自預訓練的DINOv2編碼器的信息語義。
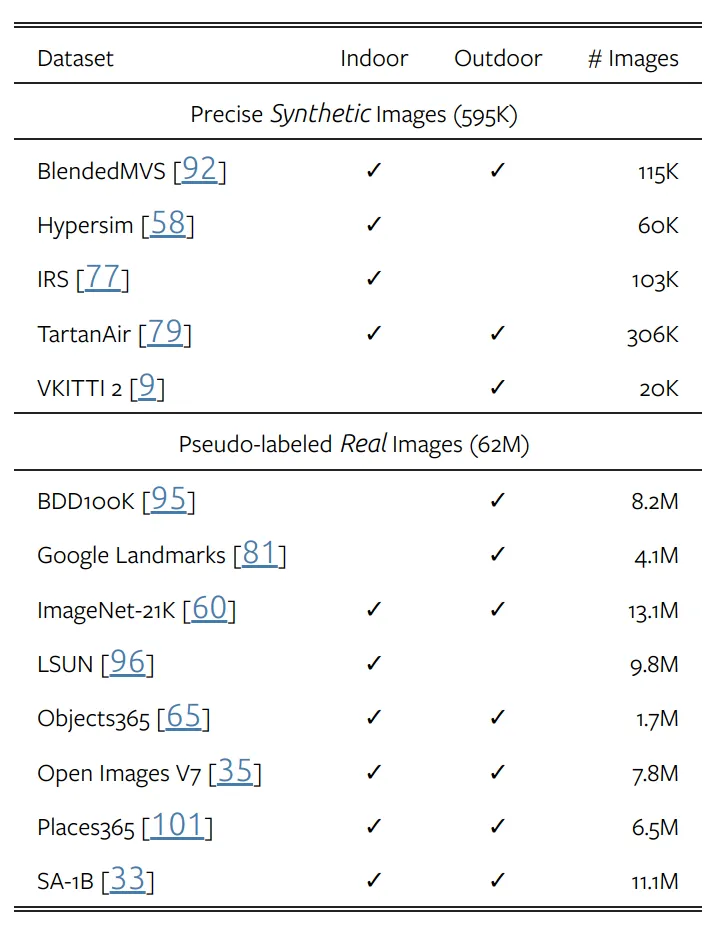
▲表2|訓練數據集??【深藍AI】編譯
3.3 DA-2K
考慮到已有噪聲數據的限制,該研究的目標是構建一個通用的相對單目深度估計評估基準。該基準可以:
●提供精確的深度關系;
●覆蓋廣泛的場景;
●包含大多數適合現代使用的高分辨率圖像。
事實上,人類很難標注每個像素的深度,尤其是對于自然圖像,因此研究員為每個圖像標注稀疏深度。通常,給定一幅圖像,可以選擇其中的2個像素,并確定它們之間的相對深度。
 ▲圖5|DA-2K??【深藍AI】編譯
▲圖5|DA-2K??【深藍AI】編譯
具體來說,可以采用2個不同的管道來選擇像素對。在第一個管道中,如圖5(a)所示,使用SAM自動預測對象掩碼。但是可能存在模型預測的情況,引入第二個管道,仔細分析圖像并手動識別具有挑戰性的像素對。DA-2K并不能取代當前的基準,它只是作為準確密集深度的先決條件。
04 實驗
與Depth Anything v1一樣,使用DPT作為深度解碼器,并且基于DINO v2編碼器構造。所有圖像均裁剪到518進行訓練,在合成圖像上訓練教師模型時,使用64的批處理大小進行160k次迭代。在偽標記真實圖像上訓練的第三階段,該模型使用192的批處理大小進行480k次迭代。使用Adam優化器,分別將編碼器和解碼器的學習率設置為5e-5和5e-6。
 ▲表3|零樣本深度估計??【深藍AI】編譯
▲表3|零樣本深度估計??【深藍AI】編譯
 ▲表4|DA-2K評估基準上的性能??【深藍AI】編譯
▲表4|DA-2K評估基準上的性能??【深藍AI】編譯
如表3所示,結果優于MiDaS,稍遜于V1。然而,v2本身是針對薄結構進行細粒度預測,對復雜場景和透明物體進行穩健預測。這些維度的改進無法正確反映在當前的基準測試中。而在DA-2K的測試上,即使是最小的模型也明顯優于其他基于SD的大模型。提出的最大模型在相對深度辨別方面的準確率比Margold高出10.6%.
 ▲表5|將Depth Anything V2預訓練編碼器微調至域內度量深度估計,即訓練和測試圖像共享同一域。所有比較方法都使用接近ViT-L的編碼器大小??【深藍AI】編譯
▲表5|將Depth Anything V2預訓練編碼器微調至域內度量深度估計,即訓練和測試圖像共享同一域。所有比較方法都使用接近ViT-L的編碼器大小??【深藍AI】編譯
如表5所示,將編碼器轉移到下游的度量深度估計任務上,在NYU-D和KITTI數據集上都比之前的方法取得了顯著改進,值得注意的是,即使是最輕量級的基于ViT-S的模型。
 ▲表6|偽標記真實圖像上的重要性??【深藍AI】編譯
▲表6|偽標記真實圖像上的重要性??【深藍AI】編譯
如表6所示,消融實驗證明了大規模偽標記真實圖像的重要性。與僅使用合成圖像進行訓練相比,模型通過結合偽標記真實圖像得到了極大的增強。
05 總結與未來展望
在本研究中,作者提出了Depth Anything v2,一種更強大的單目深度估計基礎模型。它能夠:
●提供穩健且細粒度更大的深度預測;
●支持具有各種模型大小(從25M到1.3B參數)的廣泛應用;
●可輕松微調到下游任務,可以作為有效的模型初始化。
研究團隊揭示了這項關鍵發現,此外,考慮到現有測試集中多樣性弱,噪聲強的特點,團隊構建了一個多功能評估基準DA-2K,涵蓋具有精確且具有挑戰性的稀疏深度標簽的各種高分辨率圖像。
























