萬億token!史上最大多模態(tài)數(shù)據(jù)集誕生

值此 Llama 3.1 占領(lǐng)各大頭條之際,又突然冒出了另一個也非常重要的發(fā)布 —— 一個規(guī)模空前的開源多模態(tài)數(shù)據(jù)集。
對大模型來說,數(shù)據(jù)集的重要性無需多言,甚至可以說沒有大型數(shù)據(jù)集就不可能有大模型。現(xiàn)在正是多模態(tài)大模型(LMM)發(fā)展正盛的時候,規(guī)模足夠大的優(yōu)質(zhì)且開源的多模態(tài)數(shù)據(jù)集已經(jīng)成為該領(lǐng)域的一大「剛需」。
不過,相比于開源的文本數(shù)據(jù)集,現(xiàn)有的開源多模態(tài)數(shù)據(jù)集都比較小、多樣性也不足,并且來源基本都是 HTML 文檔 —— 這就限制了數(shù)據(jù)的廣度和多樣性。這無疑限制了開源 LMM 的發(fā)展,讓開源 LMM 與閉源 LMM 之間的差異變得非常大。
近日,華盛頓大學(xué)、Salesforce Research 和斯坦福大學(xué)等機構(gòu)的聯(lián)合團隊填補了這一空白,構(gòu)建了一個萬億 token 級的交織多模態(tài)的開源數(shù)據(jù)集 MINT-1T(Multimodal INTerleaved)。毫無疑問,這是目前最大的開源多模態(tài)數(shù)據(jù)集。

- 數(shù)據(jù)集地址:https://github.com/mlfoundations/MINT-1T
- 論文地址:https://arxiv.org/abs/2406.11271
- 論文標(biāo)題:MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
MINT-1T 共包含一萬億文本 token 和三十億張圖像,并且其有 HTML/PDF/ArXiv 等多種不同來源。在 MINT-1T 問世之前,該領(lǐng)域最大的開源數(shù)據(jù)集是 OBELICS,其包含 1150 億文本 token 和 3.53 億張圖像,并且來源只有 HTML。圖 1 比較了這些數(shù)據(jù)集。

數(shù)據(jù)集的構(gòu)建
首先,該團隊從多樣化的來源(包括 HTML、PDF、ArXiv)收集了大量多模態(tài)數(shù)據(jù),圖 2 展示了這些不同來源的多模態(tài)文檔樣本。

然后,為了提高數(shù)據(jù)質(zhì)量和安全性,他們執(zhí)行了文本質(zhì)量過濾、圖像過濾、安全過濾(包括去除 NSFW 圖像和可識別個人身份的信息)以及去重。圖 3 簡要展示了這些數(shù)據(jù)過濾過程。
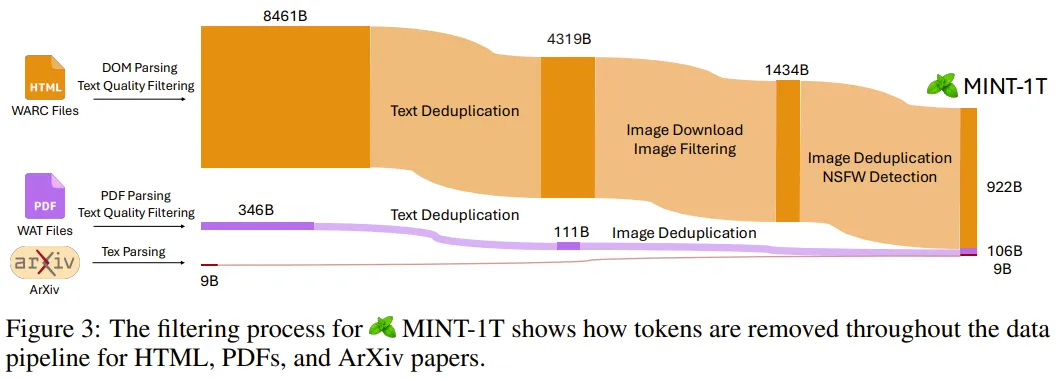
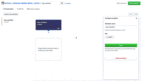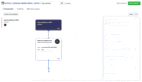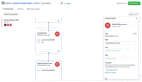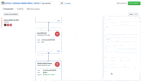
最終,他們得到的 MINT-1T 數(shù)據(jù)集包含 9220 億 HTML token、1060 億 PDF token 和 90 億 ArXiv token。值得注意的是,整個數(shù)據(jù)處理過程耗費了大約 420 萬 CPU 小時數(shù)。表 1 對比了一些常見的開源或閉源多模態(tài)數(shù)據(jù)集。

模型實驗
該團隊也實驗了使用該數(shù)據(jù)集訓(xùn)練多模態(tài)模型的效果,并與其它數(shù)據(jù)集進行了比較。
他們使用的模型架構(gòu)是 Salesforce 的 XGen-MM,評估的則是模型在數(shù)據(jù)集上學(xué)習(xí)之后的上下文學(xué)習(xí)和多圖像推理能力。評估基準(zhǔn)包括:視覺描述基準(zhǔn)(COCO 和 TextCaps)、視覺問答基準(zhǔn)(VQAv2、OK-VQA、TextVQA 和 VizWiz)、多圖像推理基準(zhǔn)(MMMU 和 Mantis-Eval)。
實驗結(jié)果
在 HTML 文檔上訓(xùn)練
該團隊首先對比了 MINT-1T 的 HTML 部分與 OBELICS;因為 OBELICS 是之前領(lǐng)先的多模態(tài)數(shù)據(jù)集并且也是基于 HTML 文檔,他們基于這兩個數(shù)據(jù)集分別用 100 億多模態(tài) token 訓(xùn)練了兩個模型,并評估了它們的上下文學(xué)習(xí)性能。
表 2 給出了在常見基準(zhǔn)上的 4-shot 和 8-shot 性能。

可以看到,對于 VQA(視覺問答)任務(wù),在 MINT-1T HTML 文檔上訓(xùn)練的模型表現(xiàn)優(yōu)于在 OBELICS 訓(xùn)練的模型,但前者在視覺描述任務(wù)上表現(xiàn)更差一些。平均而言,OBELICS 比 MINT-1T (HTML) 略好一點。
添加 PDF 和 ArXiv 文檔
之后,該團隊又在 MINT-1T 全數(shù)據(jù)集上進行了測試,即同時包含 HTML、PDF 和 ArXiv 文檔。他們通常采樣了 100 億多模態(tài) token,其中 50% 來自 HTML、45% 來自 PDF、5% 來自 ArXiv。
結(jié)果同樣見表 2,可以看到在 MINT-1T 混合數(shù)據(jù)上訓(xùn)練的模型在大多數(shù)基準(zhǔn)上都優(yōu)于在 OBELICS 和 MINT-1T (HTML) 上訓(xùn)練的模型。
而在更為復(fù)雜的多模態(tài)推理任務(wù)上,如表 3 所示,用 MINT-1T 訓(xùn)練的模型在 MMMU 上優(yōu)于用 OBELICS 訓(xùn)練的模型,但在 Mantis-Eval 基準(zhǔn)上不及后者。

更細(xì)粒度的測試和模型架構(gòu)的影響請參考原論文。
這個超大規(guī)模的開源多模態(tài)數(shù)據(jù)集能否成為一系列傳奇的起點,最終造就一個類似 Llama 系列模型那樣的多模態(tài)大模型系列呢?讓我們拭目以待吧。