DeepMind研究成本大起底,一篇ICML論文燒掉1290萬美元
發(fā)一篇頂會論文,需要多少實驗預算?
最近,DeepMind發(fā)表了一項研究,對LLM擴大規(guī)模時各種算法和架構細節(jié),比如參數(shù)和優(yōu)化器的選擇,進行了廣泛的實證調查。
這篇論文已被ICML 2024接收。

論文地址:https://arxiv.org/abs/2407.05872
63頁的論文涵蓋了數(shù)以萬計的模型,備選方案包括3種優(yōu)化器、4種參數(shù)化方案、幾種對齊假設、十多個學習率,以及最高達26.8B的14種參數(shù)規(guī)模。

需要進行實驗的4種參數(shù)化方案
僅僅聽到這些數(shù)字,就不難知道,這項研究必定涉及海量的模型運行實驗。
而有一位忠實讀者,為了測試自己對論文內容的理解,統(tǒng)計了其中進行的所有實驗,并估算出了復現(xiàn)論文的成本。

將所需算力全部加在一起,林林總總,居然達到了驚人的1290萬美元。
考驗基本功的時刻到了,假如你是研究團隊的leader,根據實驗計劃對所需算力和成本進行預估是一項必不可少的技能。
那就讓我們跟著這篇博客文章盤一遍,這一千多萬美元,究竟燒在哪里。
Transformer架構信息
論文附錄C提供了關于模型算法和架構的各種細節(jié)設置,比如使用decoder-only架構、層歸一化、GeLU激活函數(shù)、無dropout、T5分詞器、批大小為256、用FSDP并行等等。

實驗模型的參數(shù)規(guī)模統(tǒng)計
通過架構方面的信息,我們可以大致估算出訓練中每個token所需的FLOPS,記為M。
由于論文沒有描述到任何GQA/MQA機制,所以就假設Rkv=1,此外還有l(wèi)seq=512,Dhead=128,L=8(深度),V=32101(分詞器詞匯量)。
模型總參數(shù)量可以表示為:

因此,就可以得到M的計算公式:

默認情況下,每次實驗處理的token數(shù)(tokens per experiment, TPE)為5k(訓練步數(shù))×256(批大小)×512(lseq),約為6.5536e9。
def M(d: int, L=8, l_seq=512, V=32101) -> int:
return 6*d * (L*(12*d + l_seq) + V)
TPE = 50000 * 256 * 512對齊實驗
假設對齊實驗中,直接使用了后面的學習率掃描得出的最優(yōu)結果,并沒有單獨進行學習率掃描,因此這一步的成本計算比較簡單:

def alignment() -> int:
return 4 * TPE * sum(M(d) for d in [1024,2048,4096])
# >>> f'{alignment():.3E}'
# '3.733E+20'
# >>> cost_of_run(alignment())[0]
# 888.81395400704如果H100每運行1小時的花費以3美元計算,對齊實驗的成本大致為888美元。
學習率
子問題:最佳評估損失(eval loss)實驗
論文的表E1記錄了6種模型規(guī)模下,所有可能的優(yōu)化器×參數(shù)化方案×模型大小×實驗設置的組合,分別進行基礎學習率掃描,以獲得最佳評估損失。

總共包括如下幾個實驗變量:
- 模型維度D∈3072,4096,6144,8192,12288,16384
- 4種參數(shù)化方案
- 3種優(yōu)化器,其中SGD僅有5個實驗設置,Adam和Adam+Param Scaling有7個實驗設置
假設這里的實驗都是單獨進行,沒有從其他地方復制結果,因此如果全部運行一遍,有成本上限預估:

H = [1,2,4,6,8,12,16,20,24,32,48,64,96,128]
D = [h * 128 for h in H]
def table_e1() -> int:
sets_x_optims = 5 + 7 + 7
return 4 * sets_x_optims * TPE * sum(M(d) for d in D[-6:])
# >>> f'{table_e1():.3E}';cost_of_run(table_e1())
# '1.634E+23'
# (388955.9991064986, 16206.499962770775)這部分的成本就接近40萬美元,雖然仍屬于可接受范圍內,但對于大多數(shù)學術預算來說,已經算是非常昂貴了。
表E1給出了最佳評估損失,但沒有描述LR的掃描策略,每張圖上的點數(shù)也不盡相同。

由于沒有得到論文作者的答復,我們也無法確定具體機制,因此假設每個最佳評估損失都經過了15次實驗(目測發(fā)現(xiàn),每條線的點數(shù)約為10~15)。
β參數(shù)
根據論文4.2節(jié)內容,學習率還涉及到兩個超參數(shù)的選擇:β和γ。

如果僅有β參數(shù),則被稱為「LR+default」設置:

這部分包括3×優(yōu)化器,4×參數(shù)化,加上全局和單層(GlobalLR、Perlayer-fullalign)分別進行實驗,以及未知的LR掃描數(shù)量:

def beta_only() -> int:
return 3*4*2*PpL * TPE * sum(M(d) for d in D)
# 7.988E+23 (1902022.3291813303, 79250.93038255542)從公式就可以看出,成本和下文的epsilon實驗類似,都是200萬美元。
γ參數(shù)
相比β參數(shù)的實驗,這部分有兩個細節(jié)差異。
首先,除了GlobalLR、Perlayer-fullalign兩種設置外,還需要加上Perlayer-noalign設置。

其次,僅針對d=1024=b,進行3D超參數(shù)搜索(γ_1,γ_h,γ_L+1),因此有額外的800次運行。

兩者結合后的計算公式為:

這部分的預估成本與Adam的epsilon熱力圖實驗接近,約為320萬美元。
def gamma_expts() -> int:
return 36*TPE * (800*M(1024) + PpL*sum(M(d) for d in D))
# gamma_expts 1.354E+24 (3224397.534237257, 134349.8972598857)Adam優(yōu)化器的Epsilon參數(shù)
論文4.3節(jié)所述的Epsilon參數(shù)實驗是計算量的大頭。


根據上面的推斷,每次找到最佳評估損失時都嘗試過15個不同的學習率(points per line),那么圖6所示的epsilon參數(shù)變化圖耗費的計算量為:

計算結果透露出一種簡潔的昂貴,也就是200萬美元的賬單而已。
PpL = 15 # unprincipled estimate
def eps_variants() -> int:
return 4 * 6 * PpL * TPE * sum(M(d) for d in D)
'''
>>> f'{eps_variants():.3E}';cost_of_run(eps_variants())
'7.988E+23'
(1902022.3291813303, 79250.93038255542)
'''除了圖6左側的折線圖,還有附錄F熱力圖的結果。

假設每個方塊值都是經過13次學習率掃描后得到的結果,這部分計算量則為:

結果發(fā)現(xiàn),僅僅要得到這8張熱力圖,成本就是320萬美元。而且,由于我們將LR掃描數(shù)量建模為常數(shù)13,這個數(shù)字可能低于實際成本。
def eps_heatmaps() -> int:
# eps-type * eps-val * parameterizations * LR range * ...
return 2 * 6 * 4 * 13 * TPE * sum(M(d) for d in D[-6:])
'''
>>> f'{eps_heatmaps():.3E}';cost_of_run(eps_heatmaps())
'1.341E+24'
(3193533.466348094, 133063.89443117057)
'''權重衰減
權重衰減實驗(附錄G)比較好理解,對4×參數(shù)化方案以及所有參數(shù)進行一次基本的LR掃描:

比epsilon實驗便宜不少,也就是灣區(qū)工程師一年的工資——31.7萬美元。
def weight_decay() -> int:
return 4 * PpL * TPE * sum(M(d) for d in D)
'''
>>> f'{weight_decay():.3E}'; cost_of_run(weight_decay())
'1.331E+23'
(317003.7215302217, 13208.488397092571)
'''Adafactor優(yōu)化器
這部分實驗在附錄C3中有詳細描述,是為了檢驗Adafactor和Adam+parameter scaling是否有相似的寬度縮放機制。

共有2×4張圖,其中每個優(yōu)化器收集11個數(shù)據點,因此計算公式為:

賬單上再加18.8萬美元。
def adafactor() -> int:
return 2*2*4*PpL*TPE*sum(M(d) for d in D[:11])
'''
>>> f'{adafactor():.3E}'; cost_of_run(adafactor())
'7.918E+22'
(188532.80765144504, 7855.533652143543)
'''計算最優(yōu)化
論文嘗試改變注意力頭H的數(shù)量,希望找到計算最優(yōu)化的設置,但其中涉及步長和數(shù)據集的改變,因此這部分不使用公式描述,計算代碼如下:
def P(d: int, L=8, V=32101) -> int:
return 2 * d * (6*L*d + V)
def compute_optimal():
indices_50k = (14, 14, 12)
return 4*PpL*sum([
TPE * sum(sum( M(d) for d in D[:i] ) for i in indices_50k),
20 * sum(P(d)*M(d) for d in D[:11]) *3,
])
# compute_optim 7.518E+23 (1790104.1799513847, 74587.67416464102)總結
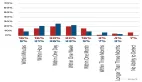
將以上各部分實驗的算力和成本匯總在一起:
alignment 3.733E+20 (888.81395400704, 37.033914750293334)
table_e1 1.634E+23 (388955.9991064986, 16206.499962770775)
eps_variants 7.988E+23 (1902022.3291813303, 79250.93038255542)
eps_heatmaps 1.341E+24 (3193533.466348094, 133063.89443117057)
beta_only 7.988E+23 (1902022.3291813303, 79250.93038255542)
gamma_expts 1.354E+24 (3224397.534237257, 134349.8972598857)
weight_decay 1.331E+23 (317003.7215302217, 13208.488397092571)
adafactor 7.918E+22 (188532.80765144504, 7855.533652143543)
compute_optim 7.518E+23 (1790104.1799513847, 74587.67416464102)結果發(fā)現(xiàn),整篇論文的運算量為5.42e24 FLOPS。
這個數(shù)字僅僅是Llama 3訓練計算量的15%,如果在10萬卡H100集群上運行,只需要2天時間即可完成所有實驗。
total_flops=5.421E+24
rental price: US$12.9M
h100 node months required: 746.9595590938408
(sanity check) D=[128, 256, 512, 768, 1024, 1536, 2048, 2560, 3072, 4096, 6144, 8192, 12288, 16384]
(sanity check) model sizes: ['0.00979B', '0.0227B', '0.058B', '0.106B', '0.166B', '0.325B', '0.534B', '0.794B', '1.1B', '1.87B', '4.02B', '6.97B', '15.3B', '26.8B']
(sanity check) M/6P: ['63.4%', '68.5%', '75.3%', '79.7%', '82.8%', '86.8%', '89.3%', '91.0%', '92.2%', '93.9%', '95.7%', '96.7%', '97.7%', '98.3%']然而,如果不從LLM預訓練的標準來衡量,僅把DeepMind的這篇論文看做一篇學術研究,這個計算量就顯得相當奢侈了。
如果實驗室僅有10張H100,就根本不可能進行這個量級的研究。
有100張H100的大型實驗室,或許能用幾年時間跑完以上所有實驗。