聊一聊遺傳算法的原理及 Python 實現
遺傳算法是一種搜索技術,它模仿自然選擇來通過迭代地改進候選解的種群來尋找最優解。

遺傳算法簡介
(1) 什么是遺傳算法?
想象一下,如果我們能夠模仿自然進化的過程來解決機器學習領域中的復雜問題。這正是遺傳算法(GAs)所做的。遺傳算法是一種基于查爾斯·達爾文自然進化理論的問題解決方法。自然選擇的過程啟發了它們。這種算法的工作方式就像自然界選擇最強壯的生物繁殖后代,以便下一代更加強壯。
(2) 為什么使用遺傳算法?
當傳統方法失敗時,遺傳算法在優化問題上非常有益。它們能夠有效地導航大型和復雜的搜索空間,使它們成為在限制條件下尋找最優解的理想工具。從演化神經網絡架構到優化超參數,遺傳算法是機器學習工具箱中的有力工具。
基因表達式編程(GEP)
(1) 什么是基因表達式編程?
基因表達式編程(GEP)是遺傳算法的一種變體,其中個體被編碼為固定長度的線性字符串,然后表達為不同大小和形狀的非線性實體。GEP在解決復雜問題方面顯示出有效性,因為它結合了遺傳算法和遺傳編程的優勢。
(2) 基因表達式編程的應用
- 符號回歸:發現最適合一組數據點的數學模型。
- 分類:開發將數據分類到預定義類別的模型。
- 時間序列預測:基于歷史數據預測未來的值。
(3) 理解遺傳優化
遺傳優化指的是使用遺傳算法解決優化問題。這個過程涉及生成一組可能的解決方案,并根據它們對定義目標的表現進行迭代改進。讓我們看看遺傳優化的實際應用。
(4) 案例研究1:神經網絡架構的優化
研究人員已經成功地將遺傳算法應用于各種研究中的神經網絡架構優化。其中一項發表在《神經計算》雜志上的研究使用遺傳算法優化了用于圖像分類的神經網絡架構。該研究在MNIST數據集上實現了97.5%的準確率,超過了傳統的優化方法。
(5) 案例研究2:遺傳編程與期權定價
在這項研究中,遺傳編程被用來演化期權定價模型(https://www.blogger.com/blog/post/edit/5963023441377516643/5687538609633287114#)。該研究比較了遺傳編程與傳統的Black-Scholes模型的性能,并發現遺傳編程在準確性和強度方面超過了傳統模型。
遺傳算法的算法
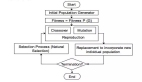
(1) 初始化
遺傳算法的第一步是生成潛在解決方案的初始種群。你可以隨機生成這個種群或使用某些策略。種群的大小是一個重要的參數,它可以影響算法的性能。
(2) 適應度函數
適應度函數是一個關鍵組件,用于評估種群中每個個體的表現。在我們推薦系統的情況下,適應度函數基于用戶參與度指標,如點擊率和用戶滿意度得分。
(3) 選擇
選擇涉及選擇表現最好的個體作為下一代的父母。最常見的選擇方法包括:
- 輪盤賭選擇:根據它們的適應度比例選擇個體。
- 錦標賽選擇:隨機選擇一組個體,然后從中選擇最好的。
- 排名選擇:根據它們的適應度對個體進行排名,然后基于這些排名進行選擇。
(4) 交叉
交叉,也稱為重組,是將兩個父解決方案合并以形成后代。常見的交叉策略包括:
- 在單點交叉中,我們選擇一個交叉點,并在父母之間交換此點前后的基因。
- 兩點交叉:選擇兩個交叉點,并交換這些點之間的基因。
- 在均勻交叉中,父母隨機交換基因。
(5) 變異
變異對個體解決方案進行隨機更改,以保持遺傳變異。變異率必須仔細平衡,以便在保留好的解決方案的同時進行適當的探索。
(6) 終止
遺傳算法重復選擇、交叉和變異的過程,直到滿足停止標準。這個標準可能是預定的代數、一定的適應度水平,或者是后代中缺乏顯著改進。
代碼示例:遺傳算法用于函數優化
(1) 適應度函數
import numpy as np
# Define the fitness function
def fitness(x):
# Maximize the function f(x) = x^2
return x**2(2) 遺傳算法參數
# Define the GA parameters
POP_SIZE = 100
GENS = 100
CROSSOVER_PROB = 0.8
MUTATION_PROB = 0.2(3) 初始種群
# Initialize the population
pop = np.random.rand(POP_SIZE)
# Evaluate the fitness of the initial population
fitness_values = np.array([fitness(x) for x in pop])(4) 選擇
parents = np.array([pop[np.argmax(fitness_values)] for _ in range(POP_SIZE//2)])(5) 交叉
offspring = []
for _ in range(POP_SIZE//2):
parent1, parent2 = parents[np.random.randint(0, len(parents), 2)]
child = (parent1 + parent2) / 2
offspring.append(child)(6) 變異
for i in range(len(offspring)): # Iterate over the correct range of offspring
if np.random.rand() < MUTATION_PROB:
offspring[i] += np.random.normal(0, 0.1)(7) 這里是完整的實現:
import numpy as np
# Define the fitness function
def fitness(x):
# Maximize the function f(x) = x^2
return x**2
# Define the GA parameters
POP_SIZE = 100
GENS = 100
CROSSOVER_PROB = 0.8
MUTATION_PROB = 0.2
# Initialize the population
pop = np.random.rand(POP_SIZE)
# Evaluate the fitness of the initial population
fitness_values = np.array([fitness(x) for x in pop])
# Main GA loop
for gen in range(GENS):
# Selection
parents = np.array([pop[np.argmax(fitness_values)] for _ in range(POP_SIZE//2)])
# Crossover
offspring = []
for _ in range(POP_SIZE//2):
parent1, parent2 = parents[np.random.randint(0, len(parents), 2)]
child = (parent1 + parent2) / 2
offspring.append(child)
# Mutation
for i in range(len(offspring)): # Iterate over the correct range of offspring
if np.random.rand() < MUTATION_PROB:
offspring[i] += np.random.normal(0, 0.1)
# Replace the population with the new offspring
pop = offspring
# Evaluate the fitness of the new population
fitness_values = np.array([fitness(x) for x in pop])
# Print the best fitness value
print(f"Generation {gen+1}, Best Fitness: {np.max(fitness_values)}")
# Print the final best solution
print(f"Final Best Solution: {pop[np.argmax(fitness_values)]}")(8) 輸出
Generation 1, Best Fitness: 1.4650152220573687
Generation 2, Best Fitness: 1.8054426063247935
Generation 3, Best Fitness: 2.1124584418178354
Generation 4, Best Fitness: 2.34514080269685
.
.
.
.
.
Generation 99, Best Fitness: 254.58556629300833
Generation 100, Best Fitness: 260.9705918019082
Final Best Solution: 16.154584234882314機器學習中的遺傳算法
(1) 為什么在機器學習中使用遺傳算法?
遺傳算法在機器學習中對于特征選擇、超參數調整和模型優化等任務很有用。它們有助于探索復雜的搜索區域,以找到傳統方法可能錯過的最優解。
(2) 超參數優化
超參數調整對于機器學習模型至關重要。遺傳算法可以高效地搜索超參數空間以找到最佳配置。例如,在訓練神經網絡時,GA可以優化學習率、批量大小和架構參數。
(3) 特征選擇
特征選擇對于提高模型性能同時最小化復雜性很重要。遺傳算法可以從大型數據集中識別最相關的特征,從而產生更準確和高效的模型。
以下是使用遺傳算法(GA)進行機器學習特征選擇的示例:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from deap import base, creator, tools, algorithms
# Load the iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Define the number of features to select
num_features = 3
# Define the fitness function
def fitness(individual):
# Select the features based on the individual
selected_indices = [i for i, x in enumerate(individual) if x == 1]
# Handle the case where no features are selected
if not selected_indices:
return 0, # Return a low fitness value if no features are selected
selected_features = np.array([X[:, i] for i in selected_indices]).T
# Create a random forest classifier with the selected features
clf = RandomForestClassifier(n_estimators=100)
# Evaluate the model using cross-validation
scores = cross_val_score(clf, selected_features, y, cv=5)
# Return the mean score as the fitness value
return np.mean(scores),
# Create a DEAP creator for the fitness function
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
# Create a DEAP toolbox for the GA
toolbox = base.Toolbox()
toolbox.register("attr_bool", np.random.choice, [0, 1])
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_bool, n=len(X[0]))
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutFlipBit, indpb=0.05)
toolbox.register("select", tools.selTournament, tournsize=3)
toolbox.register("evaluate", fitness)
# Create a population of 50 individuals
pop = toolbox.population(n=50)
# Evaluate the initial population
fitnesses = toolbox.map(toolbox.evaluate, pop)
for ind, fit in zip(pop, fitnesses):
ind.fitness.values = fit
# Run the GA for 20 generations
for g in range(20):
offspring = algorithms.varAnd(pop, toolbox, cxpb=0.5, mutpb=0.1)
fits = toolbox.map(toolbox.evaluate, offspring)
for fit, ind in zip(fits, offspring):
ind.fitness.values = fit
pop = toolbox.select(offspring, k=len(pop))
# Print the best individual and the corresponding fitness value
best_individual = tools.selBest(pop, k=1)[0]
print("Best Individual:", best_individual)
print("Best Fitness:", best_individual.fitness.values[0])
# Select the features based on the best individual
selected_features = np.array([X[:, i] for i, x in enumerate(best_individual) if x == 1]).T
# Print the selected features
print("Selected Features:", selected_features)(8) 輸出
Best Individual: [0, 0, 1, 1]
Best Fitness: 0.9666666666666668
Selected Features: [[1.4 0.2]
[1.4 0.2]
.
.
.
[5.1 1.8]]遺傳算法在現實世界中的應用
- 醫療保健:在醫療保健領域,遺傳算法用于優化治療計劃和預測疾病結果。例如,一項研究應用GA優化了癌癥患者的放射治療計劃,從而實現了更有效的治療計劃和更少的副作用。
- 金融遺傳算法:在金融領域廣泛用于投資組合優化、交易策略和風險管理。一個重要的例子是使用GA創建能夠響應市場波動的交易算法,增加回報的同時降低風險。
- 工程:GA在工程中用于優化設計參數,如空氣動力學結構的幾何形狀,以減少阻力。這一應用展示了GA在解決涉及各種限制和目標的復雜工程挑戰中的有效性。
結論
遺傳算法是機器學習中優化的強大工具。它們從自然進化中汲取靈感,高效地探索大型和復雜的搜索空間。從超參數調整到特征選擇,遺傳算法在各種應用中證明了自己的價值。