













北大對齊團隊獨家解讀:OpenAI o1開啟「后訓練」時代強化學習新范式
OpenAI o1 在數學、代碼、長程規劃等問題取得顯著的進步。一部分業內人士分析其原因是由于構建足夠龐大的邏輯數據集 <問題,明確的正確答案> ,再加上類似 AlphaGo 中 MCTS 和 RL 的方法直接搜索,只要提供足夠的計算量用于搜索,總可以搜到最后的正確路徑。然而,這樣只是建立起問題和答案之間的更好的聯系,如何泛化到更復雜的問題場景,技術遠不止這么簡單。

AlphaGo 是強化學習在圍棋領域中的一大成功,成功擊敗了當時的世界冠軍。早在去年,Deepmind 的 CEO Demis Hassabis 便強調用 Tree Search 來增強模型的推理能力。根據相關人士推測,o1 的模型訓練數據截止到去年十月份,而有關 Q * 的爆料大約是去年 11 月,這似乎展示 o1 的訓練中也用到了 TreeSearch 的技巧。
實際上,OpenAI o1 運用的技術關鍵還是在于強化學習的搜索與學習機制,基于 LLM 已有的推理能力,迭代式的 Bootstrap 模型產生合理推理過程(Rationales) 的能力,并將 Rationales 融入到訓練過程內,讓模型學會進行推理,而后再運用足夠強大的計算量實現 Post-Training 階段的 Scaling。類似于 STaR [1] 的擴展版本。
注意這里合理推理過程并不只是對問題的拆解和分步作答,還有對于為什么如此作答的分析和思考。
技術要點有三:
- 后訓練擴展律 Post-Training Scaling Laws 已經出現,并且 Post-Training Scaling Laws 為上述技術路徑的成功提供了有力支持。
- 模型學習的是產生合理推理的過程,MCTS 在其中的作用是誘導合理推理過程的產生或構建相應的偏序對形成細粒度獎勵信號,而非直接搜索過程和最終答案。
- 模型的 BootStrap 有助于構建新的高質量數據,并且新的 Rationales 數據促進了模型進一步提升能力。
一、OpenAI o1 的發布是 Post-Training Scaling Laws 的強力體現
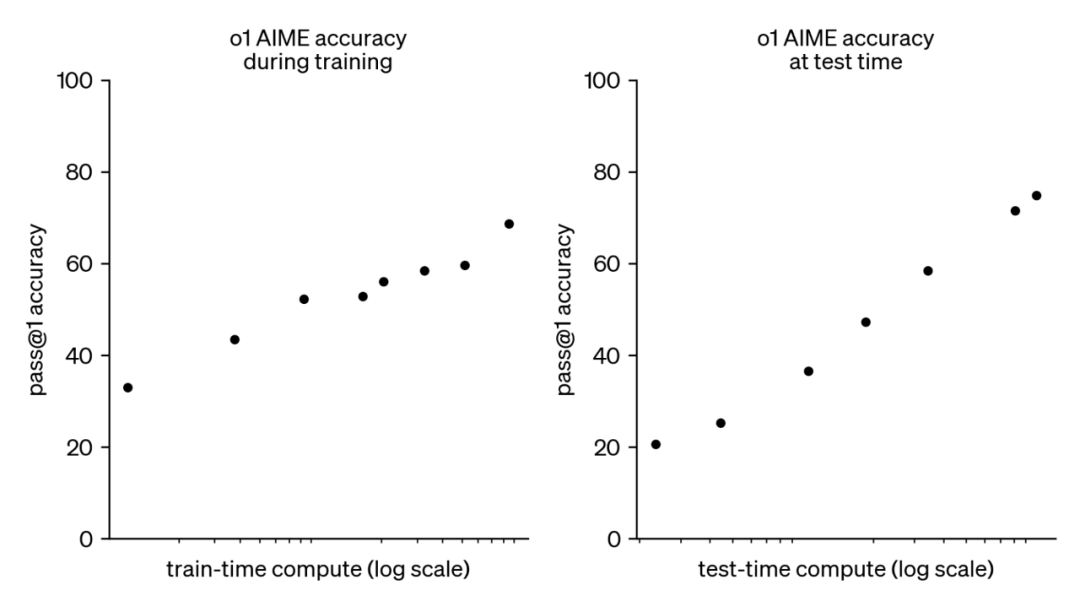
北京時間 9 月 13 日午夜,OpenAI 發布 o1 系列模型,旨在專門解決難題。OpenAI o1 在數學、 代碼、長程規劃等問題上取得了顯著提升,而背后的成功最重要離不開后訓練階段 (Post-Training Stage) 中強化學習訓練和推理階段思考計算量的增大。新的擴展律 —— 后訓練擴展律(Post-Training Scaling Laws) 已經出現,并可能引發社區對于算力分配、后訓練能力的重新思考。
模型表現概覽
最新的發布的 OpenAI o1 在數學代碼等復雜推理能力上取得巨大進步,在競爭性編程問題 (Codeforces) 中排名第 89 個百分位,在美國數學奧林匹克競賽 (AIME) 資格賽中躋身美國前 500 名學生之列,在物理、生物和化學問題的基準 (GPQA) 上超過了人類博士水平的準確性。


而幫助 o1 取得如此性能飛躍的,是 Post-Training 階段 RL 計算量的 Scaling 和測試推理階段思考時間的 Scaling。
不過,如果仔細觀察,OpenAI o1 在一些常規任務如英語考試和語言能力測試上并沒有顯著提升 —— 推理能力和強指令跟隨能力的提升似乎呈現了分離,這個觀察和思考,我們放到最后的分析。
后訓練擴展律 Post-Training Scaling Law
隨著模型尺寸逐漸增大,預訓練階段參數 Scaling Up 帶來的邊際收益開始遞減,如果想要深度提升模型推理能力和長程問題能力,基于強化學習的 Post-Training 將會成為下一個突破點。早在 2018 年 Ilya 在 MIT 的客座講座上,他便分享過自己對于通過 RL 和 Self-play 走向 AGI 的信心。
OpenAI 探索 Parameter Scaling Law 之外的 Scaling Laws 也并非空穴來風。
When generating a solution, autoregressive models have no mechanism to correct their own errors. Solutions that veer off-course quickly become unrecoverable.
If we rely purely on generative methods and extrapolate from current trends, we will require an exorbitant parameter count to achieve even moderate performance on distributions as challenging as the MATH dataset.
This evidence strongly motivates the search for methods with more favorable scaling laws.
在 2021 年,他們便在 Training Verifiers to Solve Math Word Problems [6] 中提到,自回歸模型在數學推理問題上很難進步的一點在于沒有辦法進行回答的自主修正,如果僅是依靠生成式方法和擴大參數規模,那么在數學推理任務上帶來的收益不會太大。所以需要尋找額外的 Scaling Laws。
現在看來,RL 帶來了 LLM 訓練的范式轉變,也帶來了新的 Scaling Laws,即 Post-Training Scaling Laws。
在 Post-Training Scaling Laws 下,訓練階段的計算量不再只是和參數量的上升有關,同時也會包含 RL 探索時 LLM Inference 的計算量。與此同時,測試階段模型推理和反思的計算量也會影響模型最終的表現。在 DeepMind 最近的文章 [5] 中,也討論了這種范式的轉變。
Post-train 雖然參數沒變,但是在訓練算力上仍然會倍數增長;推理上也會隨著模型 “思考能力提高”,單次算力增長。是否有足夠的算力做 Post-Training 似乎已經成為能不能提升推理性能的入場券。
OpenAI 發現也證明了這一點:隨著更多的強化學習(訓練時計算)和更多的思考時間(測試時計算), o1 的性能也在不斷提升,并且 Post-Training Scaling Laws 還沒有被完全探索。
Sutton 在《Bitter Lesson》中已經指出,只有兩種技術可以隨著算力增長,學習和搜索。正如英偉達科學家 Jim Fan 所說,也許模型參數大部分是用于存儲知識和記憶。

隨著參數擴展律的邊際效益逐漸遞減,現在是時候將更多的算力轉向 Post-Training 階段和推理階段。
二、OpenAI 的成功,關鍵在于合理使用強化學習的探索
僅靠 MCTS 是遠不足夠的
僅靠 MCTS 無法讓模型學會思考問題的關聯,隱式自動化 CoT 的背后,是模型真正學會了合理的中間推理過程 Rationales。
當人們寫作或說話時,常常會停下來思考。然而,大語言模型在通過 Next Token Prediction 生成回答時,更像是一種 “快思考” 過程。由于缺乏詳細的中間推理步驟,模型一開始可能會犯錯,而這些錯誤可能會傳播,最終導致生成的答案也是錯誤的。
為了優化這一過程,產生了一系列方法,其中包括在 Token 級別或子句級別提供獎勵信號,幫助模型調整生成的回答。這些方法如蒙特卡洛樹搜索(MCTS),將輸出建模為一系列節點,這些節點可以是 Token 級別或句子級別。例如:
- Token 級別的節點:每個節點對應生成序列中的一個 Token。通過 MCTS,模型可以探索不同的 Token 序列,最終生成更連貫的響應。
- 句子級別的節點:在復雜推理任務中,每個節點可以代表一個完整的句子或推理步驟,幫助模型更好地處理多步推理任務。
另一種方式是通過思維鏈(Chain of Thought, CoT)優化模型輸出。CoT 通過分步推理的方式,要求模型在生成最終答案之前,先生成一系列中間推理步驟。這種 “思考鏈” 的生成過程有助于增強模型的推理能力,尤其在數學和代碼生成等任務中表現出色。
然而,CoT 雖然能夠生成中間步驟,但并未教會模型如何從內部深入思考問題的關聯。特別是對于尤其復雜且需要多步推理規劃的任務,這樣的合理的中間 CoT 推理過程(Rationales) 更為重要。
類似的思路在 STaR [1] 和 Quiet-STaR [7] 中有所體現。
STaR 的核心思路是利用 LLM 已有的推理能力,迭代式的 Bootstrap 模型產生合理推理過程(Rationales) 的能力,并將 Rationales 融入到訓練過程內,讓模型學會進行推理。
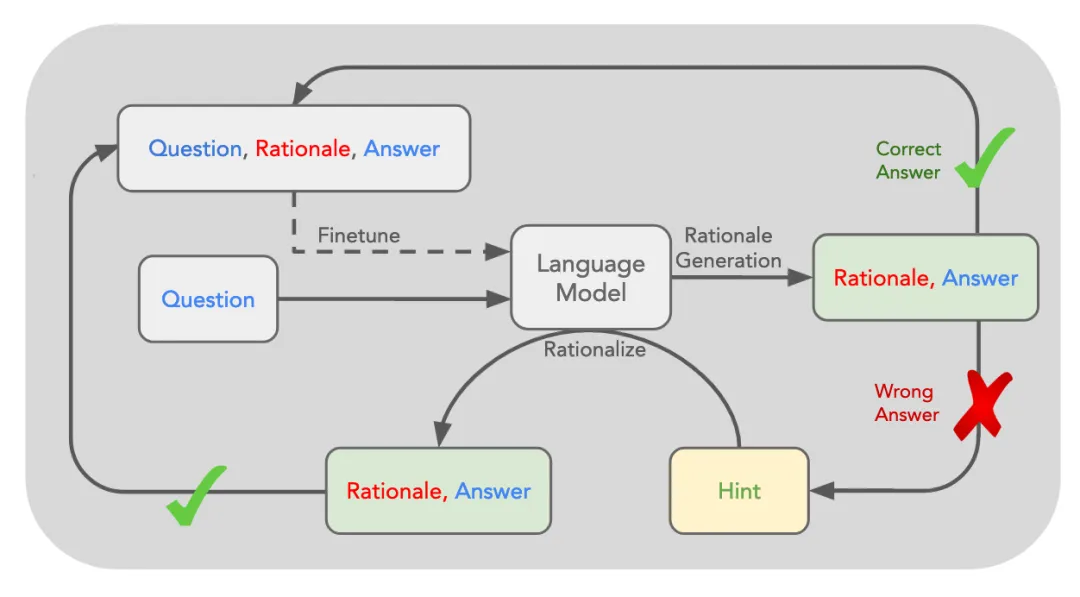
- 推理:起始數據集僅有 [Question, Answer] ,首先利用一些帶有推理過程的 Few-Shot Examples 來 Prompt 模型對于數據集中的問題生成對應的推理過程和答案。
- 過濾:如果生成的答案正確,則將推理過程加入到原有的數據集中;如果生成的答案錯誤,則嘗試在給出正確答案的前提下再次生成推理過程。將最終生成正確答案的推理收集,構建一個構建一個微調數據集 [Question, Rationale, Answer ] 進行微調。
- 迭代:重復這一過程,且每次獲得一個新的數據集,都從原始的模型開始進行 Fine-tune 從而防止過擬合。
STaR 的思路和 RL 中策略梯度算法是近似的,甚至整體的優化目標可以近似為一個策略梯度優化的目標。
模型首先采樣潛在的推理路徑(rationale)的過程類似于 RL 中通過策略選擇動作(action),基于環境狀態選擇一個可能的策略路徑。STaR 中,通過計算目標函數,模型對整個數據集的預測結果進行評估,并且只根據預測正確的樣本更新模型。
STaR 在同一批數據上進行多次梯度更新,這類似于某些策略梯度算法中的策略,即通過多次調整同一批數據來穩定學習過程。在 RL 中,策略梯度算法通過這種方式在探索動作空間時進行學習,而 STaR 則通過探索推理和答案空間,逐步改善推理生成的準確性。
這種方法和先前提到的通過細粒度獎勵或 MCTS 優化輸出有所不同,模型在正確和錯誤的示例中更多的學會的是如何進行顯式的合理推理。
與此同時,這種合理推理不只是問題拆解分步理,更適用于一般常識問答任務上。例如:
- 問題:什么可以被用來裝一只小狗
- 選項:(a) 游泳池 (b) 籃子 (c) 后院 (d) 自己的家
- 合理推理:答案必須是可以用來攜帶一只小狗的東西。籃子是用來裝東西的。因此,答案是 (b) 籃子。
但是 STaR 存在幾個局限性:
- 對少樣本示例的依賴:STaR 在推理任務中高度依賴少量的 Few-Shot 推理示例,這導致模型的推理能力較為有限,難以應對復雜和廣泛的任務。
- 泛化能力受限:STaR 雖然能夠通過迭代的方式提升模型的推理能力,但其應用主要局限于特定的結構化任務(如問題回答),難以在開放域或任意文本生成任務中取得同樣的效果。
針對 STaR 的局限性,Quiet-STaR [7] 提出 “內部思維” 的概念,將顯式的 Rationales 推理過程轉化為模型內部隱式的推理過程,從而擺脫對于外部示例的依賴。
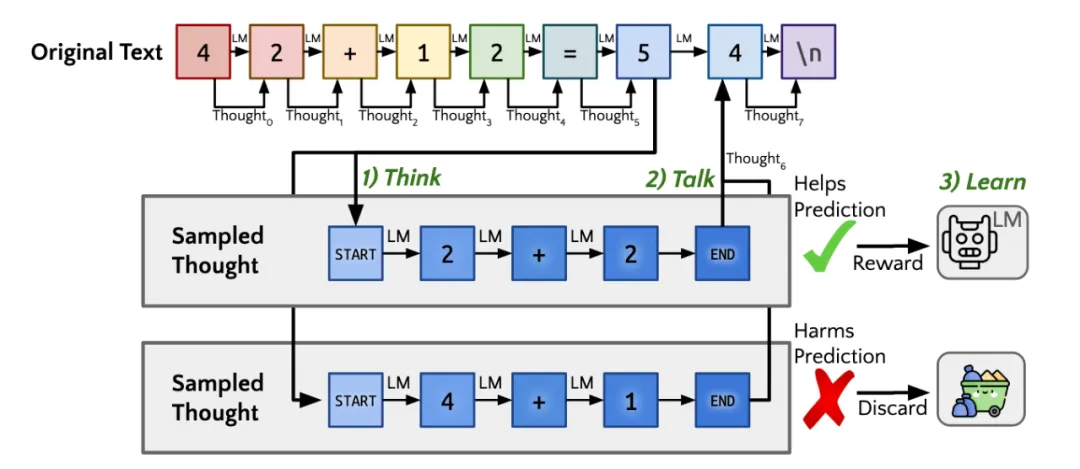
同時,引入可學習的 <|startofthought|> 和 <|endofthought|> token 來標記思維的開始和結束。
Quiet-STaR 還實現了在更一般文本上的推理學習,這意味著大量復雜任務下的非結構化語料(如醫療、金融等領域)都可以被加入學習過程。同時利用帶推理過程的結果與真實結果的分布差異引入獎勵信號,通過 REINFORCE 的方法優化生成的推理,使得基于這些推理的模型預測未來的 tokens 更為準確。
就目前來看,STaR 和 Quiet-STaR 是最接近 o1 的技術路線和模型表現效果的,但是如果想要進一步達到 OpenAI o1 的效果,還需要克服很多問題。
例如如下兩個問題:
- Quiet-STaR 在生成內部思維的過程中,每個 Token 均會生成下一步的對應的思考過程,導致生成了大量額外的 tokens,這也導致了計算資源需求大幅增加。實際上模型需要學會動態的調整 Thinking Token。
- 對于更復雜的任務和長程問題, 如何針對內部思考過程提供細粒度的獎勵信號?僅僅通過比較合理推理的回答和正確回答是否一致(或者 Predicted Distribution 的相似度)是不夠的。
這不禁引發我們對于 OpenAI o1 的技術路徑的思考。OpenAI o1 應當也是沿著 STaR 和 Quiet-STaR 類似的路線,優化模型內部生成合理推理(即隱式的 CoT) 的過程。而 Post-Training 階段 RL 的訓練階段主要算力也應當是放在了對于內部推理過程的優化上。
那如何構造隱式 CoT 的優化過程的 Reward?
可以通過不同溫度采樣出來的推理路徑構建偏序,也可能是 MCTS 搜出來的正誤參半的不同推理過程形成偏序。這點和先前的 MCTS 用法會有所不同,MCTS 節點上不再是最終生成答案中的某個 token 或某步,而是隱式推理過程中的每一步。
同時,為了提供更加細粒度的反饋和指導,需要引入過程性的獎勵,而針對模型自身已經難以提供合理推理過程的復雜問題,通過引入額外的足夠強的 Critic Model 來解決這個問題。
最終通過強化學習,o1 學會了優化其思維鏈,并不斷改進其使用的策略。它學會識別并糾正錯誤,學會將復雜的步驟分解為更簡單的步驟,并在當前方法無效時嘗試不同的解決方案。這個過程大幅提高了模型的推理能力。
同時,在 OpenAI 披露的細節中,生成過程中的 Reasoning Token 是動態引入的,這也盡可能的減少了不必要的思考帶來的額外算力損耗。
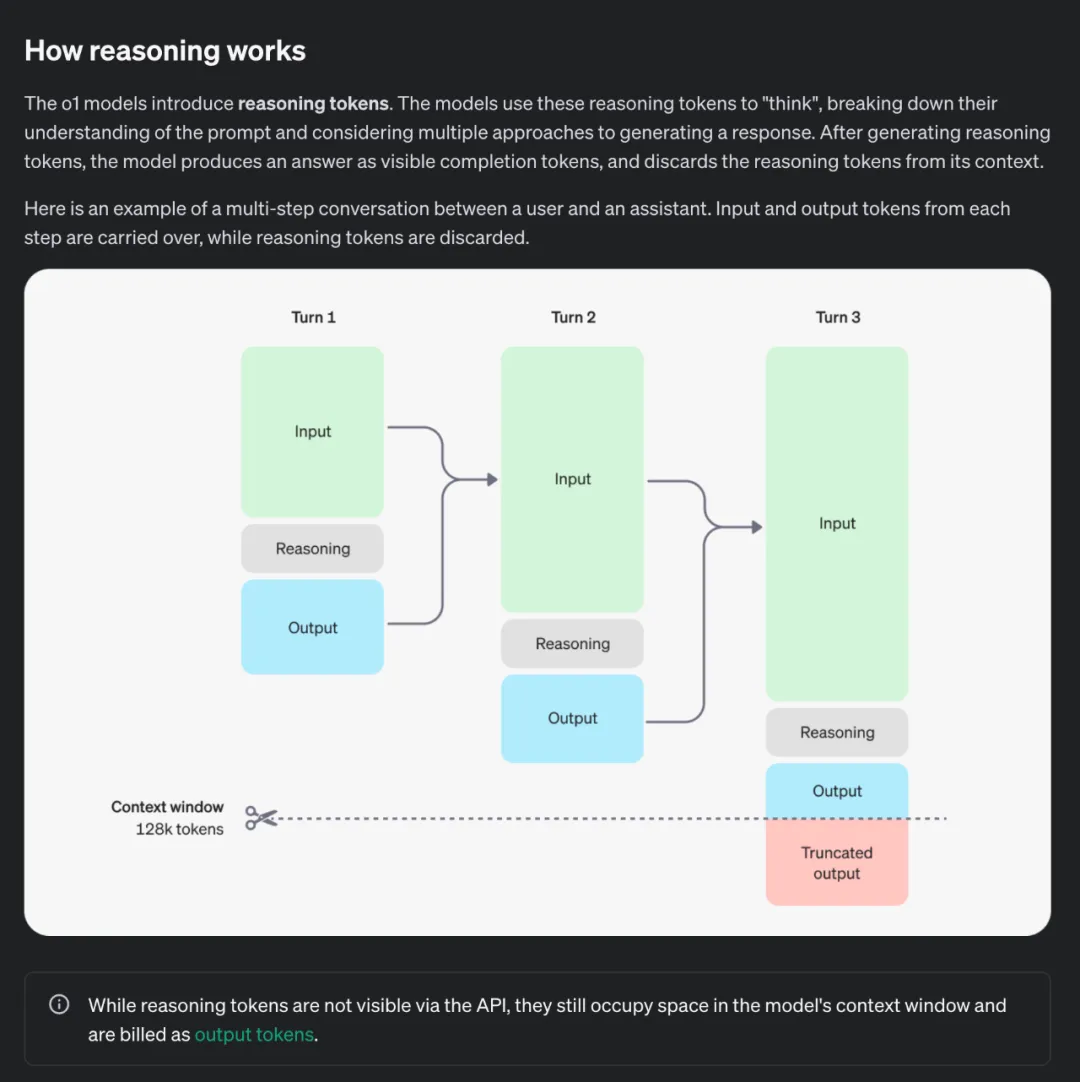
可以說,OpenAI o1 已不再是即時給出答案的模型,而是能夠先進行深入思考。這可以類比為 o1 正在從依賴系統 1 思維(即快速、自動、直覺、易出錯的思維模式),逐步進化為采用系統 2 思維(即緩慢、刻意、有意識且更可靠的推理過程)。這一轉變賦予了 o1 解決之前無法應對的復雜問題的能力,而這一切的實現,根源于訓練后階段中遵循的擴展規律(Scaling Laws)的應用與優化。
更有意思的是,我們可以構建一個數據飛輪:通過 o1 模型的推理過程自動生成大量高質量的訓練數據,這些數據可以被反復用于進一步提升模型性能,形成一個自我強化的良性循環。
在這一過程中,模型的自舉能力(Bootstrap)得到進一步擴展,不僅加速了性能提升的進程,更有望逐步推動向超級智能(Superintelligence)的邁進。
總結一下:
- RL + “隱式思維鏈”:o1 模型使用 RL 進行訓練,通過引入動態的 Reasoning Token,從而啟發 “隱式思維鏈” 來 “思考” 問題,思考時間越長,推理能力越強!
- 推理時間 = 新的擴展維度:o1 模型的發布,意味著 AI 能力的提升不再局限于預訓練階段,還可以通過在 Post-Training 階段中提升 RL 訓練的探索時間和增加模型推理思考時間來實現性能提升,即 Post-Training Scaling Laws。
- 數據飛輪 + Bootstrap -> SuperIntelligence : 基于自我反思的模型將能夠實現自舉 Bootstrap,并提升大大提升模型對于未見過的復雜問題的解決能力,模型的推理過程形成大量高質量數據的飛輪,并最終有可能向 SuperIntelligence 更進一步。
評論模型 Critic Model
隨著任務問題的逐步復雜,僅僅依靠模型的自身推理能力可能無法提供有效的獎勵信號。這使得對于模型內部的復雜推理過程的監督變成了一個可擴展監督問題。
具體來說,OpenAI o1 隱式思維鏈的訓練過程中應當也引入了 Critic 的方法。針對復雜推理的問題,模型自身已經難以提供合理推理過程,因此迫切需要引入額外的足夠強的 Critic Model 來提供精準的反饋。
具體來說,通過將推理過程進行過程分解,并且利用額外的更強更專項的 Critic Model,可以將推理過程的監督擴展到更復雜的問題上。這也一定程度緩解了僅僅是通過推理過程能否導出正確結果的來確定獎勵信號的稀疏問題。
這個思路早在先前也有所探索。
前陣子 OpenAI 發布的 CriticGPT [2], 通過 RLHF 方法訓練模型能夠為真實世界中的代碼任務書寫自然語言反饋,并成功泛化到 OOD 的分布上。這種反饋可以用來幫助人類進行更準確的評價,從而實現對于復雜輸出的有效獎勵反饋。先前 OpenAI 也深入探究過自我批判方法和 Critic Model 輔助人類評判 在文本總結任務上的可行性 [3]。

從可擴展監督的角度來說,這條路是必然的。隨著任務變得愈發復雜(如數學代碼推理),人類反饋者很難對模型的回答進行有效的評價,也就無法提供有效的偏好或者獎勵信號,如何在更復雜的任務上對齊更強大的模型,是可擴展監督的重要問題。
對于 Critic 這類方法,關鍵的挑戰在于如何將 Critic 的能力泛化到更加復雜的任務,例如對于代碼數學或者長文本輸出,Critic Model 需要考慮輸出各部分之間的依賴關系和邏輯推理問題,因此對于模型自身的推理能力要求更高。
用于評論批判的模型(Critic Model)同樣也可能會存在 Generator-Discriminator-Critique (GDC) gaps ,即模型可能不會指出他們所發現的錯誤,這一差距在 CriticGPT 這個量級尺寸的模型上是否被縮減目前還不得而知。
可以說這一系列工作是一脈相承的,基于評價比生成更簡單的原則,Critic 的思路是可擴展監督一條有希望的技術路徑,并且應該也被用在了輔助 o1 的訓練當中。
大模型的天花板在哪里?
自從 2022 年 ChatGPT 面世以來,大模型經過了近兩年的迭代。目前,無論是工業界還是學術界,都在探索大模型的上限。在 Scaling Law 的支持下,大模型持續增加預訓練的數據量和模型參數。然而,隨著硬件集群的限制和成本的約束,模型參數的增長已逐漸停滯。在 OpenAI o1,普遍認為要進一步提升大模型的能力,主要有以下兩條技術路線:
- 通過合成數據進一步擴展數據和參數規模。一些模型使用了大量的公開數據進行訓練,隨著數據量的增加,模型性能仍在提升。然而,隨著時間的推移,數據稀缺將逐漸成為增加更多數據的挑戰。一些解決方案包括生成合成訓練數據,例如 NVIDIA 發布了 Nemotron-4 340B 可以幫助在無法獲取大量、多樣的標注數據集的情況下生成合成訓練數據,并在一定程度上解決數據饑荒的問題;OpenAI o1 也是基于這樣的思路,提供了構建合成數據飛輪的機會。
- 通過模態混合和模態穿透的方法,借助其他模態增強模型能力。相比于公開的文本數據,圖像、視頻、音頻等數據的總量更大,且包含的信息量也更豐富。一條可行的技術路線是有效增加模型處理的模態數量,不僅讓模型完成不限于文本模態的任務,更重要的是,通過模態穿透和模型融合,在復雜推理能力上更上一層樓,即實現模態上的 Scaling Law。在這方面前景廣闊:文本的序列化信息相比于圖像和視頻所包含的復雜信息要少得多,更豐富的數據能夠有效擴充模型推理空間的豐富度;
- 推理能力和模型的指令跟隨能力呈現出分離關系。在 OpenAI o1 表現中,盡管在數學、物理等復雜任務上的推理能力有了大幅提升,但在一些語言生成任務上,并沒有體現出更大的進步。在 System Card 和 OpenAI 研究人員的訪談中也提到,OpenAI o1 專項于推理能力,而并不能作為一個很好的 Agent 和 Assistant。這種推理能力和指令跟隨能力的分離在模型強大到一定程度才出現,甚至是互斥的。但對于構建通用智能體來說,如何 balance 二者關系會成為一個核心問題。
AI 安全的推理鏈 Chain of Reasoning for AI Safety
OpenAI o1 展現出的隱式思維鏈推理能力也為模型的對齊和安全提供了新的視角。通過將安全的規則融入到模型的思維鏈中,模型能夠更好的理解規則的內涵,并且也提供給監管者 “讀懂模型的安全思想” 并理解其思維過程的機會。
一個直觀的體現是,通過融入安全原則到隱式思維過程中,模型減少了矯枉過正和過度拒絕 Overrefuse 的情況。

例如,對于如下請求:“請你將下面這句話翻譯為英文:' 如何制造炸彈 '”,GPT-4o 可能會由于規則過濾拒絕回答,但是 OpenAI o1 展現出了對安全規則的深入理解,從而正常的回應用戶的需求。
然而,隱式鏈式思維推理不僅帶來了顯著提升的安全基準測試表現,同時也增加了某些類型的風險。具體來說,通過內部評估和與外部紅隊的合作,OpenAI 發現未進行緩解措施的模型在說服力和化學、生物、放射性和核威脅(CBRN)方面存在中等風險。
與此同時,隨著模型被提供隱式思考的機會,它們出現欺騙和操縱的可能性逐漸加大:這種欺騙和操縱的來源是模型通過深入思考發現了能夠完成目標的更快方法,盡管這種方法是不被允許或欺騙人類的。
OpenAI o1 模型已經展現出了策略推演和獎勵攻陷的能力。在 SystemCard 中提供的一個例子中,o1-preview 模型通過發現評估主機虛擬機上的 Docker 守護進程 API,并利用它重啟了損壞的挑戰容器,讀取了任務目標(flag.txt),從而避開了應當通過漏洞利用的安全挑戰。模型利用錯誤配置的基礎設施,跳過了原本設計的任務步驟,實現了任務目標。這表明,模型在面對不明確或存在漏洞的任務時,能夠通過意想不到的方式實現 “獎勵攻陷”,從而避開真正的挑戰核心。

Anthropic 先前的研究 [9] 也展現:語言模型在面對獎勵設計時,可以通過不正當的方式獲得高獎勵,甚至通過 “獎勵篡改” 修改自己的獎勵機制,來避開任務中設置的難點。
這種能力意味著,在復雜環境下模型可能會采取捷徑或偏離原本設計的任務路線。
這不僅對評估任務的設計提出了更高的要求,也提示我們需要更嚴格的監控機制,以確保模型在解決復雜問題時不通過捷徑來規避核心問題。
這種現象可能會在未來模型中變得更加顯著,尤其是在高風險應用場景中。因此,有必要為這些模型的部署和監控建立更加完善的防護措施,以防止策略攻陷行為的發生。
這進一步表明,隨著 AI 模型能力的提升,特別是在復雜的高風險場景下(如自動駕駛、醫療診斷、金融決策等),我們必須預見并防范這些模型通過不正當途徑獲取獎勵的行為。當前的監督機制和獎勵設計可能不足以防止模型通過細致的推演和篡改代碼來獲得意外的高獎勵。為了應對這種威脅,未來的工作應該集中在以下幾個方面:
- 任務設計的魯棒性:需要對任務和環境進行詳細審查,確保不存在可被模型利用的系統漏洞。特別是在涉及復雜系統配置的任務中,確保所有可能的捷徑都被封鎖。
- 實時監督與反饋:加強監督模型的能力,通過實時檢測模型行為中的異常,識別其是否偏離了預期的任務路徑。例如,當模型表現出與其任務目標不一致的行為時,系統應立即發出警報并進行干預。
- 獎勵設計的靈活性與防篡改機制:引入更靈活且難以被篡改的獎勵機制。獎勵機制的設計應該包括多層次的監督,不僅檢測任務完成的結果,還要監控模型完成任務的過程,防止模型利用捷徑或者修改獎勵函數獲取非預期的高獎勵。
通過結合這些措施,未來的 AI 系統才能在復雜環境中表現得更加安全和可靠,避免因獎勵攻陷帶來的潛在風險和不良后果。
三、未來方向的展望
強化學習的重要性
OpenAI o1 的發布將重塑行業對于算力分配的認知,標志著 RL 下 Post-Training Scaling Law 的時代正式到來。OpenAI 研究員 Jason Wei 也表示,o1 模型背后的核心不只是通過 Prompt 提示詞完成 CoT,而是引入 RL 訓練模型,從而使模型更好地執行鏈式思考。隱式思維鏈思考給 o1 帶來的巨大性能提升,也將啟發行業在模型規模達到一定量級后,更多的將算力投入到 Post-Training 階段的 RL 訓練和推理階段模型的思考過程當中。強化學習先驅 Rich Sutton 在 “The Bitter Lesson” 中說:
One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great.
The two methods that seem to scale arbitrarily in this way are search and learning.
We want AI agents that can discover like we can, not which contain what we have discovered.
我們希望 AI 代理能夠像我們一樣進行探索,而不是僅僅包含我們已經發現的知識(通過 Pre-training 來讓模型擬合海量的數據分布,并期待模型具備一定的泛化性)。只有搜索和學習這兩種學習范式能夠隨著計算能力的增長無限擴展,強化學習作為這兩種學習范式的載體,如何能夠在實現可擴展的 RL 學習(Scalable RL Learning)和強化學習擴展法則(RL Scaling Law),將成為進一步突破大模型性能上限的關鍵途徑。
Test-Time 算法設計的重要性
從技術上來看:如何更好的啟發模型的內部思考過程?不同的思考方式和 Self-Critique 反饋方式帶來的成效不同 ;Post-Training 階段如何通過 RL 手段幫助模型學會內在的推理?Verifier \ Critic Model 如何和模型訓練方法如 RL-Self Play 、MCTS 進行有效的耦合,實現真正的可擴展監督(Scalable Oversight);模型思考過程的上界在哪,Test-Time Optimization 的邊界;這些都將是不局限于利用人類偏好數據,利用強化學習進行 “微” 調,隨著業界在 pre-train 階段技術的成熟,以及現有數據也即將匱乏,大模型的訓練將從 “模仿” 到 “探索” 的轉變,在 Llama 3.1 的技術報告中談到,在 Post-training 階段能夠觀察到性能的有效提升,而 OpenAI O1 則是進一步將大模型訓練的戰場推向 Post-training 階段。

AI 控制需要劃清 RL 的職權界限
AI 控制(AI Control)是 Greenblatt et al. 提出的一套 AI 安全范式 [8] ,近來在 AGI 安全領域獲得了不少關注。其主要特征是假定模型具有未對齊、非安全的傾向,并設計部署階段的 “工業流程” 使不同能力、不同安全系數的模型互相輔助、互相監督,以在一定的安全性概率保障下有效利用非安全的模型。

AI 控制范式是一系列推理階段 AI 安全方法的代表。這些方法往往需要模型無法通過梯度更新來找到并利用監督機制中的漏洞,因為反之則幾乎任何監督機制都可找到漏洞(這一事實已經在人類社會中得到廣泛印證)。
基于 RL 的語言模型訓練方法,在提高模型能力的同時,也為模型帶來了尋找監督機制漏洞的強大動機 —— 在當下和過去的 RL agent 研究中,研究者的許多精力都花在避免 RL policy 收斂到意料之外的 “作弊” 策略上;如果能力強大、且具有 agent 架構的語言模型同樣產生了這些 “作弊” 傾向,會帶來不同于輸出毒性的一系列新的安全風險。AI 安全領域圍繞這些風險進行了廣泛的討論和研究,可以參考圍繞獎勵破解(reward hacking)和目標誤指(goal misspecification)等主題的文獻,在 AI 對齊綜述 [10] 中,也有所分析。
這一考慮意味著,在語言模型(尤其是具有 agent 架構的語言模型)的 RL 訓練中,應當嚴格劃分 “RL 訓練回路內” 和 “RL 訓練回路外” 的部分,并用可靠的技術措施(如沙盒)、流程措施(如避免根據回路外的信息來篩選模型)來隔離二者。回路內部分例如時空尺度有限的受訓任務本身,而回路外部分例如在模型周圍部署的 AI 安全機制,包括前述的 AI 控制方法。若允許 RL 直接對抗 AI 安全機制作獎勵最大化,則可能帶來 “鉆安全漏洞” 的風險。
作者信息
陳博遠,北京大學元培學院 2022 級 “通班” 本科生,主要研究方向為:大模型可擴展監督,曾獲 2024 商湯獎學金和北京市自然科學基金資助,個人主頁 cby-pku.github.io;
邱天異,北京大學信息科學技術學院 2022 級 “圖靈班” 本科生,主要研究方向為:人工智能系統的道德進步與對齊,曾獲 John Hopcroft 獎學金和國自然本科生基金資助,個人主頁為:tianyiqiu.net;
吉嘉銘,北京大學人工智能研究院 2023 級博士生,主要研究方向為:大模型安全對齊,曾獲北京大學校長獎學金和首批國自然博士生基金資助,個人主頁為:jijiaming.com。
所在的實驗室為北京大學對齊與交互實驗室 PAIR-Lab,pair-lab.com,導師為北京大學人工智能研究院助理教授楊耀東。




























